前言
今年有个现象,实时数仓建设突然就被大家所关注。我个人在公众号也写过和转载过几篇关于实时数据仓库的文章和方案。
但是对于实时数仓的狂热追求大可不必。
首先,在技术上几乎没有难点,基于强大的开源中间件实现实时数据仓库的需求已经变得没有那么困难。其次,实时数仓的建设一定是伴随着业务的发展而发展,武断的认为Kappa架构一定是最好的实时数仓架构是不对的。实际情况中随着业务的发展数仓的架构变得没有那么非此即彼。
在整个实时数仓的建设中,OLAP数据库的选型直接制约实时数仓的可用性和功能性。本文从业内几个典型的数仓建设和发展情况入手,从架构、技术选型和优缺点分别给大家分析现在市场上的开源OLAP引擎,旨在方便大家技术选型过程中能够根据实际业务进行选择。
管中窥豹-菜鸟/知乎/美团/网易严选实时数仓建设
为什么要构建实时数据仓库
传统的离线数据仓库将业务数据集中进行存储后,以固定的计算逻辑定时进行ETL和其它建模后产出报表等应用。离线数据仓库主要是构建T+1的离线数据,通过定时任务每天拉取增量数据,然后创建各个业务相关的主题维度数据,对外提供T+1的数据查询接口。计算和数据的实时性均较差,业务人员无法根据自己的即时性需要获取几分钟之前的实时数据。数据本身的价值随着时间的流逝会逐步减弱,因此数据发生后必须尽快的达到用户的手中,实时数仓的构建需求也应运而生。
总之就是一句话:时效性的要求。
阿里菜鸟的实时数仓设计
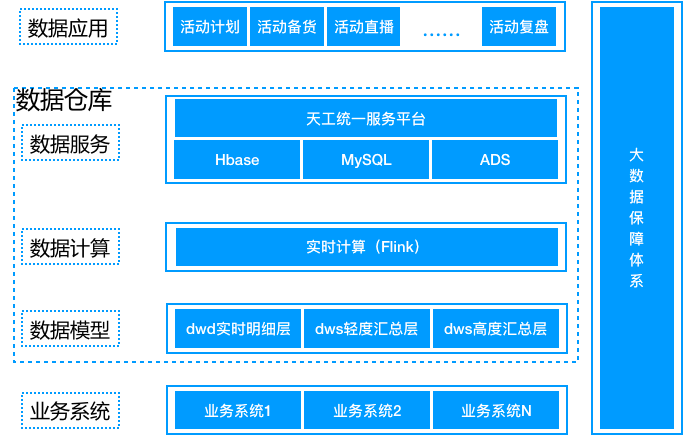
菜鸟的实时数仓整体设计如右图,基于业务系统的数据,数据模型是传统的分层汇总设计(明细/轻度汇总/高度汇总);计算引擎,选择的是阿里内部的Blink;数据访问用天工接入(天工是一个连接多种数据源的工具,目的是屏蔽大量的对各种数据库的直连);数据应用对应的是菜鸟的各个业务。
菜鸟的实时数仓的架构设计是一个很典型很经得起考验的设计。实时数据接入部分通过消息中间件(开源大数据领域非Kafka莫属,Pulsar是后起之秀),Hbase作为高度汇总的K-V查询辅助。
那么大量的对业务的直接支撑在哪里?在这里:ADS。
ADS(后更名为ADB,加入新特性)是阿里巴巴自主研发的海量数据实时高并发在线分析(Realtime OLAP)云计算数据库。(https://help.aliyun.com/document_detail/93838.html)
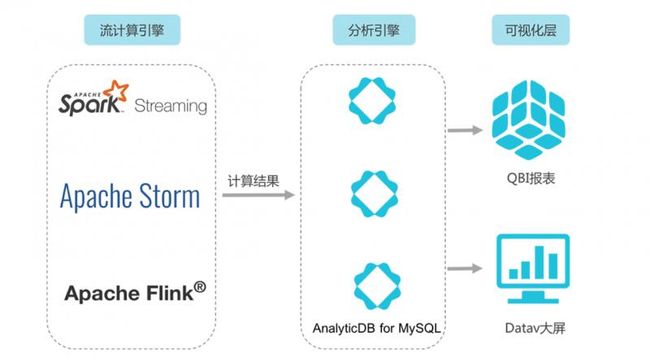
经典的实时数据清洗场景
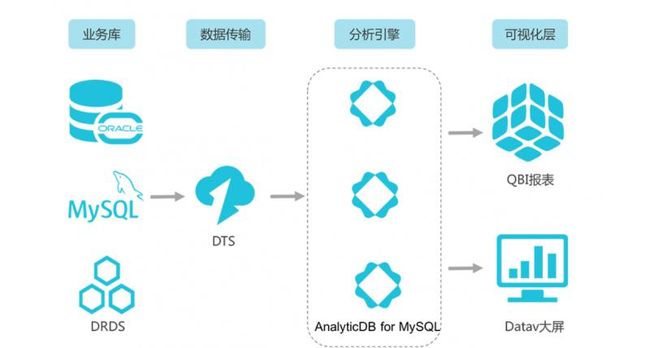
经典的实时数仓场景
在ADB的官方文档中给出了ADB的能力:
快
ADB采用MPP+DAG融合引擎,采用行列混存技术、自动索引等技术,可以快速扩容至数千节点。
灵活
随意调整节点数量和动态升降配实例规格。
易用
全面兼容MySQL协议和SQL
超大规模
全分布式结构,无任何单点设计,方便横向扩展增加SQL处理并发。
高并发写入
小规模的10万TPS写入能力,通过横向扩容节点提升至200万+TPS的写入能力。实时写入数据后,约1秒左右即可查询分析。单个表最大支持2PB数据,十万亿记录。
知乎的实时数仓设计
知乎的实时数仓实践以及架构的演进分为三个阶段:
- 实时数仓 1.0 版本,主题: ETL 逻辑实时化,技术方案:Spark Streaming
- 实时数仓 2.0 版本,主题:数据分层,指标计算实时化,技术方案:Flink Streaming
- 实时数仓未来展望:Streaming SQL 平台化,元信息管理系统化,结果验收自动化
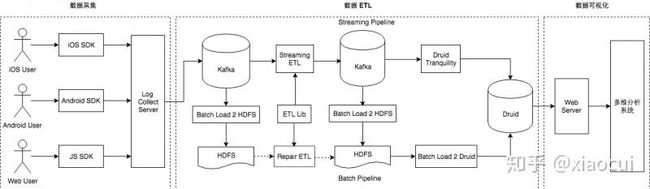
实时数仓 1.0 版本
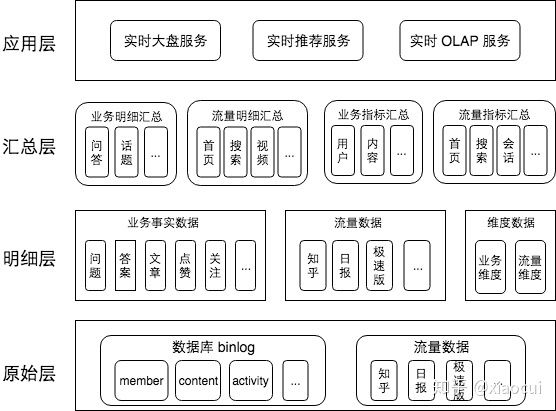
实时数仓 2.0 版本
在技术架构上,增加了指标汇总层,指标汇总层是由明细层或者明细汇总层通过聚合计算得到,这一层产出了绝大部分的实时数仓指标,这也是与实时数仓 1.0 最大的区别。
技术选型上,知乎根据不同业务场景选择了HBase 和 Redis 作为实时指标的存储引擎,在OLAP选型上,知乎选择了Druid。
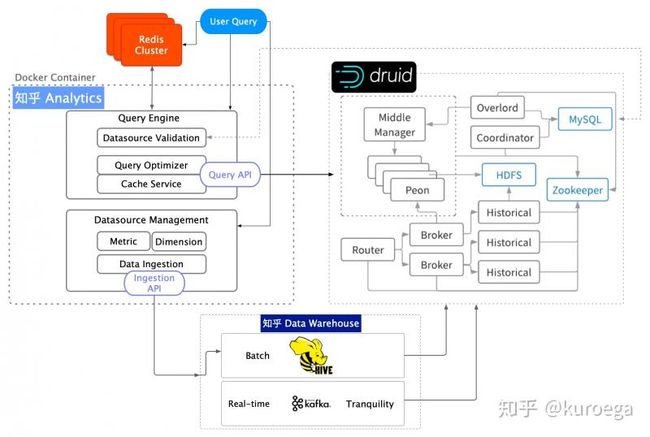
知乎实时多维分析平台架构
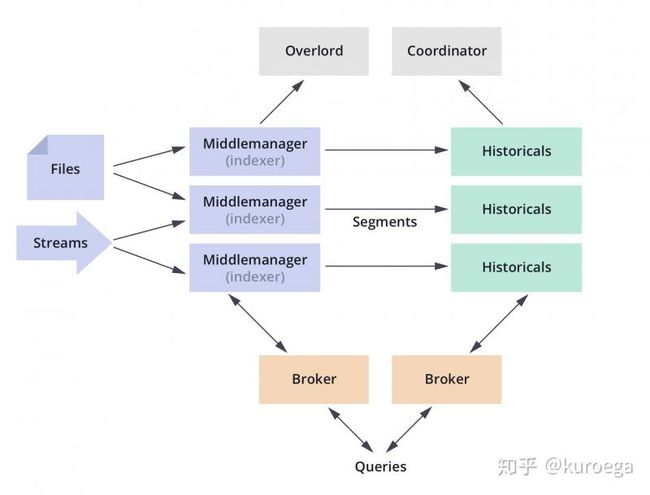
Druid 整体架构
Druid是一个高效的数据查询系统,主要解决的是对于大量的基于时序的数据进行聚合查询。数据可以实时摄入,进入到Druid后立即可查,同时数据是几乎是不可变。通常是基于时序的事实事件,事实发生后进入Druid,外部系统就可以对该事实进行查询。
Druid采用的架构:
- shared-nothing架构与lambda架构
Druid设计的三个原则:
- 快速查询:部分数据聚合(Partial Aggregate) + 内存化(In-Memory) + 索引(Index)
- 水平拓展能力:分布式数据(Distributed data)+并行化查询(Parallelizable Query)
- 实时分析:Immutable Past , Append-Only Future
如果你对Druid不了解,请参考这里:https://zhuanlan.zhihu.com/p/35146892
美团的实时数仓设计
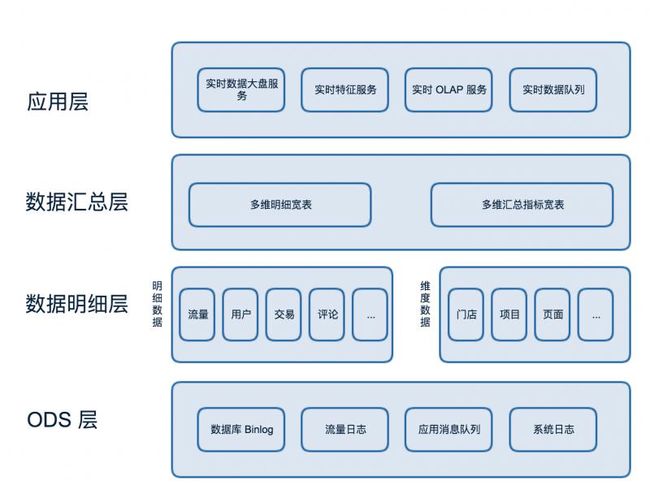
美团实时数仓数据分层架构
美团的技术方案由以下四层构成:
- ODS 层:Binlog 和流量日志以及各业务实时队列。
- 数据明细层:业务领域整合提取事实数据,离线全量和实时变化数据构建实时维度数据。
- 数据汇总层:使用宽表模型对明细数据补充维度数据,对共性指标进行汇总。
- App 层:为了具体需求而构建的应用层,通过 RPC 框架对外提供服务。
根据不同业务场景,实时数仓各个模型层次使用的存储方案和OLAP引擎如下:
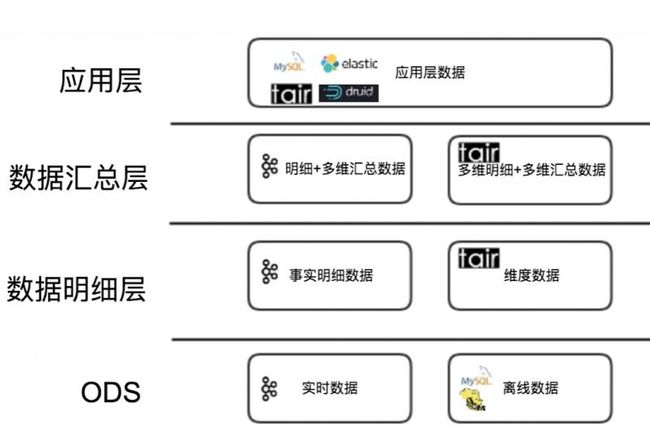
数据明细层 对于维度数据部分场景下关联的频率可达 10w+ TPS,我们选择 Cellar(美团内部分布式K-V存储系统,类似Redis) 作为存储,封装维度服务为实时数仓提供维度数据。
数据汇总层 对于通用的汇总指标,需要进行历史数据关联的数据,采用和维度数据一样的方案通过 Cellar 作为存储,用服务的方式进行关联操作。
