目录
- 引言
- 控制反转
- 读写分离分库分表
- 理论基础
- 设计目标
- 现状调研
- 设计思路
- 实现之过五关斩六将
- 动态对象
- 动态模型缓存
- 数据源移植
- 查询表达式树深度移植
- 数据合并算法
- 事务支持
- 实际使用
- 展望未来
引言
前方硬核警告:全文干货11000+字,请耐心阅读
遥想去年这个时候,差不多刚刚毕业,如今正式工作差不多一年了。Colder开源快速开发框架从上次版本发布至今差不多有三个月了,Github的星星5个版本框架总共也有近800颗,QQ群从最初的一个人发展到现在的500人(吐槽下,人数上限了,太穷开不起SVIP,所以另开了一个,群号在文章末),这都是大家共同发展的结果,本框架能够帮助到大家鄙人就十分开心。但是,技术是不断发展的,本框架也必须适应潮流,不断升级才能够与时俱进,在实际意义上提高生产力。本系列框架从原始雏形(鄙人毕业设计)=>.NET45+Easyui=>.NET Core2.1+Easyui=>.NET45+AdminLTE=>.NET Core2.1+AdminLTE,这其中都是根据实际情况不断升级。例如鄙人最初的毕业设计搭建了框架的雏形(仓储层不够完善、界面较简陋),并不适合实际的生产开发,因此使用Easyui作为前端UI框架(控件丰富,使用简单),后又由于.NET Core的发展迅速,已经发展到2.0,其基础类库组件也相对比较成熟了,因此从.NET45迁移到.NET Core。后来发现Easyui的样式比较落后,给人一种过时古老的感觉,故而又将前端UI改为基于Bootstrap的AdminLTE,比较成熟主流并且开源。
但是,新的要求又出现了:
- 由于没有使用IOC导致各个类通过New导致的强耦合问题
- 数据库大数据量如何处理的问题
因此,本次版本更新主要就是为了解决上述的问题,即全面使用Autofac作为IOC容器实现解耦以及数据库读写分离分库分表(Sharding)支持。下面将分别介绍。
这次更新.NET45版本与.NET Core版本同步更新:
| .NET版本 | 前端UI | 地址 |
|---|---|---|
| Core2.2 | AdminLTE | https://github.com/Coldairarrow/Colder.Fx.Core.AdminLTE |
| .NET4.52 | AdminLTE | https://github.com/Coldairarrow/Colder.Fx.Net.AdminLTE |
控制反转
IOC(DI),即控制反转(依赖注入),相关概念大家应该都知道,并且大多数人应该都已经运用于实际。我就简单描述下,简单讲就是面向接口编程,通过接口来解除类之间的强耦合,方便开发维护测试。这个概念在JAVA开发中应该比较普遍,因为有Spring框架的正确引导,但是在.NET中可能开发人员的相关意识就没那么强,JAVA与.NET我这里不做评价,但是作为技术人员,天生就是不断学习的,好的东西当然要学习,毕竟技多不压身。
在.NET 领域中IOC框架主流有两个,即Autofac与Unity,这两个都是优秀的开源框架,经过一番考量后我最终选择了更加主流的(星星更多)Autofac。
关于Autofac的详细使用教程请看官方文档https://autofac.org/,我这里主要介绍下集成到本框架的思路以及用法。
传统使用方法通过手动注册具体的类实现某接口,这种做法显然不符合实际生产需求,需要一种自动注册的方式。本框架通过定义两个接口类:IDependency与ICircleDependency来作为依赖注入标记,所有需要使用IOC的类只需要继承其中一个接口就好了,其中IDependency是普通注入标记,支持属性注入但不支持循环依赖,ICircleDependency是循环依赖注入标记,支持循环依赖,实际使用中按需选择即可。下面代码就是自动注册的实现:
var builder = new ContainerBuilder();
var baseType = typeof(IDependency);
var baseTypeCircle = typeof(ICircleDependency);
//Coldairarrow相关程序集
var assemblys = BuildManager.GetReferencedAssemblies().Cast()
