关于常见的几种缓存算法
一次偶然的交流机会,被问到关于缓存算法的问题,结果当场蒙圈,同时也暴露了自己的不足; 结合目前的理解,也就只知道软件会结合http header头去做一些处理来控制缓存过期时间,当磁盘满后,会删除最冷的数据,至于什么是冷? 是最远的还是次数最少的? 看完下面是最常用的一些算法就会得出结论:
1. 缓存相关概念
缓存 : 凡是位于速度相差较大的两种硬件之间,用于协调两者数据传输速度差异的结构,均可称之为缓存(Cache)。
因为内存相对于硬盘读写速度更快,内存可以作为硬盘的缓存;同样的,硬盘读写速度远高于网络数据的读写速度,也可以将硬盘作为网络数据的缓存。在内存和硬盘之间,硬盘与网络之间,都存在某种意义上的Cache。
表现上,缓存载体与被缓存载体总是相对的,缓存设备成本高于被缓存设备,缓存设备速度高于被缓存设备,缓存设备容量远远小于被缓存设备。
缓存可以认为是数据的池子,是存储频繁使用的数据的临时的地方,缓存可以认为是原始数据的子集,它是从原始数据里复制出来的,并且为了能被取回,被加上了标志。
1.1.命中与回源
当用户发起一个请求,我们的应用接受这个请求,并且如果是在第一次检查缓存的时候,需要去数据库读取产品信息。如果在缓存中,一个条目通过一个标记被找到了,这个条目就会被使用、我们就叫它缓存命中。
如果没有命中缓存,就需要从原始地址获取,这个步骤叫做“回源”。回源的代价是高昂的,只有尽可能减少回源才能更好的发挥缓存的作用,但受限于缓存设备的成本,不能仅仅增加缓存容量,只能在成本和回源率之间寻求一个平衡点。
1.2.缓存未命中(Cache Miss)
如果还有缓存的空间,那么,没有命中的对象会被存储到缓存中来。
如果缓存满了,而又没有命中缓存,那么就会按照某一种策略,把缓存中的旧对象踢出,而把新的对象加入缓存池。而这些策略统称为替代策略(缓存算法),这些策略会决定到底应该踢出哪些对象。
1.3.存储成本
当没有命中时,我们会从数据库取出数据,然后放入缓存。而把这个数据放入缓存所需要的时间和空间,就是存储成本。
1.4.失效
当存在缓存中的数据需要更新时,就意味着缓存中的这个数据失效了。
2. 缓存算法
介于缓存只能够有限的使用内存,任何Cache系统都需要一个如何淘汰缓存的方案(缓存淘汰算法,等同于页面置换算法)。我们要根据自己的业务需要来选择使用何种算法来淘汰多余的数据,提高命中率。
常用的缓存算法有:
LFU(Least Frequently Used)
根据数据的历史访问频率来淘汰数据,其核心思想是“如果数据过去被访问多次,那么将来被访问的频率也更高”。
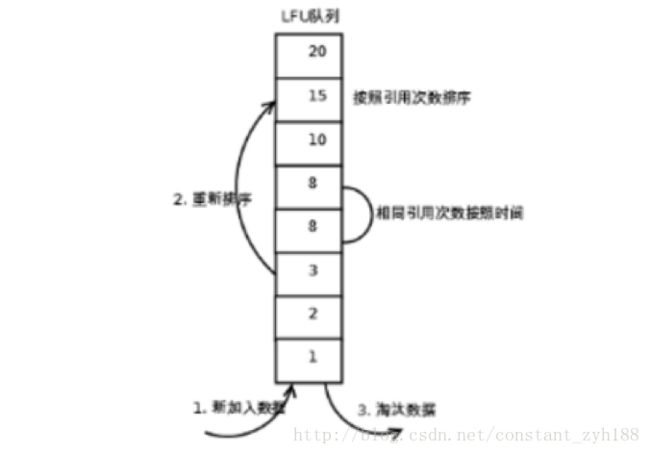
1. LFU
LFU 的每个数据块都有一个引用计数,所有数据块按照引用计数排序,具有相同引用计数的数据块则按照时间排序。具体实现如下:
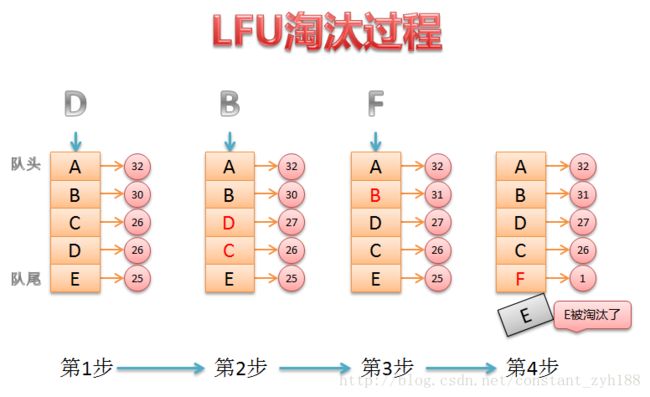
1.假设我们的lfu最大的存储空间控制为5个,此时访问D,D现在的访问频率计数是26;
2.访问D后,D的频率+1,也就是27了。 此时需要调整缓存池数据需要重新排序,D和C交换;
3.访问B,B的频率+1,由于A的频率仍然比B大,所以不需要调整;
4.当新数据F插入缓存池之前,由于已经空间满了,需要干掉一个! 因为E的频率最低,故淘汰E,将F插入缓存池,缓存池重新排序,F放到队尾.
新加入数据插入到队列尾部(因为引用计数为1)
队列中的数据被访问后,引用计数增加,队列重新排序
当需要淘汰数据时,将已经排序的列表最后的数据块删除
LRU(LeastRecently User) : 根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
1.LRU
最常见的实现是使用一个链表保存缓存数据,详细算法实现如下: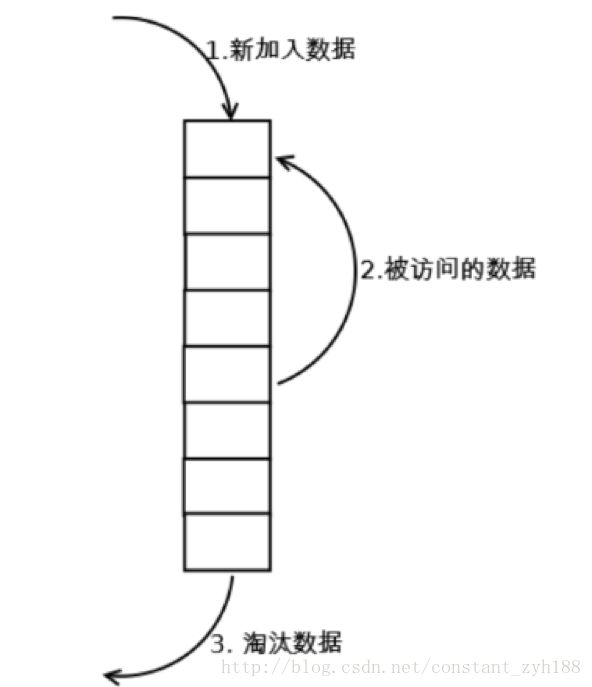
新数据插入到链表头部;
每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
当链表满的时候,将链表尾部的数据丢弃。
当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。
2.LRU-K(LeastRecently Used K)
相比LRU,LRU-K需要多维护一个队列,用于记录所有缓存数据被访问的历史。只有当数据的访问次数达到K次的时候,才将数据放入缓存。当需要淘汰数据时,LRU-K会淘汰第K次访问时间距当前时间最大的数据。详细实现如下:
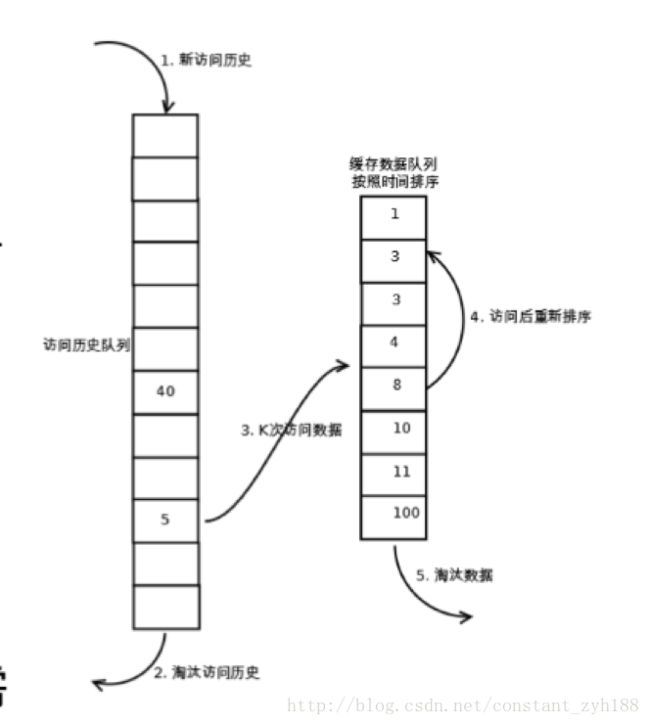
数据第一次被访问,加入到访问历史列表;
如果数据在访问历史列表里后没有达到K次访问,则按照一定规则(FIFO,LRU)淘汰;
当访问历史队列中的数据访问次数达到K次后,将数据索引从历史队列删除,将数据移到缓存队列中,并缓存此数据,缓存队列重新按照时间排序;
缓存数据队列中被再次访问后,重新排序;
需要淘汰数据时,淘汰缓存队列中排在末尾的数据,即:淘汰“倒数第K次访问离现在最久”的数据。
LRU-K中的K代表最近使用的次数,因此LRU可以认为是LRU-1。大多数情况下,LRU算法对热点数据命中率是很高的。 但如果突然大量偶发性的数据访问,会让内存中存放大量冷数据,也即是缓存污染。LRU-K的主要目的是为了解决LRU算法“缓存污染”的问题,其核心思想是将“最近使用过1次”的判断标准扩展为“最近使用过K次”。
LRU-K具有LRU的优点,同时能够避免LRU的缺点,实际应用中LRU-2是综合各种因素后最优的选择,LRU-3或者更大的K值命中率会高,但适应性差,需要大量的数据访问才能将历史访问记录清除掉。
FIFO(First inFirst out)
最先进入的数据,最先被淘汰。一个很简单的算法。只要使用队列数据结构即可实现。那么FIFO淘汰算法基于的思想是”最近刚访问的,将来访问的可能性比较大”。
2Q(Two Queues)
同样也是为了解决LRU算法的缓存污染问题。类似于LRU-2,不同点在于2Q将LRU-2算法中的访问历史队列改为一个FIFO缓存队列,即:2Q算法有两个缓存队列,一个是FIFO队列,一个是LRU队列。
当数据第一次访问时,2Q算法将数据缓存在FIFO队列里面,当数据第二次被访问时,则将数据从FIFO队列移到LRU队列里面,两个队列各自按照自己的方法淘汰数据。详细实现如下:

新访问的数据插入到FIFO队列;
如果数据在FIFO队列中一直没有被再次访问,则最终按照FIFO规则淘汰;
如果数据在FIFO队列中被再次访问,则将数据移到LRU队列头部;
如果数据在LRU队列再次被访问,则将数据移到LRU队列头部;
LRU队列淘汰末尾的数据。
注:上图中 FIFO 队列比 LRU 队列短,但并不代表这是算法要求,实际应用中两者比例没有硬性规定。