前言
在前三篇文章中,spark 源码分析之十九 -- DAG的生成和Stage的划分 剖析了DAG的构建和Stage的划分,spark 源码分析之二十 -- Stage的提交 剖析了TaskSet任务的提交,以及spark 源码分析之二十一 -- Task的执行细节剖析了Task执行的整个流程。在第三篇文章中侧重剖析了Task的整个执行的流程是如何的,对于Task本身是如何执行的 ResultTask 和 ShuffleMapTask两部分并没有做过多详细的剖析。本篇文章我们针对Task执行的细节展开,包括Task、ResultTask、ShuffleMapTask的深入剖析以及Spark底层的shuffle的实现机制等等。
Spark的任务划分为ResultTask和ShuffleMapTask两种任务。
其中ResultTask相对来说比较简单,只是读取上一个Stage的执行结果或者是从数据源读取任务,最终将结果返回给driver。
ShuffleMapTask相对复杂一些,中间涉及了shuffle过程。
紧接上篇
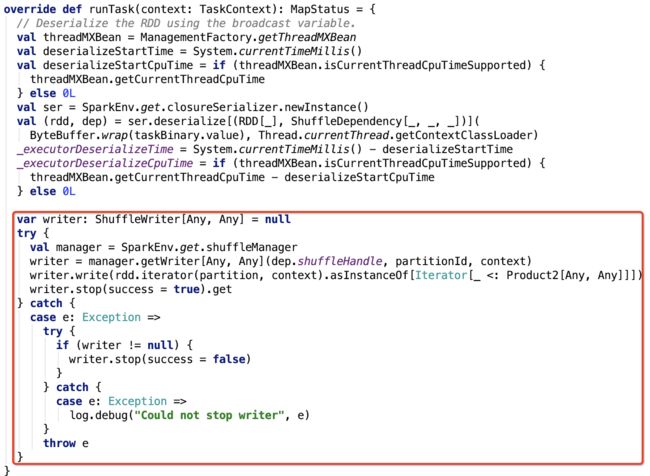
我们再来看一下,ResultTask和ShuffleMapTask的runTask方法。现在只关注数据处理逻辑,下面的两张图都做了标注。
ResultTask
类名:org.apache.spark.scheduler.ResultTask
其runTask方法如下:

ShuffleMapTask
类名:org.apache.spark.scheduler.ShuffleMapTask
其runTask方法如下:
两种Task执行的相同和差异
相同点
- 这两种Task都是在RDD的分区上执行的。
- 两种Task都需要调用父RDD的iterator方法来获取父RDD对应分区的数据。
- 这些数据可以直接来自于数据源,也可以直接来自于上一个ShuffleMapTask执行的结果。
- 当一个Stage中所有分区的Task都执行完毕,这个Stage才算执行完毕。
差异点
- ResultTask获取父RDD分区数据之后,把分区数据作为参数输入到action函数中,最终计算出特定的结果返回给driver。
- ShuffleMapTask获取父RDD分区数据之后,把分区数据作为参数传入分区函数,最终形成新的RDD中的分区数据,保存在各个Executor节点中,并将分区数据信息MapStatus返回给driver。
总结关注点
由两种Task执行的相同和差异点可以总结出,要想对这两种类型的任务执行有非常深刻的理解,必须搞明白shuffle 数据的读写。这也是spark 计算的核心的关注点 -- Shuffle的写操作、Shuffle的读操作。
shuffle数据分类
shuffle过程中写入Spark存储系统的数据分为两种,一种是shuffle数据,一种是shuffle索引数据,如下:

shuffle数据的管理类--IndexShuffleBlockResolver
下面说一下 IndexShuffleBlockResolver 类。这个类负责shuffle数据的获取和删除,以及shuffle索引数据的更新和删除。
IndexShuffleBlockResolver继承关系如下:

我们先来看父类ShuffleBlockResolver。
ShuffleBlockResolver
主要是负责根据逻辑的shuffle的标识(比如mapId、reduceId或shuffleId)来获取shuffle的block。shuffle数据一般都被File或FileSegment包装。
其接口定义如下:

其中,getBlockData根据shuffleId获取shuffle数据。
下面来看 IndexShuffleBlockResolver的实现。
IndexShuffleBlockResolver
这个类负责shuffle数据的获取和删除,以及shuffle索引数据的更新和删除。
类结构如下:

blockManager是executor上的BlockManager类。
transportCpnf主要是包含了关于shuffle的一些参数配置。
NOOP_REDUCE_ID是0,因为此时还不知道reduce的id。
核心方法如下:
1. 获取shuffle数据文件,源码如下,思路:根据blockManager的DiskBlockManager获取shuffle的blockId对应的物理文件。
![]()
2. 获取shuffle索引文件,源码如下,思路:根据blockManager的DiskBlockManager获取shuffle索引的blockId对应的物理文件。
![]()
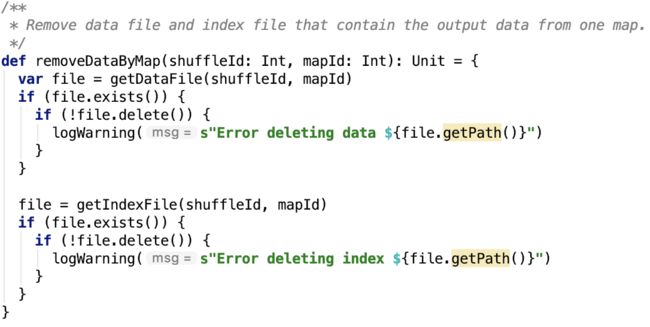
3.根据mapId将shuffle数据移除,源码如下,思路:根据shuffleId和mapId删除shuffle数据和索引文件
4.校验shuffle索引和数据,源码如下。

从上面可以看出,文件里第一个long型数是占位符,必为0.
后面的保存的数据是每一个block的大小,可以看出来,每次读的long型数,是前面所有block的大小总和。
所以,当前block的大小=这次读取到的offset - 上次读取到的offset
这种索引的设计非常巧妙。每一个block大小合起来就是整个文件的大小。每一个block的在整个文件中的offset也都记录在索引文件中。
5. 写索引文件,源码如下。

思路:首先先获取shuffle的数据文件并创建索引的临时文件。
获取索引文件的每一个block 的大小。如果索引存在,则更新新的索引数组,删除临时数据文件,返回。
若索引不存在,将新的数据的索引数据写入临时索引文件,最终删除历史数据文件和历史索引文件,然后临时数据文件和临时数据索引文件重命名为新的数据和索引文件。
这样的设计,确保了数据索引随着数据的更新而更新。
6. 根据shuffleId获取block数据,源码如下。
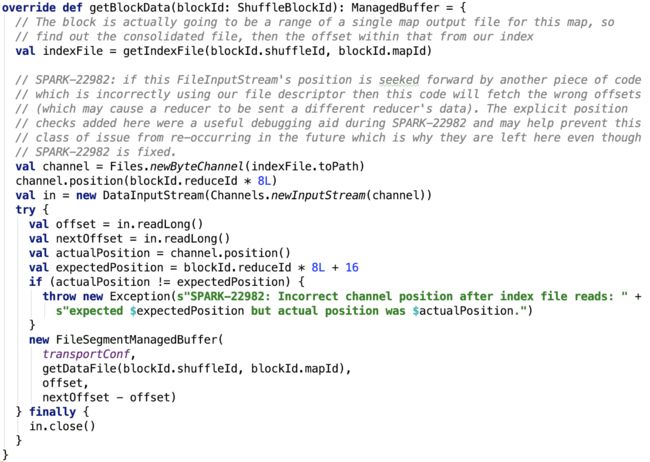
思路:
先获取shuffle数据的索引数据,然后调用position位上,获取block 的大小,然后初始化FileSegmentManagedBuffer,读取文件的对应segment的数据。
可以看出 reduceId就是block物理文件中的小的block(segment)的索引。
7. 停止blockResolver,空实现。
总结,在这个类中,可以学习到spark shuffle索引的设计思路,在工作中需要设计File和FileSegment的索引文件,这也是一种参考思路。
Shuffle的写数据前的准备工作
直接来看 org.apache.spark.scheduler.ShuffleMapTask 的runTask的关键代码如下:

这里的manager是SortShuffleManager,是ShuffleManager的唯一实现。
org.apache.spark.shuffle.sort.SortShuffleManager#getWriter 源码如下:

其中,numMapsForShuffle 定义如下:

它保存了shuffleID和mapper数量的映射关系。
获取ShuffleHandle
首先,先来了解一下ShuffleHandle类。
ShuffleHandle
下面大致了解一下ShuffleHandle的相关内容。
类说明:
这个类是Spark内部使用的一个类,包含了关于Shuffle的一些信息,主要给ShuffleManage 使用。本质上来说,它是一个标志位,除了包含一些用于shuffle的一些属性之外,没有其他额外的方法,用case class来实现更好一点。
类源码如下:
![]()
继承关系如下:
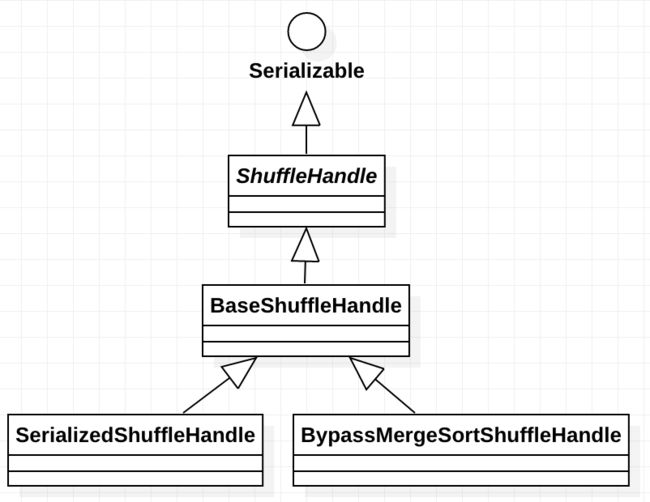
BaseShuffleHandle
全称:org.apache.spark.shuffle.BaseShuffleHandle
类说明:
它是ShuffleHandle的基础实现。
类源码如下:

下面来看一下它的两个子类实现。
BypassMergeSortShuffleHandle
全称:org.apache.spark.shuffle.sort.BypassMergeSortShuffleHandle
类说明:
如果想用于序列化的shuffle实现,可以使用这个标志类。其源码如下:

SerializedShuffleHandle
全称:org.apache.spark.shuffle.sort.SerializedShuffleHandle
类说明:
used to identify when we've chosen to use the bypass merge sort shuffle path.
类源码如下:

获取ShuffleHandle
在org.apache.spark.ShuffleDependency中有如下定义:

shuffleId是SparkContext生成的唯一全局id。
org.apache.spark.shuffle.sort.SortShuffleManager#registerShuffle 源码如下:

可以看出,mapper的数量等于父RDD的分区的数量。
下面,看一下使用bypassMergeSort的条件,即org.apache.spark.shuffle.sort.SortShuffleWriter#shouldBypassMergeSort 源码如下:

思路:首先如果父RDD没有启用mapSideCombine并且父RDD的结果分区数量小于bypassMergeSort阀值,则使用 bypassMergeSort。其中bypassMergeSort阀值 默认是200,可以通过 spark.shuffle.sort.bypassMergeThreshold 参数设定。
使用serializedShuffle的条件,即org.apache.spark.shuffle.sort.SortShuffleManager#canUseSerializedShuffle 源码如下:
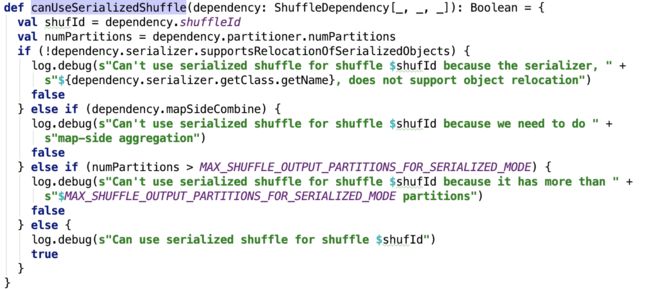
思路:序列化类支持支持序列化对象的迁移,并且不使用mapSideCombine操作以及父RDD的分区数不大于 (1 << 24) 即可使用该模式的shuffle。
根据ShuffleHandle获取ShuffleWriter
首先先对ShuffleWriter做一下简单说明。
ShuffleWriter
类说明:它负责将map任务的输出写入到shuffle系统。其继承关系如下,对应着ShuffleHandle的三种shuffle实现标志。

获取ShuffleWriter
org.apache.spark.shuffle.sort.SortShuffleManager#getWriter源码如下:

一个mapper对应一个writer,一个writer往一个分区上的写数据。
总结
本篇文章主要从Task 的差异和相同点出发,引出spark shuffle的重要性,接着对Spark shuffle数据的类型以及spark shuffle的管理类做了剖析。最后介绍了三种shuffle类型的标志位以及如何确定使用哪种类型的数据的。
接下来,正式进入mapper写数据部分。spark内部有三种实现,每一种写方式会有一篇文章专门剖析,我们逐一来看其实现机制。