数据应用层 应用层设计相对复杂,再对比了几种不同存储方案后。我们制定了以数据读写频率 1000 QPS 为分界的判断依据。对于读写平均频率高于 1000 QPS 但查询不太复杂的实时应用,比如商户实时的经营数据。采用 Cellar 为存储,提供实时数据服务。对于一些查询复杂的和需要明细列表的应用,使用 Elasticsearch 作为存储则更为合适。而一些查询频率低,比如一些内部运营的数据。 Druid 通过实时处理消息构建索引,并通过预聚合可以快速的提供实时数据 OLAP 分析功能。对于一些历史版本的数据产品进行实时化改造时,也可以使用 MySQL 存储便于产品迭代。
总之,在OLAP选型上同样以Druid为主。
网易严选的实时数仓设计
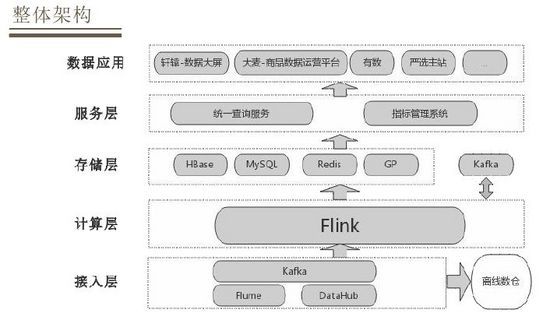
网易严选的实时数仓整体框架依据数据的流向分为不同的层次,接入层会依据各种数据接入工具 收集各个业务系统的数据。消息队列的数据既是离线数仓的原始数据,也是实时计算的原始数据,这样可以保证实时和离线的原始数据是统一的。 在计算层经过 Flink+实时计算引擎做一些加工处理,然后落地到存储层中不同存储介质当中。不同的存储介质是依据不同的应用场景来选择。框架中还有Flink和Kafka的交互,在数据上进行一个分层设计,计算引擎从Kafka中捞取数据做一些加工然后放回Kafka。在存储层加工好的数据会通过服务层的两个服务:统一查询、指标管理,统一查询是通过业务方调取数据接口的一个服务,指标管理是对数据指标的定义和管理工作。通过服务层应用到不同的数据应用,数据应用可能是我们的正式产品或者直接的业务系统。
基于以上的设计,技术选型如下:
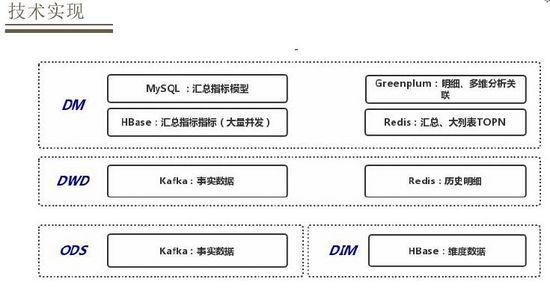
对于存储层会依据不同的数据层的特点选择不同的存储介质,ODS层和DWD层都是存储的一些实时数据,选择的是Kafka进行存储,在DWD层会关联一些历史明细数据,会将其放到 Redis 里面。在DIM层主要做一些高并发维度的查询关联,一般将其存放在HBase里面,对于DIM层比价复杂,需要综合考虑对于数据落地的要求以及具体的查询引擎来选择不同的存储方式。对于常见的指标汇总模型直接放在 MySQL 里面,维度比较多的、写入更新比较大的模型会放在HBase里面,还有明细数据需要做一些多维分析或者关联会将其存储在Greenplum里面,还有一种是维度比较多、需要做排序、查询要求比较高的,如活动期间用户的销售列表等大列表直接存储在Redis里面。