.Where(x => x.FullName.Contains("Coldairarrow")).ToList();
//自动注入IDependency接口,支持AOP
builder.RegisterAssemblyTypes(assemblys.ToArray())
.Where(x => baseType.IsAssignableFrom(x) && x != baseType)
.AsImplementedInterfaces()
.PropertiesAutowired()
.InstancePerLifetimeScope()
.EnableInterfaceInterceptors()
.InterceptedBy(typeof(Interceptor));
//自动注入ICircleDependency接口,循环依赖注入,不支持AOP
builder.RegisterAssemblyTypes(assemblys.ToArray())
.Where(x => baseTypeCircle.IsAssignableFrom(x) && x != baseTypeCircle)
.AsImplementedInterfaces()
.PropertiesAutowired(PropertyWiringOptions.AllowCircularDependencies)
.InstancePerLifetimeScope();
//注册Controller
builder.RegisterControllers(assemblys.ToArray())
.PropertiesAutowired();
//注册Filter
builder.RegisterFilterProvider();
//注册View
builder.RegisterSource(new ViewRegistrationSource());
//AOP
builder.RegisterType();
var container = builder.Build();
DependencyResolver.SetResolver(new AutofacDependencyResolver(container));
AutofacHelper.Container = container; 代码中有相关注释,使用方法推荐使用构造函数注入:

框架已在Business层与Web层全面使用DI,Util层、DataRepository层与Entity层不涉及业务逻辑,因此不使用DI。
读写分离分库分表
前面的IOC或许没啥可惊喜的,但是数据库读写分离分库分表应该不会让大家失望。接下来将阐述下框架支持Sharding的设计思路以及具体使用方法。
理论基础
数据库读写分离分库分表(以下简称Sharding),这并不是什么新概念,网上也有许多的相关资料。其根本就是为了解决一个问题,即数据库大数据量如何处理的问题。
当业务规模较小时,使用一个数据库即可满足,但是当业务规模不断扩大(数据量增大、用户数增多),数据库最终将会成为瓶颈(响应慢)。数据库瓶颈主要有三种情况:数据量不大但是读写频繁、数据量大但是读写不频繁以及数据量大并且读写频繁。
首先,为了解决数据量不大但是读写频繁导致的瓶颈,需要使用读写分离,所谓读写分离就是将单一的数据库分为多个数据库,一些数据库作为写库(主库),一些数据库作为读库(从库),并且开启主从复制(实时将写入的数据同步到从库中),这样将数据的读写分离后,将原来单一数据库用户的读写操作分散到多个数据库中,极大的降低了数据库压力,并且打多数情况下读操作要远多于写操作,因此实际运用中大多使用一主多从的模式。
其次,为了解决数据量大但是读写不频繁导致的瓶颈,需要使用分库分表。其实思想也是一样的,即分而治之,一切复杂系统都是通过合理的拆分从而有效的解决问题。分库分表就是将原来的单一数据库拆分为多个数据库,将原来的一张表拆分为多张表,这样表的数据量就将下来了,从而解决问题。但是,拆表并不是胡乱拆的,随便拆到时候数据都找不到,那还怎么玩,因此拆表需要按照一定的规则来进行。最简单的拆表规则,就是根据Id字段Hash后求余,这种方式使用简单但是扩容很麻烦(绝大多数都需要迁移,工作量巨大,十分麻烦),因此大多用于基本无需扩容的业务场景。后来经过一番研究后,发现可以使用雪花Id(分布式自增Id)来解决问题,雪花Id中自带了时间轴,因此在扩容时可以根据时间段来判断具体的分片规则,从而扩容时无需数据迁移,但是存在一定程度上的数据热点问题。最后,找到了葵花宝典-一致性哈希,关于一致性哈希的理论我这里就不献丑了,相关资料网上一大把。一致性哈希从一定程度上解决了普通哈希的扩容问题与数据热点问题,框架也支持使用一致性哈希分片规则。
最后,就是大BOSS,大数据量与大访问量,很简单只需要结合读写分离与分库分表即可,下表是具体业务场景与采用方案的关系
| 数据量\访问量 | 小 | 大 |
|-|-|-|
|小| 无| 读写分离 |
| 大 | 分库分表 |读写分离分库分表|
设计目标
首先定一个小目标(先赚他一个亿):支持多种数据库,使用简单,业务升级改动小。
有了目标就需要调查业界情况,实现Sharding,市面上主要分为两种,即使用中间件与客户端实现。
现状调研
中间件的优点是对客户端透明,即对于客户端来讲中间件就是数据库,因此对于业务改动影响几乎没有,但是对中间件的要求就很高,目前市面上比较主流成熟的就是mycat,其对MySQL支持比较好,但是对于其他数据库支持就比较无力(个人测试,没有深入研究,若有不妥请不要纠结),并且不支持EF,此方案行不通。其它类型数据库也有对应的中间件,但是都并不如意,自己开发更不现实,因此使用中间件方案行不通。
既然中间件行不通,那就只能选择客户端方案了。目前在JAVA中有大名鼎鼎的Sharding-JDBC,了解了下貌似很牛逼,可惜.NET中并没有Sharding-NET,但是有FreeSql,粗略了解了下是一个比较强大ORM框架,但我的框架原来底层是使用EF的,并且EF是.NET中主流的ORM框架,整体迁移到FreeSql不现实,因此最终没找到成熟的解决方案。
设计思路
最后终于到了最坏的情况,既没有完美的中间件方案,又没有现成的客户端方案,怎么办呢?放弃是不可能的,这辈子都不可能放弃的,终于,内心受到了党的启发,决定另起炉灶(既然没有现成的那就自己早造)、打扫干净屋子再请客(重构数据仓储层,实现Sharding)、一边倒(坚定目标不改变,不妥协),由于EF支持多种数据库,已经对底层SQL进行了抽象封装,因此决定基于EF打造一套读写分离分库分表方案。
数据库读写分离实现:读写分离比较简单,在仓储接口中已经明确定义了CRUD操作接口,其中增、删、改就是指写操作,写的时候按照具体的读写规则找到具体的写库进行写操作即可,读操作(查数据)按照具体的读规则找到具体的读库进行读即可。
数据库分库分表:分库还好说,使用不同的数据库即可,分表就比较麻烦了。首先实现分表的写操作,可以根据分片规则能够找到具体的物理表然后进行操作即可,实现比较容易。然后实现分表的读操作,这个就比较麻烦了,就好比前面的都是斗皇以下的在小打小闹,而这个却是斗帝(骑马),但是,作为一名合格的攻城狮是不怕斗帝的,遇到了困难不要慌,需要冷静思考处理。前面提到过,解决复杂问题就是一个字“拆”,首先联表查询就直接不考虑支持了(大数据量进行笛卡尔积就是一种愚蠢的做法,怎么优化都没用,物理数据库隔绝联表不现实,实现难度太大放弃)。接下来考虑最常用的方法:分页查询、数据筛选、最大值、最小值、平均值、数据量统计,EF中查询都是通过IQueryable接口实现的,IQueryable中主要包括了数据源(特定表)与关联的表达式树Expression,通过考虑将数据源与关联的表达式树移植到分表的IQueryable即可实现与抽象表相同的查询语句,最后将并发多线程查询分表的数据通过合并算法即可得到最终的实际数据。想法很美好,现实很残酷,下面为大家简单阐述下实现过程,可以说是过五关斩六将。
实现之过五关斩六将
动态对象
首先考虑分表的写操作,传统用法都有具体的实体类型进行操作,但是分表时,例如Base_UnitTest_0、Base_UnitTest_1、Base_UnitTest_2,这些表全部保存为实体类不现实,因此需要一种非泛型方法,后来在EF的关键类DbContext中找到DbEntityEntry Entry(object entity)方法,通过DbEntityEntry可以实现数据的增删改操作,又注意到传入参数是object,由此猜测EF支持非泛型操作,即只需要传入特定类型的object对象也行。例如抽象表是Base_UnitTest,实际需要映射到表Base_UnitTest_0,那么怎样将Base_UnitTest类型的对象转换成Base_UnitTest_0类型的对象?经过查阅资料,可以通过System.Reflection.Emit命名空间下的TypeBuilder在运行时创建动态类型,即可以在运行时创建Base_UnitTest_0类型,该类型拥有与Base_UnitTest完全一样的属性(因为表结构完全一样),创建了需要的类型,接下来只需要通过Json.NET将Base_UnitTest对象转为Base_UnitTest_0即可。实现到这里,原以为会顺利成功,但是并没有那么简单,EF直接报错“上下文不包含模型Base_UnitTest_0”,这明显就是模型的问题了,接下来进入下一关:EF动态模型缓存
动态模型缓存
通常都是通过继承DbContext重写OnModelCreating方法来注册实体模型,这里有个坑就是OnModelCreating只会执行一次,并最终生成DbCompiledModel然后将其缓存,后续创建的DbContext就会直接使用缓存的DbCompiledModel,由于最初注册实体模型的时候只有抽象类型Base_UnitTest,所有后续在使用Base_UnitTest_0对象的时候会报错。为了解决这个问题,需要自己管理DbCompiledModel缓存,实现过程比较麻烦,这里就不详细分析了,有兴趣的直接看源码即可。将缓存问题解决后,终于成功的实现了Base_UnitTest_0的增删改,这时,心里一喜(有戏)。实现了写操作(增、删、改)之后,接下来就是实现查询了,那么如何实现查询呢?EF中查询操作都是通过IQueryable接口实现的,IQueryable中包括了具体数据表的数据源和关联的查询表达式树,那么如何将IQueryable < Base_UnitTest >转换为IQueryable < Base_UnitTest_0 > 并且保留原始查询语句就成了关键问题。
数据源移植
根据经验,想一举同时移植数据源与表达式树应该不现实,实际情况也是如此,移植数据源,通过使用ExpressionVisitor可以找到根数据源,其实是一个ObjectQuery类型,并且在表达式树中是以ConstantExpression存在,同样通过ExpressionVisitor则可将原ObjectQuery替换为新的,实现过程省略10000字。
查询表达式树深度移植
数据源移植后,别以为就大功告成了,接下来进入一个深坑(最难点),表达式树移植,经过一番踩坑后发现,表达式树中的所有节点都是树状结构,任何一个查询(Where、OrderBy、Skip、Take等)在表达式树中都是以一个节点存在,并且一级扣一级,也就是说你改了数据源没用,因为数据源只是表达式树的根节点,下面的所有子节点还都是原来的根节点发的牙,并不能使用,那怎样才能用新数据源构建与原数据源一样的表达式树呢?经过如下分析:IQuryable中的所有操作都是MethodCallExpression一层一层包裹,那么我从外到内剥开方法,然后再从内到外包裹新的数据源,那不就模拟得一模一样了吗?(貌似有戏),想到先进后出脑子里直接就蹦出了数据结构中的栈,强大的.NET当然支持栈了,经过一番操作(奋斗几个晚上),此处省略10000字,最终完成IQueryable的移植,即从IQueryable < Base_UnitTest >转换为IQueryable < Base_UnitTest_0 > 并且保留原始查询语句。有了分表的IQueryable就能够获取分表的数据了,最后需要将获取的分表数据进行合并。
数据合并算法
分表后的数据合并算法主要参考了网上的一些资料,虽然分库分表的实现方式各不相同,但是思想都是差不多的,例如需要获取Count,只需要将各个分表的Count求和即可,最大值只需要所有分表的最大值的最大值即可,最小值只需要所有分表最小值的最小值即可,平均值需要所有分表的和然后除以所有分表的数据条数即可。最后比较麻烦的就是分页查询,分页查询需要分表排序后获取前N页的所有数据(不能直接获取某一页的数据,因为不一定就是那一页),最后将所有表的数据再进行分页即可。实现到这里,已经实现了增、删、改、查了,看似革命已经成功,其实还有最后的大BOSS:事务支持
事务支持
因为分表很可能不在同一个数据库中,因为普通的单库事务显然不能满足需求,原本框架中已经有分布式事务支持(多库事务),这里需要集成到Sharding中,实现过程省略10000字,最终黄天不负有心人终于实现了。
