数据仓库是伴随着信息技术和决策支持系统(DSS,Decision Support System)的发展而产生的,利用历史的操作数据进行管理和决策。
数据仓库是一个面向主题的、集成的、非易失的、随着时间变化的,用于支持管理人员决策的数据集合,数据仓库包含粒度化的企业数据,在不同的粒度级别上对数据进行聚合,这样,数据仓库中就存在最细节的原始数据、轻度聚合数据、高度聚合数据。
一,体系结构的变迁
早期的数据分析系统是通过“抽取”方式来处理数据,从在线事务处理(OLTP)数据库中,把相关的数据抽取到一个特定的数据库中。抽取式的优点是,把数据从OLTP环境中转移出来,对数据进行分析就不会影响原有的操作型数据库的性能了,但是,DSS分析员使用抽取式进行数据分析,主要面临以下三个问题:
- 缺乏数据可信度:数据可能没有公共的起始源数据,没有时间基准,这会导致不同的部门抽取的数据可能是不同的,得出的分析结果可能是截然不同的。
- 降低生产率:数据分散,需要重复抽取数据,并且数据的可信度得不到保证,降低了DSS分析员的工作效率
- 无法把数据转换为信息:抽取式数据缺乏集成性,也没有足够的数据供DSS分析员进行分析
为了克服抽取式的缺点,数据仓库应运而生,它把数据集成到单一的数据仓库中,各个部门从数据仓库中获取数据进行后续的业务分析。在数据仓库中,数据集成是非常重要的,当数据从操作型环境加载到数据仓库中时,必须进行数据集成,ETL(抽取、转换和加载)软件使得数据集成可以自动化进行。
在体系结构化环境中个,主要存在两种类型的数据:原始数据和导出数据。原始数据是维持企业日常运行的细节性数据,可以更新,是面向应用程序的操作型数据;而导出数据是经过汇总和计算来满足公司管理和决策的需要,是面向主题的,经过集成的,不直接更新的历史数据。
由于原始数据和导出数据之间存在巨大的差异,使得它们不能共存于同一个数据库,因此,必须把数据进行分离。在体系结构化环境中,有四个层次的数据:操作层(OLTP)、数据仓库层(DW)、数据集市层(DM)和个体层,操作层数据只包含面向应用的原始数据,数据仓库层存储不可更新的、已集成的历史数据,数据集市层是根据用户的需求为满足部门的特殊需求而建立的,数据个体层用于完成大多数启发式分析,是小规模的临时数据。
二,硬件利用模式
操作型环境和数据仓库环境之间,硬件的利用模式不同。在操作型处理中有多个波峰和波谷,总体来说,存在相对稳定的硬件利用模式;而在数据仓库环境中,存在一个根本不同的硬件利用模式,二元模式:要么利用全部硬件,要么根本不用硬件,因此,估算数据仓库环境中的硬件平均利用率是没有意义的。
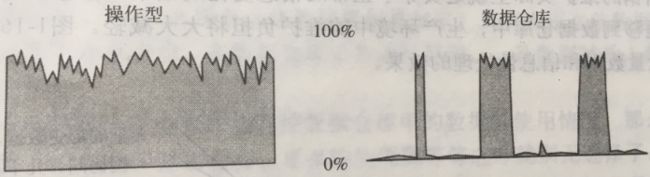
在OLTP环境中,响应时间要求非常苛刻,当响应时间变长时,用户体验就会变糟糕,而在数据仓库中,对响应速度的要求是非常宽松的,但是,快的响应速度也是非常必要的。
三,数据仓库的开发周期
数据仓库中的用户是数据分析人员(DSS分析人员),主要工作是定义和发现企业决策中使用的信息。数据分析人员的工作模式是一种发现模式,例如,给我看一下我想要的数据,然后,我才能告诉你我真正想要什么。换句话说,数据分析人员只有看到报表数据之后,才开始探讨如何使用数据。
数据仓库的开发是以数据开始,得到数据后,把数据集成,进而分析数据,这种以数据驱动的开发周期是螺旋式迭代进行的。
四,数据仓库的特性
数据仓库作为决策支持系统的单一数据源,是数据可重用和分析结果一致性的基础,它通过集成处理得到一致性的数据集,便于分析人员对数据的重复使用;通过分区把数据合理分布到不同的硬件存储器上,提高了数据访问的速度;提供了唯一的起始源数据,保证了分析结果的一致性。与传统的抽取式环境相比,数据仓库使得分析人员把精力放到数据的分析上,而不是数据的获取上,提高了分析的效率。
1,数据仓库是面向主题的
在数据仓库中,每一个主题都是以一组相关的表来实现的,表和表之间通过“外键”或者说公共关键字来联系起来。在确定数据仓库面向的主题之后,根据主题来设计相应的物理表。
数据仓库的数据模型是通过分为三个层次:
- ERD(实体关系图)是最顶层的概念模型,是实体关系的高度抽象,主要用于确定各个实体(或主题)之间的关系;
- 中间层是数据集成(DIS),用于对主要数据分组,设置数据的链接,确定数据的类型;
- 底层是物理模型,用于设计SQL Server的关系表
2,数据仓库是有结构的
在数据仓库中,数据存在着不同的细节级:原始数据(最细节的数据)、当前细节数据、轻度聚合数据和高度聚合数据,数据的粒度升级,是在数据由操作层传输到导出层进行的,一旦数据过期,就由原始数据导出当前细节数据,进而导出聚合数据。我们把聚合之后的数据称作缓存数据,这是为了定向提高某个主题或分析的查询性能。
不同的细节级,实际是由数据粒度的不同导致的,而粒度的升级通常是由时间、类别等属性聚合之后得到的。粒度会深刻地影响存储到数据仓库中的数据量的大小和数据仓库支持的查询类型。数据仓库中数据量的大小和粒度成反比,粒度越低,支持的查询范围越广泛,数据量越大。换句话说,低粒度可以回答任何问题,而高粒度会限制数据所能回答的问题。
由于高粒度会降低数据量,使得查询速度更快;而低粒度能够回答更多的问题,因此,在数据仓库中,一般根据数据被查询的频次,设计多重粒度,这样啊,既能使用高粒度快速响应高频问题,也能使用低粒度回答低频的问题。
3,分区设计
数据分区是把数据分散到可独立进行IO处理的分离的硬盘中,从根本上来说,分区的好处有两点:
- 利用分区,可以把IO分散到不同的硬盘上去,以并发方式访问数据,提高数据查询和更新的速度;
- 利用分区,可以把不常用的数据切换到廉价的大容量硬盘上去,而把常用的数据切换到性能优越的硬盘上去;
对数据分区,需要依据特定的数据列,通常以时间列作为分区列,把不同的时间区间的数据存放到不同的分区中去。
参考文档: