GAN生成对抗网络:数学原理
文章目录
- 1. 极大似然估计
- 2. 相对熵,KL散度
- 3. KL散度与交叉熵的关系
- 4. JS散度
- 5. GAN 框架
- 判别器的损失函数
- 生成器的损失函数
1. 极大似然估计
GAN用到了极大似然估计(MLE),因此我们对MLE作简单介绍。
MLE的目标是从样本数据中估计出真实的数据分布情况,所用的方法是最大化样本数据在估计出的模型上的出现概率,也即选定使得样本数据出现的概率最大的模型,作为真实的数据分布。
将真实模型用参数 θ \theta θ表示,则在模型 θ \theta θ下,样本数据的出现概率(likelihood)是 (1) ∏ i = 1 m p m o d e l ( x i ; θ ) \prod_{i=1}^mp_{model}(x_i; \theta) \tag{1} i=1∏mpmodel(xi;θ)(1)
其中 x i x_i xi表示样本中的第 i i i个数据。
最大化(1)式的概率,求得满足条件的 θ \theta θ:
θ ∗ = arg max θ ∏ i = 1 m p m o d e l ( x i ; θ ) = arg max θ ∑ i = 1 m log p m o d e l ( x i ; θ ) \begin{aligned} \theta^* & = \arg\max_\theta\prod_{i=1}^mp_{model}(x_i; \theta) \\ &= \arg\max_\theta\sum_{i=1}^m\log p_{model}(x_i; \theta) \\ \end{aligned} θ∗=argθmaxi=1∏mpmodel(xi;θ)=argθmaxi=1∑mlogpmodel(xi;θ)
还可以使用KL散度来代表MLE方法:
θ ∗ = arg min θ D K L ( p d a t a ( x ) ∣ ∣ p m o d e l ( x ; θ ) = arg min θ { ∑ i = 1 m p d a t a ( x i ) log p d a t a ( x i ) − ∑ i = 1 m p d a t a ( x i ) log p m o d e l ( x i ; θ ) } = − arg min θ ∑ i = 1 m p d a t a ( x i ) log p m o d e l ( x i ; θ ) = arg max θ ∑ i = 1 m p d a t a ( x i ) log p m o d e l ( x i ; θ ) \begin{aligned} \theta^*&=\arg\min_\theta D_{KL}(p_{data}(x) || p_{model}(x;\theta)\\ & = \arg\min_\theta\left\{ \sum_{i=1}^mp_{data}(x_i)\log p_{data}(x_i) - \sum_{i=1}^mp_{data}(x_i)\log p_{model}(x_i;\theta) \right\}\\ & = -\arg\min_\theta\sum_{i=1}^mp_{data}(x_i)\log p_{model}(x_i;\theta) \\ & = \arg\max_\theta\sum_{i=1}^mp_{data}(x_i)\log p_{model}(x_i;\theta) \end{aligned} θ∗=argθminDKL(pdata(x)∣∣pmodel(x;θ)=argθmin{i=1∑mpdata(xi)logpdata(xi)−i=1∑mpdata(xi)logpmodel(xi;θ)}=−argθmini=1∑mpdata(xi)logpmodel(xi;θ)=argθmaxi=1∑mpdata(xi)logpmodel(xi;θ)
在实际上,我们无法得到数据的真实分布 p d a t a p_{data} pdata,但是可以从 m m m个数据的样本中近似得到一个估计 p ^ d a t a \hat{p}_{data} p^data。
为了便于理解KL散度,我们在下面对其进行简要介绍。
2. 相对熵,KL散度
两个概率分布 P P P和 Q Q Q的KL散度定义如下:
D K L ( P ∣ ∣ Q ) = ∑ i P ( i ) log P ( i ) Q ( i ) D_{KL}(P||Q)=\sum_iP(i)\log{\frac{P(i)}{Q(i)}} DKL(P∣∣Q)=i∑P(i)logQ(i)P(i)
性质:
D K L ( P ∣ ∣ Q ) ≥ 0 D_{KL}(P||Q)\ge0 DKL(P∣∣Q)≥0
当且仅当 P = Q P=Q P=Q时,等号成立。(证明过程借用吉布斯不等式: ∑ i p i log p i ≥ ∑ i p i log q i \sum_ip_i\log p_i\ge\sum_ip_i\log q_i ∑ipilogpi≥∑ipilogqi,证明吉布斯不等式会用到关系 log x ≤ x − 1 \log x \le x - 1 logx≤x−1)
KL散度反映了两个分布 P P P和 Q Q Q的相似情况,KL散度越小,两个分布越相似。
KL散度是不对称的:
D K L ( P ∣ ∣ Q ) ≠ D K L ( Q ∣ ∣ P ) D_{KL}(P||Q) \quad\neq D_{KL}(Q||P) DKL(P∣∣Q)̸=DKL(Q∣∣P)
3. KL散度与交叉熵的关系
神经网络中常常使用交叉熵作为损失函数:
L = − ∑ i y i log h i L = -\sum_i y_i\log h_i L=−i∑yiloghi
其中 y i y_i yi是实际的标签值, h i h_i hi是网络的输出值。
我们将 y y y和 h h h的KL散度展开,得到:
D K L ( y ∣ ∣ h ) = ∑ i y i log y i h i = ∑ i y i log y i − ∑ i y i log h i = ∑ i y i log y i + L = C o n s t a n t + L \begin{aligned} D_{KL}(y||h) & = \sum_iy_i\log{\frac{y_i}{h_i}}\\ & = \sum_iy_i\log y_i - \sum_iy_i\log h_i\\ & = \sum_iy_i\log y_i + L\\ &= Constant + L \end{aligned} DKL(y∣∣h)=i∑yiloghiyi=i∑yilogyi−i∑yiloghi=i∑yilogyi+L=Constant+L
因此,最小化KL散度,等价于最小化损失函数 L L L。也即交叉熵损失函数反应的是网络输出结果和样本实际标签结果的KL散度的大小,交叉熵越小,KL散度也越小,网络的输出结果越接近实际值。
4. JS散度
对于两个分布 P P P和 Q Q Q,JS散度是:
D J S ( P ∣ ∣ Q ) = 1 2 D K L ( P ∣ ∣ P + Q 2 ) + 1 2 D K L ( Q ∣ ∣ P + Q 2 ) D_{JS}(P||Q) = \frac{1}{2}D_{KL}(P||\frac{P+Q}{2}) + \frac{1}{2}D_{KL}(Q||\frac{P+Q}{2}) DJS(P∣∣Q)=21DKL(P∣∣2P+Q)+21DKL(Q∣∣2P+Q)
JS散度是对称的,并且有界 [ 0 , log 2 ] [0, \log2] [0,log2]。
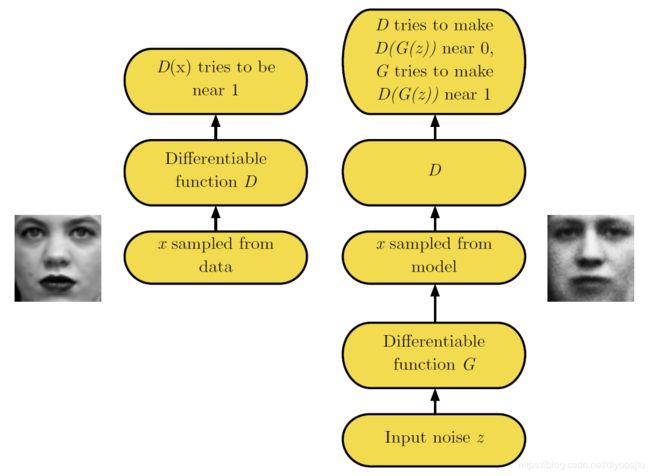
5. GAN 框架
生成器,生成与训练集数据相同分布的样本;判别器,检查生成器生成的样本是真的还是假的。
The generator is trained to fool the discriminator.