到这里,肯定有暴躁老哥坐不住了:你前面BBB那么多,说得那么牛逼,到底怎么用啊???,若文章到此为止,估计就是下图:

鄙人则回复如下:

深夜12点了,放松一下,最后介绍如何使用
实际使用
本框架支持数据库读写分离分库分表(即Sharding),并且支持主流关系型数据库(SQLServer、Oracle、MySQL、PostgreSQL),理论上只要EF支持那么本框架支持。
由于技术原因以及结合实际情况,目前本框架仅支持单表的Sharding,即支持单表的CRUD、分页、统计(数量、最大值、最小值、平均值),支持跨库(表分散在不同的数据库中,不同类型数据库也支持)。具体如何使用如下:
- Sharding配置
首先、要进行分库分表操作,那么必要的配置必不可少。配置代码如下:
ShardingConfigBootstrapper.Bootstrap()
//添加数据源
.AddDataSource("BaseDb", DatabaseType.SqlServer, dbBuilder =>
{
//添加物理数据库
dbBuilder.AddPhsicDb("BaseDb", ReadWriteType.ReadAndWrite);
})
//添加抽象数据库
.AddAbsDb("BaseDb", absTableBuilder =>
{
//添加抽象数据表
absTableBuilder.AddAbsTable("Base_UnitTest", tableBuilder =>
{
//添加物理数据表
tableBuilder.AddPhsicTable("Base_UnitTest_0", "BaseDb");
tableBuilder.AddPhsicTable("Base_UnitTest_1", "BaseDb");
tableBuilder.AddPhsicTable("Base_UnitTest_2", "BaseDb");
}, new ModShardingRule("Base_UnitTest", "Id", 3));
});上述代码中完成了Sharding的配置:
ShardingConfigBootstrapper.Bootstrap()在一个项目中只能执行一次,所以建议放到Application_Start中(ASP.NET Core中的Startup)
AddDataSource是指添加数据源,数据源可以看做抽象数据库,一个数据源包含了一组同类型的物理数据库,即实际的数据库。一个数据源至少包含一个物理数据库,多个物理数据库需要开启主从复制或主主复制,通过ReadWriteType(写、读、写和读)参数来指定数据库的操作类型,通常将写库作为主库,读库作为从库。同一个数据源中的物理数据库类型相同,表结构也相同。
配置好数据源后就可以通过AddAbsDb来添加抽象数据库,抽象数据库中需要添加抽象数据表。如上抽象表Base_UnitTest对应的物理表就是Base_UnitTest_0、Base_UnitTest_1与Base_UnitTest_2,并且这三张表都属于数据源BaseDb。分表配置当然需要分表规则(即通过一种规则找到具体数据在哪张表中)。
上述代码中使用了最简单的取模分片规则,
源码如下:
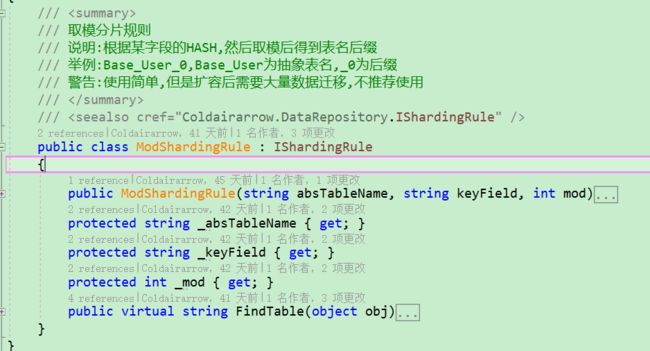
可以看到其使用方式及优缺点。
另外还有一致性HASH分片规则

雪花Id的mod分片规则
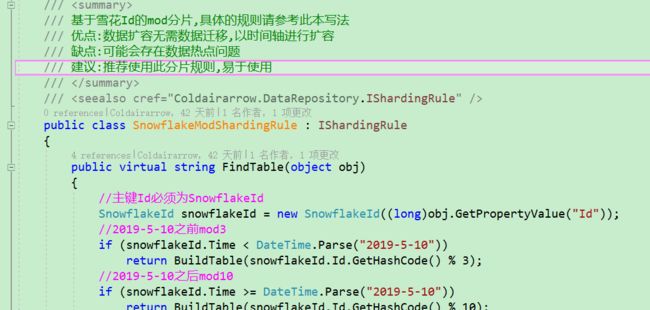
上述的分片规则各有优劣,都实现IShardingRule接口,实际上只需要实现FindTable方法即可实现自定义分片规则。
实际使用中个人推荐使用雪花Id的mod分片规,这也是为什么前面数据库设计规范中默认使用雪花Id作为数据库主键的原因(PS,之前版本使用GUID作为主键被各种嫌弃,这次看你们怎么说)
- 使用方式
配置完成,下面开始使用,使用方式非常简单,与平常使用基本一致
首先获取分片仓储接口IShardingRepository
IShardingRepository _db = DbFactory.GetRepository().ToSharding();然后即可进行数据操作:
Base_UnitTest _newData = new Base_UnitTest
{
Id = Guid.NewGuid().ToString(),
