基本思想
通过Dlib获得当前人脸的特征点,然后通过旋转平移标准模型的特征点进行拟合,计算标准模型求得的特征点与Dlib获得的特征点之间的差,使用Ceres不断迭代优化,最终得到最佳的旋转和平移参数。
使用环境
系统环境:Ubuntu 18.04
使用语言:C++
编译工具:CMake
第三方工具
Dlib:用于获得人脸特征点
Ceres:用于进行非线性优化
CMinpack:用于进行非线性优化 (OPTIONAL)
源代码
https://github.com/Great-Keith/head-pose-estimation/tree/master/cpp
基础概念
旋转矩阵
头部的任意姿态可以转化为6个参数(yaw, roll, pitch, tx, ty, tz),前三个为旋转参数,后三个为平移参数。
平移参数好理解,原坐标加上对应的变化值即可;旋转参数需要构成旋转矩阵,三个参数分别对应了绕y轴旋转的角度、绕z轴旋转的角度和绕x轴旋转的角度。
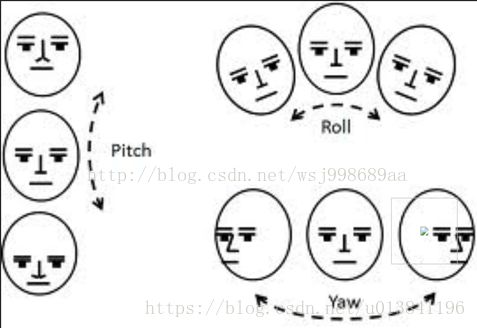
具体代码实现我们可以通过Dlib已经封装好的API,rotate_around_x/y/z(angle)。该函数返回的类型是dlib::point_transform_affine3d,可以通过括号进行三维的变形,我们将其封装成一个rotate函数使用如下:
void rotate(std::vector& points, const double yaw, const double pitch, const double roll)
{
dlib::point_transform_affine3d around_z = rotate_around_z(roll * pi / 180);
dlib::point_transform_affine3d around_y = rotate_around_y(yaw * pi / 180);
dlib::point_transform_affine3d around_x = rotate_around_x(pitch * pi / 180);
for(std::vector::iterator iter=points.begin(); iter!=points.end(); ++iter)
*iter = around_z(around_y(around_x(*iter)));
} [NOTE] 其中point3f是我自己定义的一个三维点坐标类型,因为Dlib中并没有提供,而使用OpenCV中的cv::Point3f会与dlib::point定义起冲突。定义如下:
typedef dlib::vector point3f; [NOTE] Dlib中的dlib::vector不是std::vector,注意二者区分。
LM算法
这边不进行赘诉,建议跟着推导一遍高斯牛顿法,LM算法类似于高斯牛顿法的进阶,用于迭代优化求解非线性最小二乘问题。在该程序中使用Ceres/CMinpack封装好的API(具体使用见后文)。
三维空间到二维平面的映射
根据针孔相机模型我们可以轻松的得到三维坐标到二维坐标的映射:
\(X^{2d}=f_x(\frac{X^{3d}}{Z^{3d}})+c_x\)
\(Y^{2d}=f_y(\frac{Y^{3d}}{Z^{3d}})+c_y\)
[NOTE] 使用上角标来表示3维坐标还是2维坐标,下同。
其中\(f_x, f_y, c_x, c_y\)为相机的内参,我们通过OpenCV官方提供的Calibration样例进行获取:
例如我的电脑所获得的结果如下:

从图中矩阵对应关系可以获得对应的参数值。
#define FX 1744.327628674942
#define FY 1747.838275588676
#define CX 800
#define CY 600[NOTE] 本程序不考虑外参。
具体步骤
获得标准模型的特征点
该部分可见前一篇文章:BFM使用 - 获取平均脸模型的68个特征点坐标
我们将获得的特征点保存在文件 landmarks.txt 当中。
使用Dlib获得人脸特征点
该部分不进行赘诉,官方有给出了详细的样例。
具体可以参考如下样例:
- https://github.com/davisking/dlib/blob/master/examples/face_landmark_detection_ex.cpp
- https://github.com/davisking/dlib/blob/master/examples/webcam_face_pose_ex.cpp(通过这个样例可以学习OpenCV如何调用摄像头)
其中使用官方提供的预先训练好的模型,下载地址:http://dlib.net/files/shape_predictor_68_face_landmarks.dat.bz2
具体在代码中使用如下:
cv::Mat temp;
if(!cap.read(temp))
break;
dlib::cv_image img(temp);
std::vector dets = detector(img);
cout << "Number of faces detected: " << dets.size() << endl;
std::vector shapes;
for (unsigned long j = 0; j < dets.size(); ++j) {
/* Use dlib to get landmarks */
full_object_detection shape = sp(img, dets[j]);
/* ... */
} 其中shape.part就存放着我们通过Dlib获得的当前人脸的特征点二维点序列。