判别器的损失函数
判别器的损失函数为:
(2) J ( D ) ( θ ( D ) , θ ( G ) ) = − 1 2 E x ∼ p d a t a log D ( x ) − 1 2 E z ∼ p m o d e l log ( 1 − D ( G ( z ) ) ) J^{(D)}(\theta^{(D)}, \theta^{(G)})= -\frac{1}{2}\mathbb{E}_{x\sim p_{data}}\log D(x) - \frac{1}{2}\mathbb{E}_{z\sim p_{model}}\log (1-D(G(z)))\tag{2} J(D)(θ(D),θ(G))=−21Ex∼pdatalogD(x)−21Ez∼pmodellog(1−D(G(z)))(2)
上式其实就是一个交叉熵损失函数。GAN的判别器在训练的过程中,数据集包含两个部分,一部分是训练集的样本 x x x,对应的标签 y = 1 y=1 y=1,一部分是生成器生成的数据 G ( z ) G(z) G(z),对应的标签 y = 0 y=0 y=0,因此判别器的训练集可以看做 X = { x , G ( z ) } , Y = { 1 , 0 } X=\{x, G(z)\}, Y=\{1, 0\} X={x,G(z)},Y={1,0}。
训练集样本是 X X X,标签是 Y Y Y,网络输出是 H H H,则交叉熵损失函数为:
(3) J = 1 m ∑ i = 1 m { − Y i log H i − ( 1 − Y i ) log ( 1 − H i ) } J = \frac{1}{m} \sum_{i=1}^m\{-Y_i\log H_i - (1-Y_i)\log(1-H_i)\}\tag{3} J=m1i=1∑m{−YilogHi−(1−Yi)log(1−Hi)}(3)
与式(2)作比较,前一项的 log H \log H logH等价于式(2)中的 log D ( x ) \log D(x) logD(x),后一项的 log ( 1 − H i ) \log(1-H_i) log(1−Hi)等价于式(2)中的 log ( 1 − D ( G ( z ) ) ) \log(1-D(G(z))) log(1−D(G(z)))。将 x x x看做包含了真实样本和生成器生成的数据 G ( z ) G(z) G(z)的新的训练集,则判别器的损失函数可以重新写作:
(4) J ( D ) ( θ ( D ) , θ ( G ) ) = − 1 2 E x ∼ p d a t a log D ( x ) − 1 2 E x ∼ p m o d e l log ( 1 − D ( x ) ) = − 1 2 ∑ i p d a t a ( x i ) log D ( x i ) − 1 2 ∑ i p m o d e l ( x i ) log ( 1 − D ( x i ) ) \begin{aligned} J^{(D)}(\theta^{(D)}, \theta^{(G)}) &= -\frac{1}{2}\mathbb{E}_{x\sim p_{data}}\log D(x) - \frac{1}{2}\mathbb{E}_{x\sim p_{model}}\log (1-D(x))\\ &= -\frac{1}{2} \sum_ip_{data}(x_i)\log D(x_i) -\frac{1}{2}\sum_i p_{model}(x_i) \log (1-D(x_i)) \end{aligned}\tag{4} J(D)(θ(D),θ(G))=−21Ex∼pdatalogD(x)−21Ex∼pmodellog(1−D(x))=−21i∑pdata(xi)logD(xi)−21i∑pmodel(xi)log(1−D(xi))(4)
对上式关于 D ( x ) D(x) D(x)求导,并令导数为0,得到:
D ∗ ( x ) = p d a t a ( x ) p d a t a ( x ) + p m o d e l ( x ) D^*(x) = \frac{p_{data}(x)}{p_{data}(x)+p_{model}(x)} D∗(x)=pdata(x)+pmodel(x)pdata(x)
生成器的损失函数
令 J ( G ) = − J ( D ) J^{(G)}=-J^{(D)} J(G)=−J(D),则
J ( G ) ( θ ( D ) , θ ( G ) ) = 1 2 E x ∼ p d a t a log D ( x ) + 1 2 E z ∼ p m o d e l log ( 1 − D ( G ( z ) ) ) = C o n s t a n t + 1 2 E z ∼ p m o d e l log ( 1 − D ( G ( z ) ) ) \begin{aligned} J^{(G)}(\theta^{(D)}, \theta^{(G)}) &= \frac{1}{2}\mathbb{E}_{x\sim p_{data}}\log D(x) + \frac{1}{2}\mathbb{E}_{z\sim p_{model}}\log (1-D(G(z)))\\ & = Constant + \frac{1}{2}\mathbb{E}_{z\sim p_{model}}\log (1-D(G(z))) \end{aligned} J(G)(θ(D),θ(G))=21Ex∼pdatalogD(x)+21Ez∼pmodellog(1−D(G(z)))=Constant+21Ez∼pmodellog(1−D(G(z)))
生成器没有直接接受任何的训练集数据,训练集数据的信息是通过判别器学习后传递过来的。