UserId = "Admin",
UserName = "超级管理员",
Age = 22
};
List _insertList = new List
{
new Base_UnitTest
{
Id = Guid.NewGuid().ToString(),
UserId = "Admin1",
UserName = "超级管理员1",
Age = 22
},
new Base_UnitTest
{
Id = Guid.NewGuid().ToString(),
UserId = "Admin2",
UserName = "超级管理员2",
Age = 22
}
};
//添加单条数据
_db.Insert(_newData);
//添加多条数据
_db.Insert(_insertList);
//清空表
_db.DeleteAll();
//删除单条数据
_db.Delete(_newData);
//删除多条数据
_db.Delete(_insertList);
//删除指定数据
_db.Delete(x => x.UserId == "Admin2");
//更新单条数据
_db.Update(_newData);
//更新多条数据
_db.Update(_insertList);
//更新单条数据指定属性
_db.UpdateAny(_newData, new List { "UserName", "Age" });
//更新多条数据指定属性
_db.UpdateAny(_insertList, new List { "UserName", "Age" });
//更新指定条件数据
_db.UpdateWhere(x => x.UserId == "Admin", x =>
{
x.UserId = "Admin2";
});
//GetList获取表的所有数据
var list=_db.GetList();
//GetIQPagination获取分页后的数据
var list=_db.GetIShardingQueryable().GetPagination(pagination);
//Max
var max=_db.GetIShardingQueryable().Max(x => x.Age);
//Min
var min=_db.GetIShardingQueryable().Min(x => x.Age);
//Average
var min=_db.GetIShardingQueryable().Average(x => x.Age);
//Count
var min=_db.GetIShardingQueryable().Count();
//事务,使用方式与普通事务一致
using (var transaction = _db.BeginTransaction())
{
_db.Insert(_newData);
var newData2 = _newData.DeepClone();
_db.Insert(newData2);
bool succcess = _db.EndTransaction().Success;
} 上述操作中表面上是操作Base_UnitTest表,实际上却在按照一定规则使用Base_UnitTest_0~2三张表,使分片对业务操作透明,极大提高开发效率,基本达成了最初定制的小目标。
具体使用方式请参考单元测试源码:
"\src\Coldairarrow.UnitTests\DataRepository\ShardingTest.cs"
最后放上简单的测试图:300W的表分成三张100W的表后效果
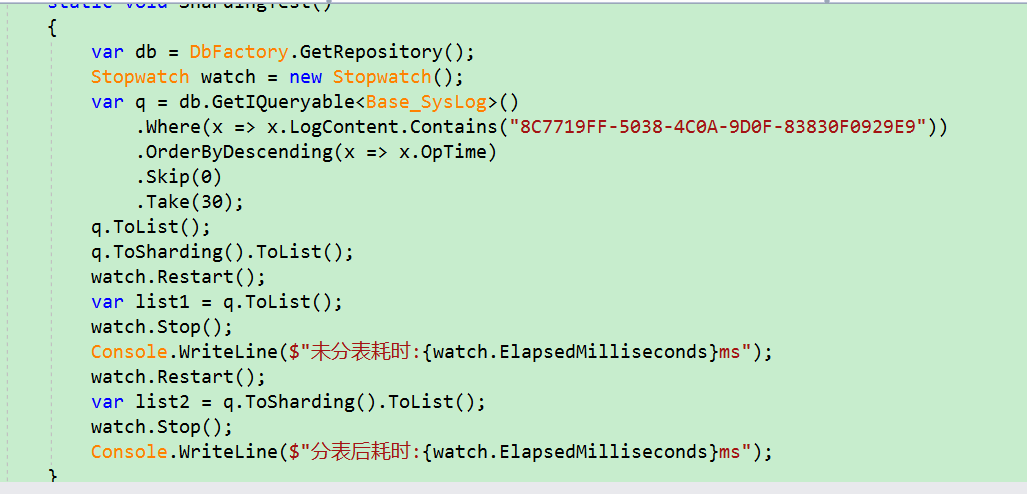
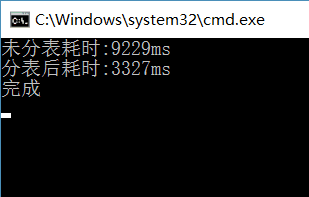
看来功夫没白费,效果明显(还不快点赞)
展望未来
结束也是是新的开始,版本后续计划采用前后端完全分离方案,前端使用vue-element-admin,后端以.NET Core为主,传统的.NET将逐步停止更新,敬请期待!
文章虽然结束了,但是技术永无止境,希望我的文档能够帮助到大家。
深夜码字,实属不易,文章中难免会出现一些纰漏,一些观点也不一定完全正确,还望各位大哥不吝赐教。
最后觉得文档不错,请点赞,Github请星星,若有各种疑问欢迎进群交流:
QQ群1(已满)
QQ群2:579202910