1. Main Point
0x1:行文框架
- 第二章:我们会分别介绍NNs神经网络和PR多项式回归各自的定义和应用场景。
- 第三章:讨论NNs和PR在数学公式上的等价性,NNs和PR是两个等价的理论方法,只是用了不同的方法解决了同一个问题,这样我们就形成了一个统一的观察视角,不再将深度神经网络看成是一个独立的算法。
- 第四章:讨论通用逼近理论,这是为了将视角提高到一个更高的框架体系,通用逼近理论证明了所有的目标函数都可以拟合,换句话说就是,所有的问题都可以通过深度学习解决。但是通用逼近理论并没有告诉我们具体用什么模型。
- 第五章/第六章:讨论NNs和PR都存在的两个主要潜在缺陷:1)多重共线性;2)过拟合性。讨论这2个缺陷的目的是为了让我们更好的理解复杂网络的深层原理,以及解决过拟合问题的通用底层思维,通过这样的视角讨论,我们会发现,dropout和正则化并没有本质的区别,只是看问题的视角不同罢了。
- 第七章:讨论一个非常棒的学术研究成果,LIME,它提供了一种使用简单复合函数(线性函数、决策树等)来近似局部逼近深度学习模型的理论和方法,为我们更好的理解深度模型的底层逻辑提供了新的视角。
0x2:Main Academic Point
- 多项式回归PR,和神经网络NNs,在数学公式上具有近似等价性,都是是一个复合函数。
- 对于任何单变量函数,只要基函数(神经元、一元线性单元)足够多,神经网络函数就能任意逼近它。
- 对于任何多变量函数,一定可以被多个单变量函数的复合来逼近。
- NNs的学习是个数据拟合(最小二乘回归)的过程,本质上和PR的线性回归分析是一样的,拟合过程是在学习基函数的线性组合。
- 具体的NNs应用过程中,选多少层、选多少基的问题在逼近论中就是没有很好的解决方案,这是逼近论中就存在的问题,并不是深度网络带来的问题。也就是说,最优神经网络的构建问题,是需要从逼近论这个层面去突破的,单纯研究神经网络帮助并不会很大。
0x3:Main Engineering Point
- 需要选取多大的神经网络(也就是选用什么样的拟合函数)?具体地,网络要多少层?每层多少节点?这个需要根据你要解决的具体问题而定,一般来说,问题越简单,网络的自由度就要越小,而目标问题越复杂,网络的自由度就要适当放大。
- 先建立一个较小的网络来解决核心问题,然后一步一步扩展到全局问题。
- 可视化你的结果!这样有助于在训练过程中发现问题。我们应该明确的看到这些数据:损失函数的变化曲线、权重直方图、变量的梯度等。不能只看数值。
2. NNs and Polynomial Regression
这一章节,我么分别对NNs和PR进行简要介绍,为下一章节讨论它们二者之间的等价性进行一些铺垫。
0x1:Polynomial Regression(多项式回归)
1. 为什么我们需要多项式回归
2. 多项式回归形式化定义
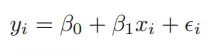
一元线性回归模型
扩展成一元多项式回归模型(degree = d)就是:
![]()
一元多项式回归模型
一般地,考虑 n 维特征(x1,x2,…,xn),d次幂的情况(n元d次幂多项式):
![]()
其中,

上式即为n元d次多项式的通用表达式,中间部分是一个排列组合公式的省略写法。
从特征向量维度的角度来看,PolynomialFeatures(degree=d)将维度为n的原始特征(n元特征)扩展到了一个维度为 的新特征空间。可以形象的理解为,将d个相同小球排成一排后,用n个隔板将其进行分割,每个隔间分配多少小球的问题,排列组合的结果为
的新特征空间。可以形象的理解为,将d个相同小球排成一排后,用n个隔板将其进行分割,每个隔间分配多少小球的问题,排列组合的结果为 种方法。
种方法。
值得注意的一点是,n元d次多项式在特征空间上具有两个主要特点:
- n元特征的权重的离散化分配
- n元特征之间的特征组合:例如当原始特征为a,b,次幂为3时,不仅仅会将a3,b3作为新特征,还会添加a2b,ab2和ab。
3. 多项式回归代码示例
# -*- coding: utf-8 -*- import matplotlib.pyplot as plt import numpy as np from sklearn.preprocessing import PolynomialFeatures from sklearn.linear_model import LinearRegression if __name__ == '__main__': # generate a random dataset np.random.seed(42) m = 100 X = 6 * np.random.rand(m, 1) - 3 y = 0.5 * X ** 2 + X + 2 + np.random.randn(m, 1) plt.plot(X, y, "b.") plt.xlabel("$x_1$", fontsize=18) plt.ylabel("$y$", rotation=0, fontsize=18) plt.axis([-3, 3, 0, 10]) plt.show() # use Scikit-Learn PolynomialFeature class to constructing parameter terms. # a,b,degree=2: [a, b, a^2, ab, b^2] # a,b,degree=3: [a, b, a^2, ab, b^2, a^3, a^2b, ab^2, b^3] # a,b,c,degree=3: [a, b, c, a^2, ab, ac, b^2, bc, c^2, a^3, a^2b, a^2c, ab^2, ac^2, abc, b^3, b^2c, bc^2, c^3] poly_features = PolynomialFeatures(degree=2, include_bias=False) # fit the dataset with Polynomial Regression Function, and X_poly is the fitting X result X_poly = poly_features.fit_transform(X) print "X: ", X print "X_poly: ", X_poly lin_reg = LinearRegression() lin_reg.fit(X_poly, y) print(lin_reg.intercept_, lin_reg.coef_) # draw the prediction curve X_new = np.linspace(-3, 3, 100).reshape(100, 1) # fit the X_new dataset with Polynomial Regression Function, and X_new_poly is the fitting X result X_new_poly = poly_features.transform(X_new) y_new = lin_reg.predict(X_new_poly) plt.plot(X, y, "b.") plt.plot(X_new, y_new, "r-", linewidth=2, label="Predictions") plt.xlabel("$x_1$", fontsize=18) plt.ylabel("$y$", rotation=0, fontsize=18) plt.legend(loc="upper left", fontsize=14) plt.axis([-3, 3, 0, 10]) plt.show()
代码中有一个细节需要注意一下,PolynomialFeatures的参数d=2,即2次幂多项式。这里之所以选2次幂是因为我们事先知道了数据集的概率分布,形状大致为一个二次函数。实际上,读者朋友可以自己修改代码,改为degree=3/4..,多项式依然可以拟合的很好,因为这个数据集中的噪声点不是很多,不容易发生过拟合。
但是在实际的工程中,数据集的维度数十万都是很正常的,我们不可能事先知道最适合的d次幂参数是多少。一个最常用的理论和方法就是设置一个相对较大的d次幂,即使用一个相对复杂的多项式函数去拟合数据,当然,d次幂参数也不能设置的过大,因为过于复杂的多项式函数会导致过拟合的发生。
Relevant Link:
https://blog.csdn.net/tsinghuahui/article/details/80229299 https://www.jianshu.com/p/9185bc96bfa9 https://blog.csdn.net/qq_36523839/article/details/82924804
0x2:Neural Nets(NNs,神经网络)
1. 单神经元(感知机)单层神经网络
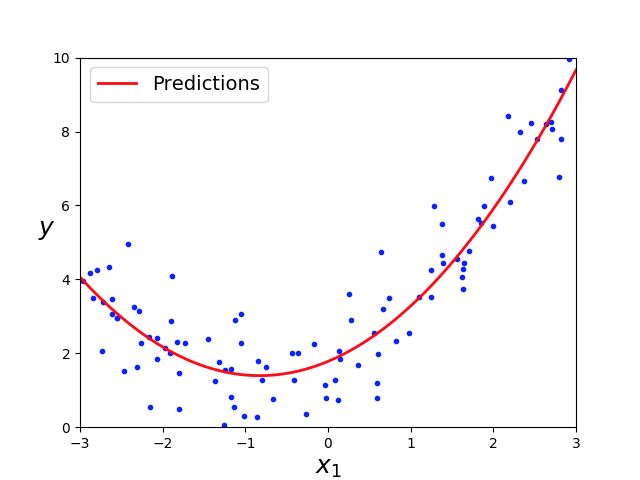
单个神经元是神经网络的最基本组成单元(1层1神经元的神经网络退化为感知机模型),单个的感知机的本质就是一个一元线性分类函数,用它可以划出一条线,把一维平面分割开:

但是,当面对更复杂的问题时,一元线性分类函数(一维平面)就无法解决了。例如”电路模拟中的XOR运算问题“。
在数字逻辑中,异或是对两个运算元的一种逻辑分析类型,符号为XOR或EOR或⊕。与一般的或(OR)不同,当两两数值相同时为否,而数值不同时为真。异或的真值表如下:
| Input | Output | |
|---|---|---|
| A | B | |
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
单层的神经元模型可以对“与/与非/或”等逻辑进行很好的模拟,但是唯独无法解决异或问题,如下图:

神经元模型对“与”、“与非”、“或”问题都可以找到一条完美的决策面。但是,对于XOR问题中的数据点,无论如何调整,都无法找到一个完美的决策面。
无法找出一条直线作为决策边界,可以使(0,0)和(1,1)在一个区域,而(1,0)和(0,1)在另一个区域。
2. 多神经元(感知机)多层神经网络
 每一个神经元都由一个感知机模型表示,使用阈值函数作为它的激活函数。比特符号0和1,分别由0和+1表示。
每一个神经元都由一个感知机模型表示,使用阈值函数作为它的激活函数。比特符号0和1,分别由0和+1表示。
该隐藏神经元构造的决策边界斜率等于-1,在下图中给出其位置:

隐藏层底部的神经元标注为“Neuron 2”,有:
![]()
隐藏元构造的决策边界方向和位置由下图给出:

我们可以看到,两个隐藏神经元已经各自完成了一半的分类任务,现在需要的是一个“复合决策函数”,将它们分类能力进行一个综合,得到原来两个隐藏神经元形成的决策边界构造线性组合。

输出层的神经元标注为“Neuron 3”,有:
![]()
底部隐藏神经元由一个兴奋(正)连接到输出神经元,而顶部隐藏神经元由一个更强的抑制(负)连接到输出神经元。这样,通过构造一个隐层(本质上是一个复合线性函数),我们成功地解决了XOR问题。

从复合线性函数的角度来分析,上图所示的神经网络等价于:
![]()
合并同类项后有:
![]()
可以看到,上式本质上是一个多元1次幂线性方程组。
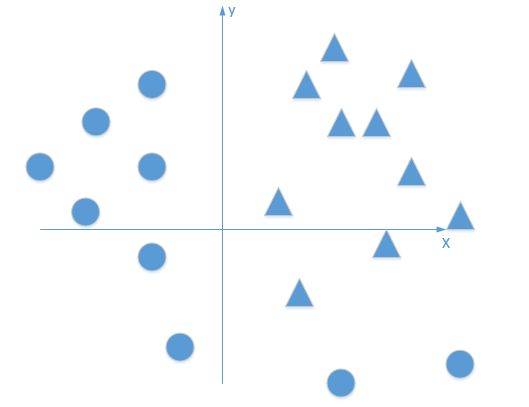

无论单条直线决策面如何调整,都是完成二分类任务
面对这种情况,就需要增加线性元的数量,改用多元复合线性函数来进行多元线性切割,如下图:
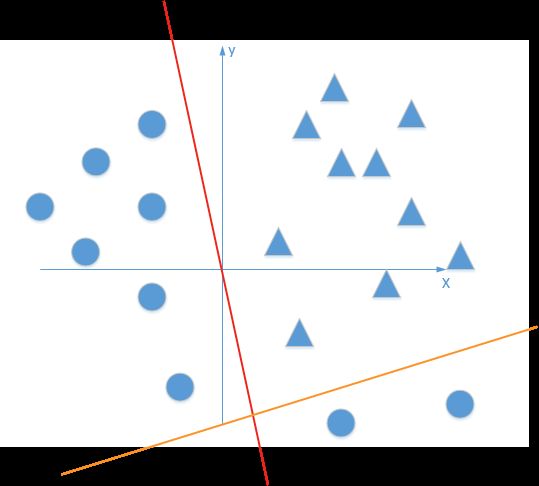
从理论上说,如果允许复合线性函数中的单个线性函数彼此平行或相交,则几乎所有数据集都可以通过多元线性复合函数进行线性切割。换句话说,多元线性复合函数可以无限逼近任意概率分布(通用逼近理论)。
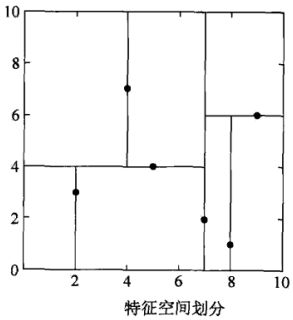
决策树的多层树结构,本质就是感知机DNN的多层结构。从这个角度来看,决策树和感知机DNN同样都存在过拟合问题。
延伸思考:
以R2二维空间为例,属于目标函数的点可能分布在空间中的任何位置,模型训练的过程就是需要找到一个超分界面,将所有的点都分类到合适的类别中,这就是所谓的”模型记忆“。需要注意的是,以下两个观点都是错误的:
- 有多少数据点就需要有多少神经元,每个神经元负责记忆一个数据点
- 样本点中有多少pattern,就需要多少神经元,每个神经元负责记忆一种pattern
正确的理解是:最少需要的神经元数量取决于目标函数概率分布的规律性,如果目标函数在特征空间中不同类别是彼此交错分布的,那么为了正确地”切割“出一个合适的超平面,就需要远大于pattern数的基函数,这样切出来的超平面边界会非常的锯齿状,相应的也可以想象,抗扰动能力也会相应下降。这也是为什么说越复杂的模型越容易过拟合的原因。
3. 非线性激活函数神经网络
上一小节留下的问题是,有没有既能实现完美分类,同时又能有效控制函数元数量的复合函数呢?答案是肯定的,这就是我们接下来要讨论的非线性复合函数(包含非线性激活函数的神经网络)。
我们知道,使用阶跃激活函数的多元感知机神经网络,本质上是多个线性分界面的组合,如下图:
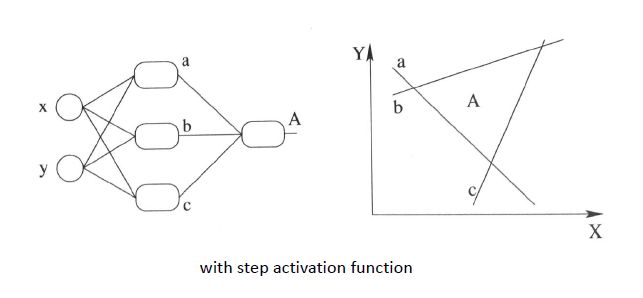
上图中,如果我们能构造出一个弯曲的决策超曲面,就可能实现用少量的非线性函数,直接对数据集进行分类。
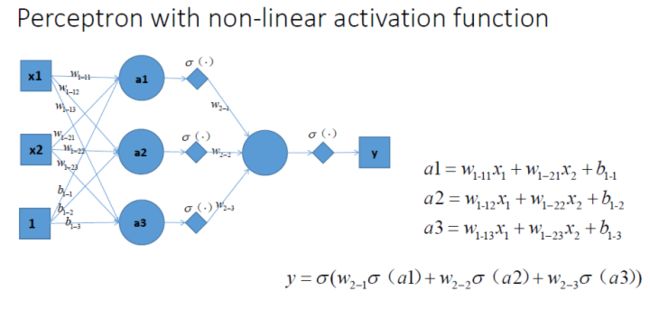
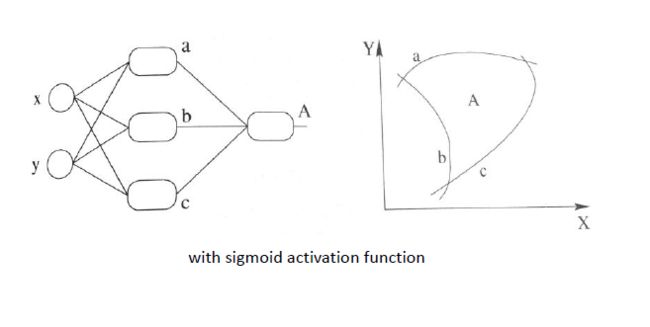
非线性激活函数有很多,不同的数学公式形式带来了不同的数学特性,这里我们以sigmoid函数为例:

单神经元后增加了一个非线性激活函数的神经网络
Relevant Link:
https://www.cnblogs.com/LittleHann/p/6629069.html - Neural Networks and Deep Learning(神经网络与深度学习) - 学习笔记
3. NNs和PR的等价性
这个章节我们来从神经网络的观点来看多项式拟合函数,并分析其等价性。
0x1:一元一次幂多项式函数和NNs的等价性
对于一元一次幂的逼近函数![]() :
:
![]()
可以看成为如下图的三层神经网络,

左:输入层到隐层的权系数均为常值1
右:输入层到隐层看成为“直接代入”(用虚线表示)
神经网络中只有一个隐层。隐层上有![]() 个节点,激活函数分别为基函数
个节点,激活函数分别为基函数![]() (从这里我们将基函数称为“激活函数”)。输入层到隐层的权设为常值1(左图),也可以看成为将输入层的值“直接代入”到激活函数(右图)。隐层到输出层的权为基函数的组合系数
(从这里我们将基函数称为“激活函数”)。输入层到隐层的权设为常值1(左图),也可以看成为将输入层的值“直接代入”到激活函数(右图)。隐层到输出层的权为基函数的组合系数![]() 。
。
0x2:n元m次幂多项式函数和NNs的等价性
考虑一般的逼近函数![]() 。设
。设![]() 中的一组基函数为
中的一组基函数为![]() 。则函数
。则函数![]() 可看成为如下图的一个三层的神经网络,
可看成为如下图的一个三层的神经网络,
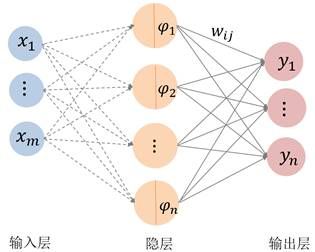
注意这里隐层的激活函数都是![]() 维函数,从输入层到隐层也是直接代入。输出层的各个分量
维函数,从输入层到隐层也是直接代入。输出层的各个分量![]() 共享隐层的激活函数。
共享隐层的激活函数。
一般地, 一个多元线性回归方程,等价于一个3层人工神经网络。也就是说,只要包含一个隐层的人工神经网络,就可以等价所有多形式回归模型。
更进一步地,如果给人工神经网络加上非线性激活函数、增加网络深度,这只是在增加神经网络的自由度,多项式回归依然能够在一个限定的误差ε内,近似地等价于该神经网络。
而且在实际工程中,这个近似的程度还得具体目标分布有关(目标问题场景),如果目标分布较简单,则在正则化稀疏学习的作用下,神经网络会退化为一个多项式函数。这就是为什我们在某些简单的问题上,用随机森林和深度神经网络的效果是差不多的,甚至传统随机森林效果还要更好。
Relevant Link:
http://staff.ustc.edu.cn/~lgliu/Resources/DL/What_is_DeepLearning.html
4. Universal Approximation Theorems(通用逼近理论)
上一章节我们讨论了NNs和PR的等价性,基本上来说,我们可以将NNs和PR视为同一种函数模型。这个章节我们就来讨论一个对它们二者都使用的通用逼近理论(universal approximation theorems),通用逼近理论告诉我们,一定存在一个多层神经网络或者多项式函数,可以在一定的误差ε内,近似地逼近任意函数分布。
虽然通用逼近定理并没有给出如何找到这个NNs或PR,但是它从理论上证明了强存在性,这个存在性定理实在令人振奋,因为这意味着,在具体工程项目中,我们总可以应用深度神经网络取得一个不错的结果。
0x1:什么是逼近问题
在讨论具体的理论之前,我们首先通过一个简单的案例,对逼近问题建立一个直观的感受。
我们先考虑最简单的情形,即实数到实数的一元函数![]() 。假设通过实验获得了m个样本点
。假设通过实验获得了m个样本点![]() 。我们希望求得反映这些样本点规律的一个函数关系
。我们希望求得反映这些样本点规律的一个函数关系![]() ,如下图所示。
,如下图所示。

1. 插值问题(Interpolation)
如果要求函数严格通过每个样本点,即:![]() ,则求解函数的问题称为插值问题(Interpolation)。插值问题一般需要针对样本数据直接求解线性方程组的解。
,则求解函数的问题称为插值问题(Interpolation)。插值问题一般需要针对样本数据直接求解线性方程组的解。
插值问题更多仅限于理论分析,在实际的工程中,因为误差和目标函数未知的缘故,几乎不可能找到一个函数能完美通过所有的样本点。所以,更多时候,我们需要讨论逼近问题,而插值问题就是逼近问题的一个特例(误差为0的逼近),相关讨论,可以参阅这篇文章。
2. 逼近问题(Approximation)
一般地,由于实验数据带有观测误差,因此在大部分情况下,我们只要求函数反映这些样本点的趋势,即函数靠近样本点且误差在某种度量意义下最小,称为逼近问题(Approximation)。
若记在某点的误差为![]() ,且记误差向量为
,且记误差向量为![]() 。逼近问题就是要求向量
。逼近问题就是要求向量![]() 的某种范数
的某种范数![]() 最小。一般采用欧氏范数(
最小。一般采用欧氏范数(![]() 范数)作为误差度量的标准(均方误差),即求如下极小化问题:
范数)作为误差度量的标准(均方误差),即求如下极小化问题:
![]()
极小化问题,一般可通过极大似然估计或者矩估计的方法实现。
通用逼近理论讨论的就是函数逼近问题,我们接下来围绕这个主题展开讨论。
0x2:逼近函数模型分类
在科学技术的各领域中,我们所研究的事件一般都是有规律(因果关系)的,即自变量集合与应变量集合之间存在的对应关系通常用映射来描述,按照模型(函数)是否具备明确的函数表达式(概率分布函数),可以将模型大致分为两类:
- 生成式模型:有些函数关系可由理论分析直接推导得出(先验),不仅为进一步的分析研究工作提供理论基础,也可以方便的解决实际工程问题。比如,适合于宏观低速物体的牛顿第二运动定律就是在实际观察和归纳中得出的普适性力学定律。
- 判别式模型:但是,很多工程问题难以直接推导出变量之间的函数表达式;或者即使能得出表达式,公式也十分复杂,不利于进一步的分析与计算。这时可以通过诸如采样、实验等方法获得若干离散的数据(称为样本数据点),然后根据这些数据,希望能得到这些变量之间的函数关系(后验),这个过程称为数据拟合(Data fitting),在数理统计中也称为回归分析(Regression analysis)。回归分析中有一类特殊情况,输出的结果是离散型的(比如识别图片里是人、猫、狗等标签的一种),此时问题称为分类(Classification)。
0x3:逼近函数方法
函数的表示是函数逼近论中的基本问题。在数学的理论研究和实际应用中经常遇到下类问题:在选定的一类函数中寻找某个函数,使它与已知函数(或观测数据)在一定意义下为最佳近似表示,并求出用近似表示而产生的误差。这就是函数逼近问题。
1. 逼近函数类
在实际问题中,首先要确定函数的具体形式。这不单纯是数学问题,还与所研究问题的运动规律及观测数据有关,也与用户的经验有关。一般地,我们在某个较简单的函数类中去寻找我们所需要的函数。这种函数类叫做逼近函数类。
逼近函数类可以有多种选择,一般可以在不同的函数空间(比如由一些基函数通过线性组合所张成的函数空间)中进行选择。如下是一些常用的函数类。
1)多项式函数类
n次代数多项式,即由次数不大于n的幂基![]() 的线性组合的多项式函数:
的线性组合的多项式函数:
![]()
其中![]() 为实系数。
为实系数。
更常用的是由n次Bernstein基函数来表达的多项式形式(称为Bernstein多项式或Bezier多项式):
![]()
其中Bernstein基函数![]()
2)三角多项式类
n阶三角多项式,即由阶数不大于n的三角函数基的线性组合的三角函数:
![]()
其![]() 中为实系数。
中为实系数。
这些是常用的逼近函数类。在逼近论中,还有许多其他形式的逼近函数类,比如由代数多项式的比构成的有理分式集(有理逼近);按照一定条件定义的样条函数集(样条逼近);径向基函数(RBF逼近);由正交函数系的线性组合构成的(维数固定的)函数集等。
3)其他基函数类
在逼近论中,还有许多其他形式的逼近函数类,比如:
- 由代数多项式的比构成的有理分式集(有理逼近)
- 按照一定条件定义的样条函数集(样条逼近)
- 径向基函数(RBF逼近)
- 由正交函数系的线性组合构成的(维数固定的)函数集等
- GMM模型(高斯分布基函数)
2. 万能逼近定理
在函数逼近论中,如果一组函数成为一组“基”函数,需要满足一些比较好的性质,比如:
- 光滑性(线性可微)
- 线性无关性
- 权性(所有基函数和为1)
- 局部支集
- 完备性:该组函数的线性组合是否能够以任意的误差和精度来逼近给定的函数(即万能逼近性质)
- 正性
- 凸性等。其中, “完备性”是指,?
我们重点来讨论一下完备性,即“万能逼近定理”,
【Weierstrass逼近定理】
对![]() 上的任意连续函数g,及任意给定的
上的任意连续函数g,及任意给定的![]() ,必存在n次代数多项式
,必存在n次代数多项式![]() ,使得:
,使得:
![]()
Weierstrass逼近定理表明,只要次数n足够高,n次多项式就能以任何精度逼近给定的函数。具体的构造方法有Bernstein多项式或Chebyshev多项式等。
类似地,由Fourier分析理论(或Weierstrass第二逼近定理),只要阶数足够高,n阶三角函数就能以任何精度逼近给定的周期函数,n阶高斯函数就能组成GMM分布以逼近任意给定的概率分布函数。
这些理论表明,多项式函数类、三角函数类、高斯函数在函数空间是“稠密”的,这就保障了用这些函数类来作为逼近函数是“合理”的。
0x4:逼近函数选择的最大挑战
在一个逼近问题中选择什么样的函数类作逼近函数类,这要取决于被逼近函数本身的特点,也和逼近问题的条件、要求等因素有关。在实际应用中,存在着两个最大的挑战,
- 选择什么样的逼近函数类?一般地,需要用户对被逼近对象或样本数据有一些“先验知识”来决定选择具体的逼近函数类。比如,
- 如果被逼近的函数具有周期性,将三角函数作为逼近函数是个合理的选择;
- 如果被逼近的函数具有奇点,将有理函数作为逼近函数更为合理,等等。
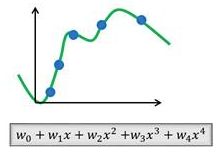
- 即使确定了逼近函数类,选择多高的次数或阶数?比如,如果选择了多项式函数类,根据Lagrange插值定理,一定能找到一个次多项式来插值给定的个样本点。但如果较大,则这样得到的高次多项式很容易造成“过拟合”(Overfitting)。而如果选择的过小,则得到的多项式容易造成“欠拟合”(Underfitting)。如下图所示。过拟合或欠拟合函数在实际应用中是没有用的,因为它们的泛化能力很差。

用不同次数的多项式拟合样本点(蓝色点)。
左:欠拟合;中:合适的拟合;右:过拟合。
这里需要提及的是,一个逼近函数“表达能力”体现在该函数的未知参数(例如多项式中的系数)与样本点个数的差,也称为“自由度”。
如果逼近函数的未知参数越多,则表达能力越强。然而,在实际的拟合问题中,逼近函数的拟合能力并非越强越好。因为如果只关注样本点处的拟合误差的话,非常强的表达能力会使得样本点之外的函数值远远偏离期望的目标,反而降低拟合函数的预测性能,产生过拟合,如上图(右)所示。拟合能力和过拟合规避之间的平衡,就是通过对自由度的控制来实现。
0x5:通用神经网络
这一小节,我们来讨论一下通用神经网络,主要是探寻NNs是如何同时实现通用逼近和防止过拟合这2个目标的,PR和NNs是等价的,因此本章的讨论对PR也同样成立。
对于通用神经网络来说,网络的结构设置都存在着如下两个主要挑战:
- 隐层中的节点中使用什么样的激活函数(基函数)?(注意这里激活函数不是特指sigmoid那种激活函数,而是泛指整个神经元的最终输出函数)
- 依赖专家先验经验
- 隐层中设置多少个节点(基函数的个数和次数)?
- 虽然有些基函数的性质很好,但是次数或阶数过高(比如多项式基或三角函数基),就会产生震荡,也容易产生过拟合,使得拟合函数的性态不好。
接下来我们来讨论通用神经网络是如何解决上述两大挑战的。
1. 使用简单“元函数”作为激活函数
如何在没有太多领域先验的情况下,选择合适的“基函数”的另一个策略是“原子化构建基础,数据驱动结构生成”。
注意到,对于任意一个非常值的一元函数![]() ,这里我们称为元函数,其沿着x方向的平移函数
,这里我们称为元函数,其沿着x方向的平移函数![]() ,以及沿着x方向的伸缩函数
,以及沿着x方向的伸缩函数![]() 都与原函数线性无关。
都与原函数线性无关。
也就是说,如果能有足够多的元函数经过平移和伸缩变换![]() ,其线性组合所张成的函数空间就能有充分的表达能力(高秩矩阵)。所以接下来的问题就是,如何有效地得到
,其线性组合所张成的函数空间就能有充分的表达能力(高秩矩阵)。所以接下来的问题就是,如何有效地得到![]() 。
。
一个自然的想法就是,我们可以以这个![]() 作为激活函数,让网络自动地去学习这些激活函数的变换
作为激活函数,让网络自动地去学习这些激活函数的变换![]() ,来表达所需要的拟合函数呢?如下图所示,
,来表达所需要的拟合函数呢?如下图所示,

一元(单变量)函数的神经元结构
对单神经元来说,变量![]() 乘以一个伸缩,加上一个平移(称为偏置“bias”),即变量的仿射变换,成为神经元的输入
乘以一个伸缩,加上一个平移(称为偏置“bias”),即变量的仿射变换,成为神经元的输入![]() ,然后通过激活函数
,然后通过激活函数![]() 复合后成为该神经元的输出
复合后成为该神经元的输出![]() 。
。
对于多变量的情形(多元函数),神经元的结构如下图所示,
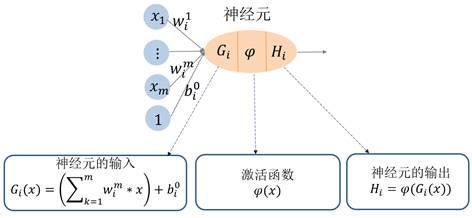
在多神经元网络中,每一层的所有神经元都互相连接,变量![]() 的线性组合,加上一个平移(称为偏置“bias”),即变量的仿射变换,成为神经元的输入
的线性组合,加上一个平移(称为偏置“bias”),即变量的仿射变换,成为神经元的输入![]() ;然后通过激活函数
;然后通过激活函数![]() 复合后成为该神经元的输出
复合后成为该神经元的输出![]() 。
。
一个多元函数的神经网络的结构如下图所示,有一个输入层,一个隐层及一个输出层,

- 输入层除了变量
 外,还有一个常数节点1
外,还有一个常数节点1
- 隐层包含多个节点,每个节点的激活函数都是
 ,隐层的输出就是输入层节点的线性组合加偏置(即仿射变换)
,隐层的输出就是输入层节点的线性组合加偏置(即仿射变换)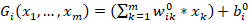 代入到激活函数的复合函数
代入到激活函数的复合函数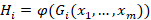
- 输出层是这些复合函数的组合

这个网络的所有权系数![]() (层与层神经元之间的权),
(层与层神经元之间的权),![]() (偏置项)及作为这个神经网络的参数变量,需要通过极小化损失函数来求解的。这个过程称为“训练”或“学习”。
(偏置项)及作为这个神经网络的参数变量,需要通过极小化损失函数来求解的。这个过程称为“训练”或“学习”。
和回归分析类似,神经网络的学习过程本质上就是在学习所有的系数参数。最后得到的拟合函数![]() 为一些基函数的线性组合表达。这些组合函数
为一些基函数的线性组合表达。这些组合函数![]() 实质上就是表达函数
实质上就是表达函数![]() 的“基函数”。这样就通过数据驱动的方式,得到了一个最优的基函数线性组合。
的“基函数”。这样就通过数据驱动的方式,得到了一个最优的基函数线性组合。
从这个观点来看,神经网络本质上就是传统的逼近论中的逼近函数的一种推广。它不是通过指定的理论完备的基函数(例如多项式,三角多项式等)来表达函数的,而是通过简单的基元函数(激活函数)的不断变换得到的“基函数”来表达函数的。
2. 使用超完备集实现万能逼近
解决了基函数选择的问题,我们还要问个问题:将函数经过充分多的平移和伸缩(包括它们的组合)所线性张成的函数空间,其表达能力足够强吗?这个函数空间是否在所有函数空间是稠密的?
如果结论是肯定的,那么就是说,对于任何一个给定的函数,总能找到函数的多次平移和缩放的函数,其线性组合能够逼近给定的这个函数。也就是说,神经网络只要隐层的节点数足够多,该网络所表达的函数就能逼近任意的函数。
这个结论在大多数情况是成立的,由【万能逼近定理】所保证。
记![]() 为空间中的单位立方体,我们在这个定义域中来描述万能逼近定理。记
为空间中的单位立方体,我们在这个定义域中来描述万能逼近定理。记![]() 为
为![]() 上的连续函数空间,
上的连续函数空间,![]() 为
为![]() 上的可测函数空间,
上的可测函数空间,![]() 为
为![]() 上相对测度μ的可积函数空间(即
上相对测度μ的可积函数空间(即![]() )。
)。
设给定一元激活函数,首先给出如下定义,
【定义1】称函数![]() 为压缩函数,如果
为压缩函数,如果![]() 单调不减,且满足
单调不减,且满足
![]()
【定义2】称函数![]() 为可分辨的,若对于有限测度μ,由
为可分辨的,若对于有限测度μ,由
![]()
可得到![]()
【定义3】记
![]()
为所有由激活函数变换及线性累加所构成的m维函数空间(即具有n个节点的单隐层神经网络所表达的m维函数)。
由以上定义,有以下几个定理(涉及实分析和泛函分析),
【定理1】若![]() 是压缩函数,则
是压缩函数,则![]() 在
在![]() 中一致稠密,在
中一致稠密,在![]() 中按如下距离
中按如下距离![]() 下稠密:
下稠密:
![]()
【定理2】若![]() 是可分辨的,则
是可分辨的,则![]() 在
在![]() 中按连续函数距离下稠密。
中按连续函数距离下稠密。
【定理3】若![]() 是连续有界的非常值函数,则
是连续有界的非常值函数,则![]() 在
在![]() 中稠密。
中稠密。
【定理4】若![]() 是无界的非常值函数,则
是无界的非常值函数,则![]() 在
在![]() 中稠密。
中稠密。
通俗地说就是:对任意给定的一个![]() 中的函数
中的函数![]() ,只要项数
,只要项数![]() 足够多,
足够多,![]() 中就存在一个函数
中就存在一个函数![]() ,使得
,使得![]() 在一定精度下逼近
在一定精度下逼近![]() 。也就是说,包含m个神经元的单隐层的神经网络所表达的
。也就是说,包含m个神经元的单隐层的神经网络所表达的![]() 维函数能够逼近
维函数能够逼近![]() 中的任意一个函数。
中的任意一个函数。
基于万能逼近定理,人工神经网络往往会选择一个超完备集神经元,即用大于目标函数维度的神经元数量,来构建一个复杂神经网络,以保证近似逼近能力。
3. 使用稀疏学习在超完备集中选择合适数量的基函数,以降低自由度
使用超完备集在获得万能逼近能力的同时,会带来过拟合问题。在人工神经网络中加入稀疏学习,可以有效避免该现象。
Relevant Link:
http://staff.ustc.edu.cn/~lgliu/Resources/DL/What_is_DeepLearning.html K. Hornik, et al. Multilayer feedforward networks are universal approximations. Neural Networks, 2: 359-366, 1989. G. Cybenko. Approximation by superpositions of a sigmoidal function. Math. Control Signals System, 2: 303-314, 1989. K. Hornik. Approximation capabilities of multilayer feedforward networks. Neural Networks, 4: 251-257, 1991.
5. PR(多项式回归)and NNs(神经网络)Overfitting
在实际工程项目中,不管是直接应用VGG-xx或者自己设计一种全新的网络结构,网络的参数动辄都上千万,网络越来越复杂,参数越来越多。
但需要注意的是,拟合函数所带的参数的个数与样本数据的个数之间的差代表着这个拟合函数的“自由度”。网络越来越“深”后,拟合模型中的可调整参数的数量就非常大。因此,层数很大的深度网络(模型过于复杂)能够表达一个自由度非常大的函数空间,甚至远高于目标函数空间(过完备空间),即自由度远大于0。这样就很容易导致过拟合(Overfitting),例如下图所示,
过拟合可以使得拟合模型能够插值所有样本数据(拟合误差为0!)。但拟合误差为0不代表模型就是好的,因为模型只在训练集上表现好;由于模型拟合了训练样本数据中的噪声,使得它在测试集上表现可能不好,泛化性能差等。
为此,人们采取了不同的方法来缓解过拟合(无法完全避免),比如正则化、数据增广、Dropout、网络剪枝等。这些方法的底层原理,归结为一句话都是:稀疏表达和稀疏学习。
0x1:稀疏表达和稀疏学习 - 缓解overfitting的有效手段
缓解逼近函数过拟合的有效手段是,在函数公式中对回归变量施加范数的正则项,例如L1/L2正则项,以达到对回归变量进行稀疏化,即大部分回归变量为0(少数回归变量非0)。
这种优化称为稀疏优化。也就是说,对回归变量施加范数能够“自动”对基函数进行选择,值为0的系数所对应的基函数对最后的逼近无贡献。这些非0的基函数反映了的样本点集合的“特征”,因此也称为特征选择。
我们往往可以多选取一些基函数(甚至可以是线性相关的)及较高的次幂,使得基函数的个数比输入向量的维数还要大,称为“超完备”基(Over-complete basis)或过冗余基,在稀疏学习中亦称为“字典”。然后通过对基函数的系数进行稀疏优化(稀疏学习/字典学习),选择出合适(非0系数)的基函数的组合来表达逼近函数。
稀疏学习与最近十年来流行的压缩感知(Compressive sensing)理论与方法非常相关,也是机器学习领域的一种重要方法。其理论基础由华裔数学家陶哲轩(2006年国际数学家大会菲尔兹奖得主)、斯坦福大学统计学教授David Donoho(2018年国际数学家大会高斯奖得主)等人所建立,已成功用于信号处理、图像与视频处理、语音处理等领域。
Relevant Link:
https://cosx.org/2016/06/discussion-of-sparse-coding-in-deep-learning/
6. Multicollinearity(多重共线性)
所谓多重共线性,简单来说,是指回归模型中存在两个或两个以上的自变量彼此相关。其实本质上说,多重共线性和我们上一章讨论的超完备基本质上是一样的,因为超完备基常常是稀疏的,其内部往往存在较多线性相关的结构。
在NNs和PR中,也同样存在多重共线性问题,所以这章我们也来讨论这个问题,通过这些讨论,我们能够更加深刻理解NNs和PR的等价性。
0x1:造成多重共线性的原因
- 解释变量都享有共同的时间趋势
- 一个解释变量是另一个的滞后,二者往往遵循一个趋势
- 由于数据收集的基础不够宽,某些解释变量可能会一起变动
- 某些解释变量间存在某种近似的线性依赖关系
0x2:处理多重共线性的原则
- 多重共线性是普遍存在的,轻微的多重共线性问题可不采取措施
- 如果模型仅用于预测,则只要拟合程度好,可不处理多重共线性问题,存在多重共线性的模型用于预测时,往往不影响预测结果
0x3:多重共线性的负面影响
- 变量之间高度相关,可能使回归的结果混乱,甚至把分析引入歧途
- 难以区分每个解释变量的单独影响
- 变量的显著性检验失去意义,模型的线性关系检验(F检验)显著,但几乎所有回归系数bi的t检验却不显著
- 对参数估计值的正负号产生影响,特别是估计系数的符号可能与预期的正相反,造成对回归系数的解释是危险的。比如:违约率应该和贷款余额是正相关的,但由于有其他因素的影响最终模型中贷款余额的系数为负,得到“贷款余额越大违约率越低”的危险解释。可见,在建立回归模型时,并不会特征变量越多越好,因为他们带来问题比解决的问题可能更多
- 回归模型缺乏稳定性。样本的微小扰动都可能带来参数很大的变化,因为重复的特征变量很多,任何一个扰动都可能被放大很多倍
- 影响模型的泛化误差
0x4:方差扩大因子VIF(variance inflation factor):定量评估多重共线性程度
0x5:多重共线性影响举例
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn.linear_model import LinearRegression from sklearn import cross_validation if __name__ == '__main__': # 首先捏造一份好的数据,样本量为100,特征数为8,且满足方程: y = 5x_0 + 6x_1 + 7x_2 + 8x_3 + 9x_4 + 10x_5 + 11x_6 + 12x_7 + b coef0 = np.array([5, 6, 7, 8, 9, 10, 11, 12]) X1 = np.random.rand(100, 8) # 误差项是期望为0,标准差为1.5的正态分布随机变量。 y = np.dot(X1, coef0) + np.random.normal(0, 1.5, size=100) training = np.random.choice([True, False], p=[0.8, 0.2], size=100) lr1 = LinearRegression() lr1.fit(X1[training], y[training]) # 系数的均方误差MSE print "lr1 MSE: ", (((lr1.coef_ - coef0) ** 2).sum() / 8) # 测试集准确率(R2) print "lr1 R2:", (lr1.score(X1[~training], y[~training])) # 平均测试集准确率 print "lr1 MR2:", (cross_validation.cross_val_score(lr1, X1, y, cv=5).mean()) # 基于上面构造数据,另外构造出两份数据, # 1. X2: 第一份数据则增加两个共线性特征,目的是显著增加其VIF值 # 2. X3: 第二份数据增加两个随机的特征用作对比 X2 = np.column_stack([X1, np.dot(X1[:, [0, 1]], np.array([1, 1])) + np.random.normal(0, 0.05, size=100)]) X2 = np.column_stack([X2, np.dot(X2[:, [1, 2, 3]], np.array([1, 1, 1])) + np.random.normal(0, 0.05, size=100)]) X3 = np.column_stack([X1, np.random.rand(100, 2)]) # 拿这两份数据重新用线性回归拟合模型 lr2 = LinearRegression() lr2.fit(X2[training], y[training]) # 系数的均方误差MSE # 对于第二份共线性构造数据X2,因为多重共线性,可以看到MSE增加了很多,准确率也下降了0.2%: print "lr2 MSE: ", (((lr2.coef_[:8] - coef0) ** 2).sum() / 8) # 测试集准确率(R2) print "lr2 R2: ", (lr2.score(X2[~training], y[~training])) # 平均测试集准确率 print "lr2 MR2: ", (cross_validation.cross_val_score(lr2, X2, y, cv=5).mean()) lr3 = LinearRegression() lr3.fit(X3[training], y[training]) # 系数的均方误差MSE # X3没有明显变化 print "lr3 MSE: ", (((lr3.coef_[:8] - coef0) ** 2).sum() / 8) # 测试集准确率(R2) print "lr3 R2: ", (lr3.score(X3[~training], y[~training])) # 平均测试集准确率 print "lr3 MR2: ", (cross_validation.cross_val_score(lr3, X3, y, cv=5).mean()) # show lr2 VIF result vif2 = np.zeros((10, 1)) for i in range(10): tmp = [k for k in range(10) if k != i] lr2.fit(X2[:, tmp], X2[:, i]) vifi = 1 / (1 - lr2.score(X2[:, tmp], X2[:, i])) vif2[i] = vifi vif3 = np.zeros((10, 1)) for i in range(10): tmp = [k for k in range(10) if k != i] lr2.fit(X3[:, tmp], X3[:, i]) vifi = 1 / (1 - lr2.score(X3[:, tmp], X3[:, i])) vif3[i] = vifi plt.figure() ax = plt.gca() ax.plot(vif2) ax.plot(vif3) plt.xlabel('feature') plt.ylabel('VIF') plt.title('VIF coefficients of the features') plt.axis('tight') plt.show()

可以看到,0、1、2、3、8、9个特征的VIF都过高,其中第9个是我们人工构造出了存在线性相关依赖的新特征变量。
0x6:NNs中普遍存在的多重共线性
在神经网络中,同层的神经元和层与层之间的神经元之间都有可能存在多重共线性(线性相关),层内的多重共线性可以通过正则化进行缓解,相比之下,层与层神经元之间存在的多重共线性就无法避免了,它是普遍存在的。

计算层与层之间神经元的平均VIF结果如下:

可以看到随着前向传递的进行,后面层的神经元的VIF越来越大,以层的视角来看,层与层之间的线性相关性逐渐提高,这个结论对PR也是同样成立的。
这也从另一个层面看到,对于神经网络来说,真正起作用的也只有最后一层隐层,虽然训练过程是全网络整体反馈调整的,但是最终输出层的结果大部分由最有一层隐层的基函数决定。
Relevant Link:
https://baike.baidu.com/item/%E6%96%B9%E5%B7%AE%E6%89%A9%E5%A4%A7%E5%9B%A0%E5%AD%90 https://www.jianshu.com/p/0925347c5066 https://www.jianshu.com/p/ef1b27b8aee0 https://arxiv.org/pdf/1806.06850v1.pdf
7. 深度模型可解释性初探:用简单局部线性函数近似逼近深度神经网络
0x1:基本原理说明
1. Interpretable Data Representations(可解释性数据表征)
一般来说,模型的输入层是可解释性最强的,例如原始专家经验特征、图像像素矩阵、文本原始词序列向量等。
假设输入层维度为d,可解释性模型的维度d’应该小于等于输入层维度d,用”0/1“编码来表征输入层的每一个特征是否出现,即,
![]()
2. 保真性和解释性平衡 - 构建似然估计函数
Local Interpretable Model-agnostic Explanations(局部线性逼近可解释模型)需要同时平衡两个对立的目标:
- 保真性
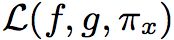 :可解释性复合线性函数和目标函数的逼近误差要尽量小
:可解释性复合线性函数和目标函数的逼近误差要尽量小 - 可解释性
 :可解释性复合函数本身的复杂度要尽量低,基元函数数量越少,就越能从中理解到人类可读的可解释性
:可解释性复合函数本身的复杂度要尽量低,基元函数数量越少,就越能从中理解到人类可读的可解释性
通过极大似然估计来获得一个最优结果:

3. 基于局部扰动采样的负反馈训练过程
LIME捕获局部线性特征的过程如下图所示,

将目标函数f()看成是一个零先验黑盒,通过不断重复f(x)->add random noise to x->f(x),勾勒出目标函数的近似局部边界,并将获取的样本作为打标数据输入LIMIE模型进行负反馈训练,这个做法和蒙特卡洛采样的思想是类似的。

还有一点值得注意,LIMIE同时使用正则化来进行稀疏学习,进一步减少可解释性单元,将可解释单元集中在特定的一些重点特征上,提高人类可读性。
0x2:随机森林特征可解释性
我们知道,随机森林本质上是一个最优赫夫曼编码函数。在随机森林每棵树中,特征节点的选择和各个特征节点所处的位置,本身就包含了一个复合线性决策函数的能力。但是,我们最多也只能定性地了解有限特征的相对重要性,对每一个特征定量的重要性评估无法得知。
我们通过LIME对一个随机森林模型进行“local linear approximation(局部线性近似)”,借助线性函数的强可解释性,来定量研究随机森林在预测中,各个特征向量各自起到了多少的贡献(似然概率)。
# -*- coding: utf-8 -*- import lime import sklearn import numpy as np import sklearn import sklearn.ensemble import sklearn.metrics from sklearn.datasets import fetch_20newsgroups from lime import lime_text from sklearn.pipeline import make_pipeline from lime.lime_text import LimeTextExplainer if __name__ == '__main__': # we'll be using the 20 newsgroups dataset. # In particular, for simplicity, we'll use a 2-class subset: atheism and christianity. categories = ['alt.atheism', 'soc.religion.christian'] newsgroups_train = fetch_20newsgroups(subset='train', categories=categories) newsgroups_test = fetch_20newsgroups(subset='test', categories=categories) class_names = ['atheism', 'christian'] # use the tfidf vectorizer, commonly used for text. vectorizer = sklearn.feature_extraction.text.TfidfVectorizer(lowercase=False) train_vectors = vectorizer.fit_transform(newsgroups_train.data) test_vectors = vectorizer.transform(newsgroups_test.data) # use random forests for classification. # It's usually hard to understand what random forests are doing, especially with many trees. rf = sklearn.ensemble.RandomForestClassifier(n_estimators=500) rf.fit(train_vectors, newsgroups_train.target) pred = rf.predict(test_vectors) print sklearn.metrics.f1_score(newsgroups_test.target, pred, average='binary') # Lime explainers assume that classifiers act on raw text, # but sklearn classifiers act on vectorized representation of texts. # For this purpose, we use sklearn's pipeline, and implements predict_proba on raw_text lists. c = make_pipeline(vectorizer, rf) print(c.predict_proba([newsgroups_test.data[0]])) # Now we create an explainer object. We pass the class_names a an argument for prettier display. explainer = LimeTextExplainer(class_names=class_names) # We then generate an explanation with at most 6 features for an arbitrary document in the test set. idx = 83 exp = explainer.explain_instance(newsgroups_test.data[idx], c.predict_proba, num_features=6) print('Document id: %d' % idx) print('Probability(christian) =', c.predict_proba([newsgroups_test.data[idx]])[0, 1]) print('True class: %s' % class_names[newsgroups_test.target[idx]]) # The classifier got this example right (it predicted atheism). # The explanation is presented below as a list of weighted features. print "exp.as_list(): ", exp.as_list() # These weighted features are a linear model, # which approximates the behaviour of the random forest classifier in the vicinity of the test example. # Roughly, if we remove 'Posting' and 'Host' from the document , # the prediction should move towards the opposite class (Christianity) by about 0.27 (the sum of the weights for both features). # Let's see if this is the case. print('Original prediction:', rf.predict_proba(test_vectors[idx])[0, 1]) tmp = test_vectors[idx].copy() tmp[0, vectorizer.vocabulary_['Posting']] = 0 tmp[0, vectorizer.vocabulary_['Host']] = 0 print('Prediction removing some features:', rf.predict_proba(tmp)[0, 1]) print('Difference:', rf.predict_proba(tmp)[0, 1] - rf.predict_proba(test_vectors[idx])[0, 1]) # Visualizing explanations # The explanations can be returned as a matplotlib barplot: fig = exp.as_pyplot_figure() fig.show() exp.save_to_file('./oi.html')

可以看到,在将某一个document预测为“atheism”这一类别的时候,总共有“edu”、“NNTP”、“Posting”、“Host”、“There”、“hava”这些单词起到了似然概率贡献,并且它们各自的贡献比是不同的。
0x3:InceptionV3图像识别预测可解释性分析
google的InceptionV3神经网络模型,采用卷积网络对图像进行了预训练。这节,我们用局部线性逼近方法,来对该网络的局部可解释性进行分析。
# -*- coding: utf-8 -*- import matplotlib.pyplot as plt import numpy as np import os import keras import os, sys try: import lime except: sys.path.append(os.path.join('..', '..')) # add the current directory import lime from lime import lime_image from keras.applications import inception_v3 as inc_net from keras.preprocessing import image from keras.applications.imagenet_utils import decode_predictions from skimage.io import imread from skimage.segmentation import mark_boundaries print('run using keras:', keras.__version__) def transform_img_fn(path_list): out = [] for img_path in path_list: img = image.load_img(img_path, target_size=(299, 299)) x = image.img_to_array(img) x = np.expand_dims(x, axis=0) x = inc_net.preprocess_input(x) out.append(x) return np.vstack(out) if __name__ == '__main__': # Using Inception # Here we create a standard InceptionV3 pretrained model, # and use it on images by first preprocessing them with the preprocessing tools inet_model = inc_net.InceptionV3() # Let's see the top 5 prediction for some image img_path = os.path.join('data', 'cat_and_mouse.jpg') print "img_path: ", img_path images = transform_img_fn([img_path]) # I'm dividing by 2 and adding 0.5 because of how this Inception represents images plt.imshow(images[0] / 2 + 0.5) plt.show() preds = inet_model.predict(images) for x in decode_predictions(preds)[0]: print(x) # Explanation # Now let's get an explanation explainer = lime_image.LimeImageExplainer() # hide_color is the color for a superpixel turned OFF. # Alternatively, if it is NONE, the superpixel will be replaced by the average of its pixels. # Here, we set it to 0 (in the representation used by inception model, 0 means gray) explanation = explainer.explain_instance(images[0], inet_model.predict, top_labels=5, hide_color=0, num_samples=1000) # Now let's see the explanation for the Top class # We can see the top 5 superpixels that are most positive towards the class with the rest of the image hidden temp, mask = explanation.get_image_and_mask(explanation.top_labels[0], positive_only=True, num_features=5, hide_rest=True) plt.imshow(mark_boundaries(temp / 2 + 0.5, mask)) plt.show() # Or with the rest of the image present: temp, mask = explanation.get_image_and_mask(explanation.top_labels[0], positive_only=True, num_features=5, hide_rest=False) plt.imshow(mark_boundaries(temp / 2 + 0.5, mask)) plt.show() # We can also see the 'pros and cons' (pros in green, cons in red) temp, mask = explanation.get_image_and_mask(explanation.top_labels[0], positive_only=False, num_features=10, hide_rest=False) plt.imshow(mark_boundaries(temp / 2 + 0.5, mask)) plt.show() # Or the pros and cons that have weight at least 0.1 temp, mask = explanation.get_image_and_mask(explanation.top_labels[0], positive_only=False, num_features=1000, hide_rest=False, min_weight=0.1) plt.imshow(mark_boundaries(temp / 2 + 0.5, mask)) plt.show()

原始待预测打标图像

通过局部线性逼近得到的top预测类(tabby)分界面(核心特征区)

with the rest of the image present
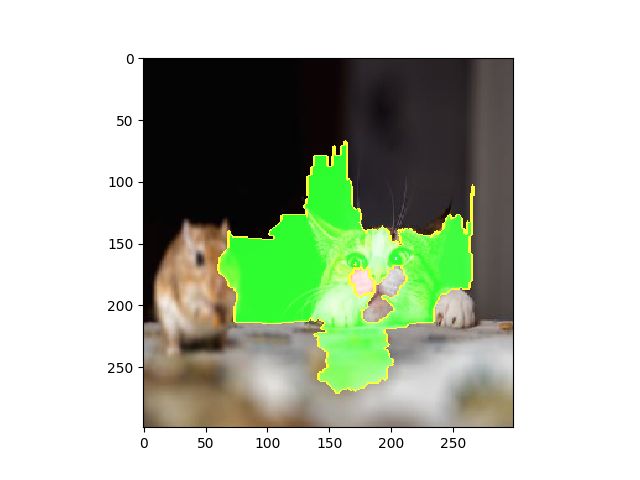
pros and cons' (pros in green, cons in red)
通过这个例子,我们可以更加深刻的认识到,卷积神经网络是如何通过选取捕获像素图中特定区域,实现目标检测与目标识别任务的。
0x4:Recurrent neural networks可解释性可视化探索
# -*- coding: utf-8 -*- import matplotlib.pyplot as plt import numpy as np import pandas as pd from keras.models import Sequential from keras.layers import LSTM, Dropout, Dense from keras.optimizers import Adam from keras.utils import to_categorical from sklearn.preprocessing import MinMaxScaler from sklearn.metrics import classification_report from lime import lime_tabular def reshape_data(seq, n_timesteps): N = len(seq) - n_timesteps - 1 nf = seq.shape[1] if N <= 0: raise ValueError('I need more data!') new_seq = np.zeros((N, n_timesteps, nf)) for i in range(N): new_seq[i, :, :] = seq[i:i+n_timesteps] return new_seq if __name__ == '__main__': # We will use the CO2 dataset, which measures the concentration of CO2 above Mauna Loa every week since about 1960. # The classification task will be deciding if the concentration is rising, # this is a problem that needs recurrency to solve (since the answer comes from the derivative), # and is less trivial than it sounds because there is noise in the data. df = pd.read_csv('data/co2_data.csv', index_col=0, parse_dates=True) fig, (left, right) = plt.subplots(nrows=1, ncols=2, figsize=(13, 5)) df[['co2']].plot(ax=left) df[['co2_detrended']].plot(ax=right) fig.show() # Reshaping the dataset to be appropriate for the model N_TIMESTEPS = 12 # Use 1 year of lookback data_columns = ['co2', 'co2_detrended'] target_columns = ['rising'] scaler = MinMaxScaler(feature_range=(-1, 1)) X_original = scaler.fit_transform(df[data_columns].values) X = reshape_data(X_original, n_timesteps=N_TIMESTEPS) y = to_categorical((df[target_columns].values[N_TIMESTEPS:-1]).astype(int)) # Train on the first 2000, and test on the last 276 samples X_train = X[:2000] y_train = y[:2000] X_test = X[2000:] y_test = y[2000:] print(X.shape, y.shape) # Define the model model = Sequential() model.add(LSTM(32, input_shape=(N_TIMESTEPS, len(data_columns)))) model.add(Dropout(0.2)) model.add(Dense(2, activation='softmax')) optimizer = Adam(lr=1e-4) model.compile(loss='binary_crossentropy', optimizer=optimizer) # train the model model.fit(X_train, y_train, batch_size=100, epochs=100, validation_data=(X_test, y_test), verbose=2) y_pred = np.argmax(model.predict(X_test), axis=1) y_true = np.argmax(y_test, axis=1) print(classification_report(y_true, y_pred)) plt.plot(y_true, lw=3, alpha=0.3, label='Truth') plt.plot(y_pred, '--', label='Predictions') plt.legend(loc='best') plt.show() # Explain the model with LIME explainer = lime_tabular.RecurrentTabularExplainer(X_train, training_labels=y_train, feature_names=data_columns, discretize_continuous=True, class_names=['Falling', 'Rising'], discretizer='decile') exp = explainer.explain_instance(X_test[50], model.predict, num_features=10, labels=(1,)) print exp exp.show_in_notebook()
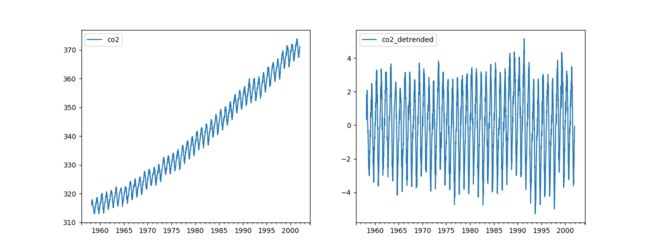


We can see that the most important features are the de-trended CO2 concentration several timesteps in the past. In particular, we see that if that feature is low in the recent past, then the concentration is now probably rising.
0x5:Webshell Random Foreast模型可解释性可视化探索
1. 加载webshell黑白样本

100个黑/300个白
2. TF_IDF特征工程,随机森林训练
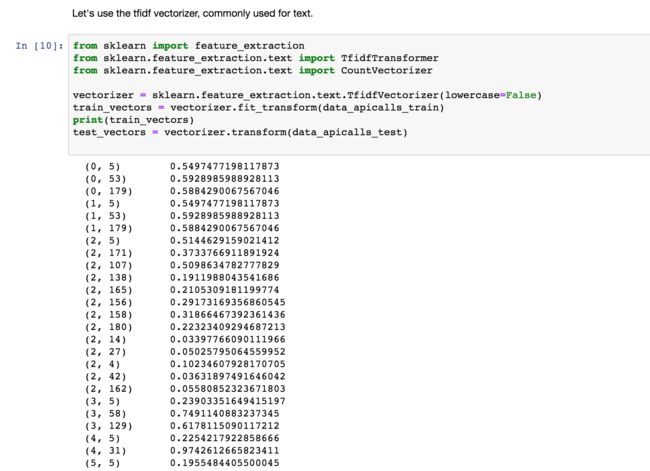
TF_IDF词素似然概率

测试集预测结果
3. LIME局部特征逼近
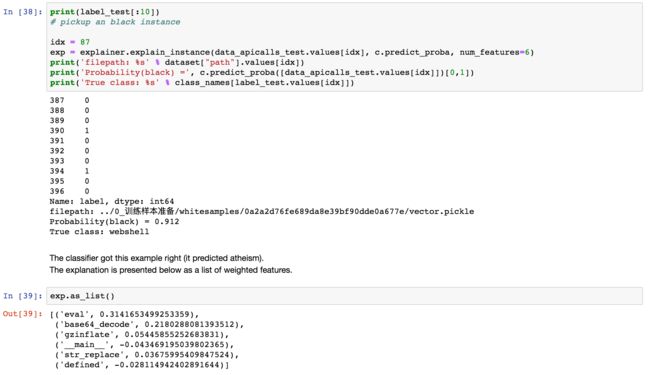
LIME中各个子线性模型的似然概率占比
可以看到,对于这个判黑样本来说,主要是'eval'、'base64_decode'、'gzinflate'这些关键词起到了似然概率贡献作用,这也和我们的安全领域先验知识是吻合的。
同时,为了进一步理解线性基元对目标函数的局部线性近似逼近,我们手动disable掉2个top似然概率的基元函数,并观察目标函数的预测结果,
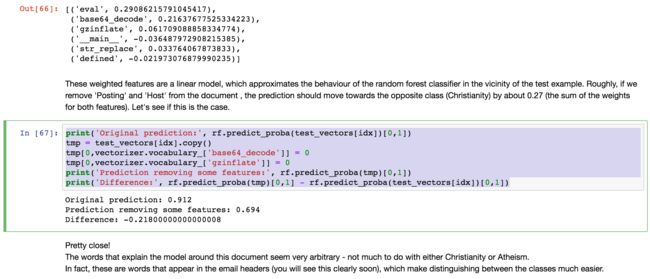
去掉eval和base64_decode之后,目标函数的预测概率值等于这2个函数各自的基元函数的可解释似然概率
这个实验结果,证实了LIME基于随机扰动负反馈的局部线性逼近的有效性,LIME的局部线性基元函数可以较好的代表目标函数的总体特征,局部汇总=总体,即1+1+1=3。
反过来,这种可解释性也为webshell领域里的文本畸形变化对抗提供了理论依据,在文本词维度的扰动可以干扰文本词维度的检测机制。作为防御方,要对抗这种对抗,就需要将模型抽象维度拉升到更高的维度,例如apicall、opcode、汇编代码层等。
4. 可视化LIME可解释模型

LIME基元函数中对判黑和判白的各自似然概率占比

Relevant Link:
https://github.com/marcotcr/lime/blob/master/doc/notebooks/Tutorial%20-%20Image%20Classification%20Keras.ipynb https://arxiv.org/pdf/1602.04938.pdf