网易严选选择了GreenPulm、Hbase、Redis和MySQL作为数据的计算和透出层。
GreenPulm的技术特点如下:
- 支持海量数据存储和处理
- 支持Just In Time BI:通过准实时、实时的数据加载方式,实现数据仓库的实时更新,进而实现动态数据仓库(ADW),基于动态数据仓库,业务用户能对当前业务数据进行BI实时分析(Just In Time BI)
- 支持主流的sql语法,使用起来十分方便,学习成本低
- 扩展性好,支持多语言的自定义函数和自定义类型等
- 提供了大量的维护工具,使用维护起来很方便
- 支持线性扩展:采用MPP并行处理架构。在MPP结构中增加节点就可以线性提供系统的存储容量和处理能力
- 较好的并发支持及高可用性支持除了提供硬件级的Raid技术外,还提供数据库层Mirror机制保护,提供Master/Stand by机制进行主节点容错,当主节点发生错误时,可以切换到Stand by节点继续服务
- 支持MapReduce:一种大规模数据分析技术
- 数据库内部压缩
如果你对GreenPulm不熟悉可以参考这里:
https://www.cnblogs.com/wujin/p/6781264.html
总结
我们通过以上的分析可以看出,在整个实时数仓的建设中,业界已经有了成熟的方案。整体架构设计通过分层设计为OLAP查询分担压力,让出计算空间,复杂的计算统一在实时计算层做,避免给OLAP查询带来过大的压力。汇总计算教给OLAP数据库进行。我们可以这么说,在整个架构中实时计算一般是Spark+Flink配合,消息队列Kafka一家独大,整个大数据领域消息队列的应用中仍然处理垄断地位,后来者Pulsar想做出超越难度很大,Hbase、Redis和MySQL都在特定场景下有一席之地。
唯独在OLAP领域,百家争鸣,各有所长。大数据领域开源OLAP引擎包括但是不限于Hive、Druid、Hawq、Presto、Impala、Sparksql、Clickhouse、Greenplum等等。下一篇我们就各个开源OLAP引擎的优缺点和使用场景做出详细对比,让开发者进行技术选型时做到心中有数。

欢迎扫码关注我的公众号,回复【JAVAPDF】可以获得一份200页秋招面试题!