[NOTE] 在最后CMake配置的时候,需要使用Release版本(最重要),以及增加选项USE_AVX_INSTRUCTIONS和USE_SSE2_INSTRUCTIONS/USE_SSE4_INSTRUCTIONS,否则因为Dlib的检测耗时较长,使用摄像头即时拟合会有严重的卡顿。
使用Ceres进行非线性优化
Ceres的使用官方也提供了详细的样例,在此我们使用的是数值差分的方法,可参考:https://github.com/ceres-solver/ceres-solver/blob/master/examples/helloworld_numeric_diff.cc
Problem problem;
CostFunction* cost_function = new NumericDiffCostFunction(new CostFunctor(shape));
problem.AddResidualBlock(cost_function, NULL, x);
Solver::Options options;
options.minimizer_progress_to_stdout = true;
Solver::Summary summary;
Solve(options, &problem, &summary);
std::cout << summary.BriefReport() << endl; 这里我直接使用了数值差分的方法(NumericDiffCostFunction),而不是使用自动差分(AutoDiffCostFunction),是因为自动差分的CostFunctor是通过Template实现的,利用Template来实现Jacobian矩阵的计算使用的同一个结构,这样的话下方旋转矩阵就不能直接通过调用Dlib提供的三维坐标旋转接口,而是要将整个矩阵拆解开来实现(这边暂时没有细想到底能不能实现),因此出于简便,使用数值差分,在准确性上是会受到影响的。
并且注意到,具体的方法使用了Ridders(ceres::RIDDERS),而不是向前差分(ceres::FORWARD)或者中分(ceres::CENTRAL),因为用后两者进行处理的时候,LM算法\(\beta_{k+1}=\beta_k-(J^TJ+\lambda I)^{-1}J^Tr)\)的更新项为0,无法进行迭代,暂时没有想到原因,之前这里也被卡了很久。
[NOTE] 源代码中还有使用了CMinpack的版本,该版本不可用的原因也是使用了封装最浅的lmdif1_调用(返回结果INFO=4),该版本下使用的向前差分,如果改为使用lmdif_对其中的一些参数进行调整应该是可以实现的。
CostFunctor的构建
CostFunctor的构建是Ceres,也是这个程序,最重要的部分。首先我们需要先把想要计算的式子写出来:
\(Q=\sum_i^{LANDMARK\_NUM} \|q_i^{2d}-p_i^{2d}\|^2\)
\(Q=\sum_i^{LANDMARK\_NUM} \|q_i^{2d}-Map(R(yaw, roll, pitch)p_i^{3d}+T(t_x, t_y, t_z))\|^2\)。
其中:
- LANDMARK_NUM:该程序中为68,因为Dlib算法获得的特征点数为68;;
- \(q_i^{2d}\):通过Dlib获得的2维特征点坐标,大小为68的vector
- \(p_i^{2d}\):经过一系列变换得到的标准模型的2维特征点坐标,大小为68的vector
- \(p_i^{3d}\):标准模型的三维3维特征点坐标,大小为68的vector
; - \(R(yaw, roll, pitch)\):旋转矩阵;
- \(T(t_x, t_y, t_z)\):平移矩阵;
- \(Map()\):3维点转2维点的映射,如上所描述通过相机内参获得。
- \(\|·\|\):因为是两个2维点的差,我们使用欧几里得距离来作为2点的差。
Ceres当中的CostFunctor只需要写入平方以内的内容,因此我们如下构建:
struct CostFunctor {
public:
CostFunctor(full_object_detection _shape){ shape = _shape; }
bool operator()(const double* const x, double* residual) const {
/* Init landmarks to be transformed */
fitting_landmarks.clear();
for(std::vector::iterator iter=model_landmarks.begin(); iter!=model_landmarks.end(); ++iter)
fitting_landmarks.push_back(*iter);
transform(fitting_landmarks, x);
std::vector model_landmarks_2d;
landmarks_3d_to_2d(fitting_landmarks, model_landmarks_2d);
/* Calculate the energe (Euclid distance from two points) */
for(int i=0; i 其中的参数x是一个长度为6的数组,对应了我们要获得的6个参数。
初始值的选定
当前并没有多考虑这个因素,在landmark-fitting-cam程序中除了第一帧的初始值是提前设置好的以外,后续的初始值都是前一帧的最优值。
后面的表现都很好,但这第一帧确实会存在紊乱的情况。
因此后续优化可以考虑使用一个粗估计的初始值,因为对于这些迭代优化方法,初始值的选择决定了会不会陷入局部最优的情况。
测试结果
脸部效果:
输出工作环境: