第91课:SparkStreaming基于Kafka Direct案例实战和内幕源码解密 java.lang.ClassNotFoundException 踩坑解决问题详细内幕版本
第91课:SparkStreaming基于Kafka Direct案例实战和内幕源码解密
/* * *王家林老师授课http://weibo.com/ilovepains */ 每天晚上20:00YY频道现场授课频道68917580
1、作业内容:SparkStreaming基于Kafka Direct方式实现,把Kafka Direct理解成为像hdfs的数据源,SparkStreaming直接读取数据进行流处理。
2、之前的spark集群环境:
spark 1.6.0
kafka_2.10-0.9.0.1
3、java开发SparkStreamingDirected,读取topic SparkStreamingDirected中的数据。
4、kafka中创建topic SparkStreamingDirected161,生产者输入数据。
5、将SparkStreamingDirected 在ecliplse中export打成jar包,提交spark运行,准备从kafka中读取数据。
6、结果spark submit运行中报java.lang.ClassNotFoundException,踩坑记录 :
-com.dt.spark.SparkApps.SparkStreaming.SparkStreamingOnKafkaDirected,要更新加上类名SparkStreamingOnKafkaDirected
-kafka/serializer/StringDecoder:submit时指定--jars /usr/local/kafka_2.10-0.9.0.1/libs/kafka_2.10-0.9.0.1.jar
-org.apache.spark.streaming.kafka.KafkaUtils:submit时指定--jars spark-streaming_2.10-1.6.0.jar
-com/yammer/metrics/Metrics: submit时指定--jars metrics-core-2.2.0.jar
7、将spark 1.6.0 及kafka_2.10-0.9.0.1 相关的jar指定以后,spark-submit提交仍然报错,新的报错提示:Exception in thread "main" java.lang.ClassCastException: kafka.cluster.BrokerEndPoint cannot be cast to kafka.cluster.Broker
。上stackoverflow.com及spark官网查询,这个是因为版本不兼容引起。官网提供的版本:Spark Streaming 1.6.1 is compatible with Kafka 0.8.2.1
7、因此,开始spark集群的版本升级:
spark 1.6.0升级到 spark1.6.1
kafka_2.10-0.9.0.1调整为 kafka_2.10-0.8.2.1
更新ecliplse的pom文件,源代码的依赖包更新为spark 1.6.1版本
8、spark1.6.1升级以后,从kafka中删除之前的topic SparkStreamingDirected,因为有些数据没有清彻底,为了一个干净的环境,重启以后,从kafka新建topic parkStreamingDirected161来进行实验。
9、kafka 中新建topic parkStreamingDirected161,生产者输入数据。
10、spark submit 提交脚本运行,对生产者输入数据进行流处理,spark1.6.1+kafka_2.10-0.8.2.1这次成功运行出结果。
具体的过程如下:
1.启动hdfs
2启动spark
3启动zookeeper
root@worker2:~# zkServer.sh start
JMX enabled by default
Using config: /usr/local/zookeeper-3.4.6/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
root@worker2:~# zkServer.sh status
JMX enabled by default
Using config: /usr/local/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: follower
root@worker2:~#
root@worker1:~# zkServer.sh start
JMX enabled by default
Using config: /usr/local/zookeeper-3.4.6/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
root@worker1:~# zkServer.sh status
JMX enabled by default
Using config: /usr/local/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: leader
root@worker1:~#
root@master:/usr/local/spark-1.6.0-bin-hadoop2.6/sbin# zkServer.sh start
JMX enabled by default
Using config: /usr/local/zookeeper-3.4.6/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
root@master:/usr/local/spark-1.6.0-bin-hadoop2.6/sbin# zkSever.sh status
zkSever.sh: command not found
root@master:/usr/local/spark-1.6.0-bin-hadoop2.6/sbin# zkServer.sh status
JMX enabled by default
Using config: /usr/local/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: follower
root@master:/usr/local/spark-1.6.0-bin-hadoop2.6/sbin#
4.启动kafka
nohup /usr/local/kafka_2.10-0.9.0.1/bin/kafka-server-start.sh /usr/local/kafka_2.10-
0.9.0.1/config/server.properties &
root@master:/usr/local/spark-1.6.0-bin-hadoop2.6/sbin# nohup /usr/local/kafka_2.10-0.9.0.1/bin/kafka-server-start.sh
/usr/local/kafka_2.10-0.9.0.1/config/server.properties &
[1] 3736
root@master:/usr/local/spark-1.6.0-bin-hadoop2.6/sbin# nohup: ignoring input and appending output to 鈥榥ohup.out鈥
root@master:/usr/local/spark-1.6.0-bin-hadoop2.6/sbin# jps
3792 Jps
3073 Master
2691 NameNode
3736 Kafka
2906 SecondaryNameNode
3180 HistoryServer
3439 QuorumPeerMain
root@master:/usr/local/spark-1.6.0-bin-hadoop2.6/sbin#
root@worker1:~# nohup /usr/local/kafka_2.10-0.9.0.1/bin/kafka-server-start.sh /usr/local/kafka_2.10-
0.9.0.1/config/server.properties &
[1] 2828
root@worker1:~# nohup: ignoring input and appending output to 鈥榥ohup.out鈥
root@worker1:~# jps
2884 Jps
2324 DataNode
2763 QuorumPeerMain
2508 Worker
2828 Kafka
root@worker1:~#
root@worker2:~# nohup /usr/local/kafka_2.10-0.9.0.1/bin/kafka-server-start.sh /usr/local/kafka_2.10-
0.9.0.1/config/server.properties &
[1] 2795
root@worker2:~# nohup: ignoring input and appending output to 鈥榥ohup.out鈥
root@worker2:~# jps
2535 QuorumPeerMain
2394 Worker
2795 Kafka
2847 Jps
2255 DataNode
root@worker2:~#
5 上传开发好的jar包
root@master:/usr/local/setup_tools# ls
apache-hive-1.2.1-bin.tar.gz mysql-connector-java-5.1.13-bin.jar spark-1.6.0-bin-hadoop2.6.tgz
apache-hive-1.2.1-src.tar.gz mysql-connector-java-5.1.36.zip spark-streaming-flume-sink_2.10-1.6.1.jar
commons-lang3-3.3.2.jar scala-2.10.4.tgz SparkStreamingOnKafkaDirected.jar
hadoop-2.6.0.tar.gz scala-library-2.10.4.jar zookeeper-3.4.6.tar.gz
jdk-8u60-linux-x64.tar.gz slf4j-1.7.21
kafka_2.10-0.9.0.1.tgz slf4j-1.7.21.zip
root@master:/usr/local/setup_tools# mv SparkStreamingOnKafkaDirected.jar /usr/local/IMF_testdata/
root@master:/usr/local/setup_tools# cd /usr/local/IMF_testdata/
root@master:/usr/local/IMF_testdata# ls
6.编辑提交的submit脚本
IMFSparkStreamingOnKafkaDirectedSubmit.sh
root@master:/usr/local/setup_scripts# cat IMFSparkStreamingOnKafkaDirectedSubmit.sh
/usr/local/spark-1.6.0-bin-hadoop2.6/bin/spark-submit --class com.dt.spark.SparkApps.SparkStreaming --master
spark://192.168.189.1:7077 /usr/local/IMF_testdata/SparkStreamingOnKafkaDirected.jar
root@master:/usr/local/setup_scripts#
7.kafka创建 topic
kafka-topics.sh --create --zookeeper master:2181,worker1:2181,worker2:2181 --replication-factor 1 --partitions 1 --
topic SparkStreamingDirected
root@master:/usr/local/setup_scripts# kafka-topics.sh --create --zookeeper master:2181,worker1:2181,worker2:2181 --
replication-factor 1 --partitions 1 --topic SparkStreamingDirected
Created topic "SparkStreamingDirected".
root@master:/usr/local/setup_scripts#
8.查看创建的topic SparkStreamingDirected
kafka-topics.sh --describe --zookeeper master:2181,worker1:2181,worker2:2181 --topic SparkStreamingDirected
root@master:/usr/local/setup_scripts# kafka-topics.sh --describe --zookeeper master:2181,worker1:2181,worker2:2181
--topic SparkStreamingDirected
Topic:SparkStreamingDirected PartitionCount:1 ReplicationFactor:1 Configs:
Topic: SparkStreamingDirected Partition: 0 Leader: 1 Replicas: 1 Isr: 1
root@master:/usr/local/setup_scripts#
9.运行spark submit
root@master:~# cd /usr/local/setup_scripts
root@master:/usr/local/setup_scripts# ls
addpartitions.sh IMFkafka.sh partitions10w sparkhistory_scp.sh yarn_scp.sh
hadoop_scp.sh IMFSparkStreamingOnKafkaDirectedSubmit.sh partitions3w spark_scp.sh zookeeper.out
host_scp.sh IMFsparksubmit.sh partitions3w-7w-10w ssh_config.sh
IMFFlume.sh IMFzookeeper.sh partitions5w-5w-10w ssh_scp.sh
root@master:/usr/local/setup_scripts# IMFSparkStreamingOnKafkaDirectedSubmit.sh
java.lang.ClassNotFoundException: com.dt.spark.SparkApps.SparkStreaming
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at org.apache.spark.util.Utils$.classForName(Utils.scala:174)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:689)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:181)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:206)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:121)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
root@master:/usr/local/setup_scripts#
解决:com.dt.spark.SparkApps.SparkStreaming.SparkStreamingOnKafkaDirected类的名字没有写,加上就OK了
root@master:/usr/local/setup_scripts# cat IMFSparkStreamingOnKafkaDirectedSubmit.sh
/usr/local/spark-1.6.0-bin-hadoop2.6/bin/spark-submit --class
com.dt.spark.SparkApps.SparkStreaming.SparkStreamingOnKafkaDirected --master spark://192.168.189.1:7077
/usr/local/IMF_testdata/SparkStreamingOnKafkaDirected.jar
root@master:/usr/local/setup_scripts#
报新的错误
Exception in thread "main" java.lang.NoClassDefFoundError: kafka/serializer/StringDecoder
at com.dt.spark.SparkApps.SparkStreaming.SparkStreamingOnKafkaDirected.main
(SparkStreamingOnKafkaDirected.java:70)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:731)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:181)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:206)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:121)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: java.lang.ClassNotFoundException: kafka.serializer.StringDecoder
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
解决,人工指定kafka jars包,
/usr/local/spark-1.6.0-bin-hadoop2.6/bin/spark-submit --class
com.dt.spark.SparkApps.SparkStreaming.SparkStreamingOnKafkaDirected --master spark://192.168.189.1:7077 --jars
/usr/local/kafka_2.10-0.9.0.1/libs/kafka_2.10-0.9.0.1.jar /usr/local/IMF_testdata/SparkStreamingOnKafkaDirected.jar
报新的错误
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/spark/streaming/kafka/KafkaUtils
at com.dt.spark.SparkApps.SparkStreaming.SparkStreamingOnKafkaDirected.main
(SparkStreamingOnKafkaDirected.java:68)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:731)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:181)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:206)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:121)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: java.lang.ClassNotFoundException: org.apache.spark.streaming.kafka.KafkaUtils
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
加入spark的包还是抱错
/usr/local/spark-1.6.0-bin-hadoop2.6/bin/spark-submit --class
com.dt.spark.SparkApps.SparkStreaming.SparkStreamingOnKafkaDirected --master spark://192.168.189.1:7077 --jars
/usr/local/kafka_2.10-0.9.0.1/libs/kafka_2.10-0.9.0.1.jar,/usr/local/spark-1.6.0-bin-hadoop2.6/lib/spark-assembly-
1.6.0-hadoop2.6.0.jar /usr/local/IMF_testdata/SparkStreamingOnKafkaDirected.jar
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/spark/streaming/kafka/KafkaUtils
at com.dt.spark.SparkApps.SparkStreaming.SparkStreamingOnKafkaDirected.main
(SparkStreamingOnKafkaDirected.java:68)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:731)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:181)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:206)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:121)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: java.lang.ClassNotFoundException: org.apache.spark.streaming.kafka.KafkaUtils
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
root@master:/usr/local/setup_tools# cp spark-streaming_2.10-1.6.0.jar /usr/local/spark-1.6.0-bin-hadoop2.6/lib/
root@master:/usr/local/setup_tools# cp spark-streaming-kafka_2.10-1.6.0.jar /usr/local/spark-1.6.0-bin-
hadoop2.6/lib/
root@master:/usr/local/setup_tools#
root@master:/usr/local/setup_scripts# chmod u+x IMFSparkStreamingOnKafkaDirectedSubmit.sh
root@master:/usr/local/setup_scripts# cat IMFSparkStreamingOnKafkaDirectedSubmit.sh
/usr/local/spark-1.6.0-bin-hadoop2.6/bin/spark-submit --class
com.dt.spark.SparkApps.SparkStreaming.SparkStreamingOnKafkaDirected --master spark://192.168.189.1:7077 --jars
/usr/local/kafka_2.10-0.9.0.1/libs/kafka_2.10-0.9.0.1.jar,/usr/local/spark-1.6.0-bin-hadoop2.6/lib/spark-
streaming_2.10-1.6.0.jar,/usr/local/spark-1.6.0-bin-hadoop2.6/lib/spark-streaming-kafka_2.10-
1.6.0.jar,/usr/local/spark-1.6.0-bin-hadoop2.6/lib/spark-assembly-1.6.0-hadoop2.6.0.jar
/usr/local/IMF_testdata/SparkStreamingOnKafkaDirected.jar
root@master:/usr/local/setup_scripts#
报新的错误
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/kafka/common/network/Send
at org.apache.spark.streaming.kafka.KafkaCluster.getPartitionMetadata(KafkaCluster.scala:122)
at org.apache.spark.streaming.kafka.KafkaCluster.getPartitions(KafkaCluster.scala:112)
at org.apache.spark.streaming.kafka.KafkaUtils$.getFromOffsets(KafkaUtils.scala:211)
at org.apache.spark.streaming.kafka.KafkaUtils$.createDirectStream(KafkaUtils.scala:484)
at org.apache.spark.streaming.kafka.KafkaUtils$.createDirectStream(KafkaUtils.scala:607)
at org.apache.spark.streaming.kafka.KafkaUtils.createDirectStream(KafkaUtils.scala)
at com.dt.spark.SparkApps.SparkStreaming.SparkStreamingOnKafkaDirected.main
(SparkStreamingOnKafkaDirected.java:68)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:731)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:181)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:206)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:121)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: java.lang.ClassNotFoundException: org.apache.kafka.common.network.Send
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
root@master:/usr/local/setup_scripts# cat IMFSparkStreamingOnKafkaDirectedSubmit.sh
/usr/local/spark-1.6.0-bin-hadoop2.6/bin/spark-submit --class
com.dt.spark.SparkApps.SparkStreaming.SparkStreamingOnKafkaDirected --master spark://192.168.189.1:7077 --jars
/usr/local/kafka_2.10-0.9.0.1/libs/kafka-clients-0.9.0.1.jar,/usr/local/kafka_2.10-0.9.0.1/libs/kafka_2.10-
0.9.0.1.jar,/usr/local/spark-1.6.0-bin-hadoop2.6/lib/spark-streaming_2.10-1.6.0.jar,/usr/local/spark-1.6.0-bin-
hadoop2.6/lib/spark-streaming-kafka_2.10-1.6.0.jar,/usr/local/spark-1.6.0-bin-hadoop2.6/lib/spark-assembly-1.6.0-
hadoop2.6.0.jar /usr/local/IMF_testdata/SparkStreamingOnKafkaDirected.jar
root@master:/usr/local/setup_scripts#
报新的错误
Exception in thread "main" java.lang.NoClassDefFoundError: com/yammer/metrics/Metrics
at kafka.metrics.KafkaMetricsGroup$class.newTimer(KafkaMetricsGroup.scala:85)
at kafka.consumer.FetchRequestAndResponseMetrics.newTimer(FetchRequestAndResponseStats.scala:26)
at kafka.consumer.FetchRequestAndResponseMetrics.
at kafka.consumer.FetchRequestAndResponseStats.
at kafka.consumer.FetchRequestAndResponseStatsRegistry$$anonfun$2.apply
(FetchRequestAndResponseStats.scala:60)
at kafka.consumer.FetchRequestAndResponseStatsRegistry$$anonfun$2.apply
(FetchRequestAndResponseStats.scala:60)
at kafka.utils.Pool.getAndMaybePut(Pool.scala:59)
at kafka.consumer.FetchRequestAndResponseStatsRegistry$.getFetchRequestAndResponseStats
(FetchRequestAndResponseStats.scala:64)
at kafka.consumer.SimpleConsumer.
at org.apache.spark.streaming.kafka.KafkaCluster.connect(KafkaCluster.scala:52)
at org.apache.spark.streaming.kafka.KafkaCluster$$anonfun$org$apache$spark$streaming$kafka$KafkaCluster$
$withBrokers$1.apply(KafkaCluster.scala:345)
at org.apache.spark.streaming.kafka.KafkaCluster$$anonfun$org$apache$spark$streaming$kafka$KafkaCluster$
$withBrokers$1.apply(KafkaCluster.scala:342)
at scala.collection.IndexedSeqOptimized$class.foreach(IndexedSeqOptimized.scala:33)
at scala.collection.mutable.WrappedArray.foreach(WrappedArray.scala:34)
at org.apache.spark.streaming.kafka.KafkaCluster.org$apache$spark$streaming$kafka$KafkaCluster$$withBrokers
(KafkaCluster.scala:342)
at org.apache.spark.streaming.kafka.KafkaCluster.getPartitionMetadata(KafkaCluster.scala:125)
at org.apache.spark.streaming.kafka.KafkaCluster.getPartitions(KafkaCluster.scala:112)
at org.apache.spark.streaming.kafka.KafkaUtils$.getFromOffsets(KafkaUtils.scala:211)
at org.apache.spark.streaming.kafka.KafkaUtils$.createDirectStream(KafkaUtils.scala:484)
at org.apache.spark.streaming.kafka.KafkaUtils$.createDirectStream(KafkaUtils.scala:607)
at org.apache.spark.streaming.kafka.KafkaUtils.createDirectStream(KafkaUtils.scala)
at com.dt.spark.SparkApps.SparkStreaming.SparkStreamingOnKafkaDirected.main
(SparkStreamingOnKafkaDirected.java:68)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:731)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:181)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:206)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:121)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: java.lang.ClassNotFoundException: com.yammer.metrics.Metrics
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
10.
加入新的jar包 zkclient-0.7.jar metrics-core-2.2.0.jar,
root@master:/usr/local/setup_scripts# cat IMFSparkStreamingOnKafkaDirectedSubmit.sh
/usr/local/spark-1.6.0-bin-hadoop2.6/bin/spark-submit --class
com.dt.spark.SparkApps.SparkStreaming.SparkStreamingOnKafkaDirected --master spark://192.168.189.1:7077 --jars
/usr/local/spark-1.6.0-bin-hadoop2.6/lib/spark-streaming-kafka_2.10-1.6.0.jar,/usr/local/kafka_2.10-
0.9.0.1/libs/kafka-clients-0.9.0.1.jar,/usr/local/kafka_2.10-0.9.0.1/libs/kafka_2.10-0.9.0.1.jar,/usr/local/spark-
1.6.0-bin-hadoop2.6/lib/spark-streaming_2.10-1.6.0.jar,/usr/local/kafka_2.10-0.9.0.1/libs/metrics-core-
2.2.0.jar,/usr/local/kafka_2.10-0.9.0.1/libs/zkclient-0.7.jar,/usr/local/spark-1.6.0-bin-hadoop2.6/lib/spark-
assembly-1.6.0-hadoop2.6.0.jar /usr/local/IMF_testdata/SparkStreamingOnKafkaDirected.jar
root@master:/usr/local/setup_scripts#
新的报错
Exception in thread "main" java.lang.ClassCastException: kafka.cluster.BrokerEndPoint cannot be cast to
kafka.cluster.Broker
at org.apache.spark.streaming.kafka.KafkaCluster$$anonfun$2$$anonfun$3$$anonfun$apply$6$$anonfun$apply
$7.apply(KafkaCluster.scala:90)
at scala.Option.map(Option.scala:145)
at org.apache.spark.streaming.kafka.KafkaCluster$$anonfun$2$$anonfun$3$$anonfun$apply$6.apply
(KafkaCluster.scala:90)
at org.apache.spark.streaming.kafka.KafkaCluster$$anonfun$2$$anonfun$3$$anonfun$apply$6.apply
(KafkaCluster.scala:87)
at scala.collection.TraversableLike$$anonfun$flatMap$1.apply(TraversableLike.scala:251)
at scala.collection.TraversableLike$$anonfun$flatMap$1.apply(TraversableLike.scala:251)
at scala.collection.IndexedSeqOptimized$class.foreach(IndexedSeqOptimized.scala:33)
at scala.collection.mutable.WrappedArray.foreach(WrappedArray.scala:34)
at scala.collection.TraversableLike$class.flatMap(TraversableLike.scala:251)
at scala.collection.AbstractTraversable.flatMap(Traversable.scala:105)
at org.apache.spark.streaming.kafka.KafkaCluster$$anonfun$2$$anonfun$3.apply(KafkaCluster.scala:87)
at org.apache.spark.streaming.kafka.KafkaCluster$$anonfun$2$$anonfun$3.apply(KafkaCluster.scala:86)
at scala.collection.TraversableLike$$anonfun$flatMap$1.apply(TraversableLike.scala:251)
at scala.collection.TraversableLike$$anonfun$flatMap$1.apply(TraversableLike.scala:251)
at scala.collection.immutable.Set$Set1.foreach(Set.scala:74)
at scala.collection.TraversableLike$class.flatMap(TraversableLike.scala:251)
at scala.collection.AbstractTraversable.flatMap(Traversable.scala:105)
at org.apache.spark.streaming.kafka.KafkaCluster$$anonfun$2.apply(KafkaCluster.scala:86)
at org.apache.spark.streaming.kafka.KafkaCluster$$anonfun$2.apply(KafkaCluster.scala:85)
at scala.util.Either$RightProjection.flatMap(Either.scala:523)
at org.apache.spark.streaming.kafka.KafkaCluster.findLeaders(KafkaCluster.scala:85)
at org.apache.spark.streaming.kafka.KafkaCluster.getLeaderOffsets(KafkaCluster.scala:179)
at org.apache.spark.streaming.kafka.KafkaCluster.getLeaderOffsets(KafkaCluster.scala:161)
at org.apache.spark.streaming.kafka.KafkaCluster.getLatestLeaderOffsets(KafkaCluster.scala:150)
at org.apache.spark.streaming.kafka.KafkaUtils$$anonfun$5.apply(KafkaUtils.scala:215)
at org.apache.spark.streaming.kafka.KafkaUtils$$anonfun$5.apply(KafkaUtils.scala:211)
at scala.util.Either$RightProjection.flatMap(Either.scala:523)
at org.apache.spark.streaming.kafka.KafkaUtils$.getFromOffsets(KafkaUtils.scala:211)
at org.apache.spark.streaming.kafka.KafkaUtils$.createDirectStream(KafkaUtils.scala:484)
at org.apache.spark.streaming.kafka.KafkaUtils$.createDirectStream(KafkaUtils.scala:607)
at org.apache.spark.streaming.kafka.KafkaUtils.createDirectStream(KafkaUtils.scala)
at com.dt.spark.SparkApps.SparkStreaming.SparkStreamingOnKafkaDirected.main
(SparkStreamingOnKafkaDirected.java:68)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:731)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:181)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:206)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:121)
原因kafka版本不兼容
http://stackoverflow.com/questions/34145483/spark-streaming-kafka-stream
The problem was related the wrong spark-streaming-kafka version.
As described in the documentation
Kafka: Spark Streaming 1.5.2 is compatible with Kafka 0.8.2.1
重新下载kafka kafka_2.10-0.8.2.1
https://www.apache.org/dyn/closer.cgi?path=/kafka/0.8.2.1/kafka_2.10-0.8.2.1.tgz
10.启动新版本kafka
nohup kafka-server-start.sh /usr/local/kafka_2.10-0.8.2.1/config/server.properties &
root@worker2:/usr/local# nohup kafka-server-start.sh /usr/local/kafka_2.10-0.8.2.1/config/server.properties &
[1] 3175
root@worker2:/usr/local# nohup: ignoring input and appending output to 鈥榥ohup.out鈥
root@worker2:/usr/local# jps
3175 Kafka
2410 Worker
2474 QuorumPeerMain
3227 Jps
2283 DataNode
root@worker2:/usr/local#
kafka创建 topic
root@worker2:/usr/local# kafka-topics.sh --create --zookeeper master:2181,worker1:2181,worker2:2181 --replication-
factor 1 --partitions 1 --topic SparkStreamingDirected
Error while executing topic command : Topic "SparkStreamingDirected" already exists.
[2016-04-30 13:23:42,688] ERROR kafka.common.TopicExistsException: Topic "SparkStreamingDirected" already exists.
at kafka.admin.AdminUtils$.createOrUpdateTopicPartitionAssignmentPathInZK(AdminUtils.scala:253)
at kafka.admin.AdminUtils$.createTopic(AdminUtils.scala:237)
at kafka.admin.TopicCommand$.createTopic(TopicCommand.scala:105)
at kafka.admin.TopicCommand$.main(TopicCommand.scala:60)
at kafka.admin.TopicCommand.main(TopicCommand.scala)
(kafka.admin.TopicCommand$)
root@worker2:/usr/local#
root@worker2:/usr/local# kafka-topics.sh --describe --zookeeper master:2181,worker1:2181,worker2:2181 --topic
SparkStreamingDirected
Topic:SparkStreamingDirected PartitionCount:1 ReplicationFactor:1 Configs:
Topic: SparkStreamingDirected Partition: 0 Leader: 1 Replicas: 1 Isr: 1
root@worker2:/usr/local#
root@master:/usr/local/spark-1.6.1-bin-hadoop2.6/sbin# kafka-topics.sh --delete --zookeeper
master:2181,worker1:2181,worker2:2181 --topic SparkStreamingDirected
Topic SparkStreamingDirected is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
root@master:/usr/local/spark-1.6.1-bin-hadoop2.6/sbin#
root@master:/usr/local/kafka_2.10-0.8.2.1/tmp/kafka-logs# ls
cleaner-offset-checkpoint recovery-point-offset-checkpoint replication-offset-checkpoint
root@master:/usr/local/kafka_2.10-0.8.2.1/tmp/kafka-logs# rm cleaner-offset-checkpoint
root@master:/usr/local/kafka_2.10-0.8.2.1/tmp/kafka-logs# ls
recovery-point-offset-checkpoint replication-offset-checkpoint
root@master:/usr/local/kafka_2.10-0.8.2.1/tmp/kafka-logs# rm recovery-point-offset-checkpoint
root@master:/usr/local/kafka_2.10-0.8.2.1/tmp/kafka-logs# rm replication-offset-checkpoint
11.start kafka
root@master:/usr/local/kafka_2.10-0.8.2.1/bin# nohup ./kafka-server-start.sh /usr/local/kafka_2.10-
0.8.2.1/config/server.properties &
[1] 3929
root@master:/usr/local/kafka_2.10-0.8.2.1/bin# nohup: ignoring input and appending output to 鈥榥ohup.out鈥
root@master:/usr/local/kafka_2.10-0.8.2.1/bin# jps
3568 QuorumPeerMain
2932 NameNode
3929 Kafka
3306 Master
3147 SecondaryNameNode
3403 HistoryServer
3997 Jps
root@master:/usr/local/kafka_2.10-0.8.2.1/bin#
root@worker1:/usr/local/kafka_2.10-0.8.2.1/bin# nohup ./kafka-server-start.sh /usr/local/kafka_2.10-
0.8.2.1/config/server.properties &
[1] 2847
root@worker1:/usr/local/kafka_2.10-0.8.2.1/bin# nohup: ignoring input and appending output to 鈥榥ohup.out鈥
root@worker1:/usr/local/kafka_2.10-0.8.2.1/bin# jps
2771 QuorumPeerMain
2894 Jps
2494 DataNode
2847 Kafka
root@worker1:/usr/local/kafka_2.10-0.8.2.1/bin#
root@worker2:/usr/local/kafka_2.10-0.8.2.1/bin# nohup ./kafka-server-start.sh /usr/local/kafka_2.10-
0.8.2.1/config/server.properties &
[1] 2744
root@worker2:/usr/local/kafka_2.10-0.8.2.1/bin# nohup: ignoring input and appending output to 鈥榥ohup.out鈥
root@worker2:/usr/local/kafka_2.10-0.8.2.1/bin# jps
2786 Jps
2564 Worker
2744 Kafka
2633 QuorumPeerMain
2447 DataNode
root@worker2:/usr/local/kafka_2.10-0.8.2.1/bin#
root@master:/usr/local/kafka_2.10-0.8.2.1/bin# ./kafka-topics.sh --create --zookeeper
master:2181,worker1:2181,worker2:2181 --replication-factor 1 --partitions 1 --topic SparkStreamingDirected
Error while executing topic command Topic "SparkStreamingDirected" already exists.
kafka.common.TopicExistsException: Topic "SparkStreamingDirected" already exists.
at kafka.admin.AdminUtils$.createOrUpdateTopicPartitionAssignmentPathInZK(AdminUtils.scala:187)
at kafka.admin.AdminUtils$.createTopic(AdminUtils.scala:172)
at kafka.admin.TopicCommand$.createTopic(TopicCommand.scala:93)
at kafka.admin.TopicCommand$.main(TopicCommand.scala:55)
at kafka.admin.TopicCommand.main(TopicCommand.scala)
root@master:/usr/local/kafka_2.10-0.8.2.1/bin# ./kafka-topics.sh --describe --zookeeper
master:2181,worker1:2181,worker2:2181 --topic SparkStreamingDirected
Topic:SparkStreamingDirected PartitionCount:1 ReplicationFactor:1 Configs:
Topic: SparkStreamingDirected Partition: 0 Leader: 1 Replicas: 1 Isr: 1
root@master:/usr/local/kafka_2.10-0.8.2.1/bin#
生产者输入数据
kafka-console-producer.sh --broker-list master:9092,worker1:9092,worker2:9092 --topic SparkStreamingDirected
15. spark 1.6.0 升级到 spark 1.6.1版本,kafka调整到版本2.10-0.8.2.1以后,报错终于有了新变化,
root@master:/usr/local/setup_scripts# IMFSparkStreamingOnKafkaDirectedSubmit.sh
16/04/30 19:27:59 INFO spark.SparkContext: Running Spark version 1.6.1
16/04/30 19:28:00 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using
builtin-java classes where applicable
16/04/30 19:28:00 INFO spark.SecurityManager: Changing view acls to: root
16/04/30 19:28:00 INFO spark.SecurityManager: Changing modify acls to: root
16/04/30 19:28:00 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with
view permissions: Set(root); users with modify permissions: Set(root)
16/04/30 19:28:01 INFO util.Utils: Successfully started service 'sparkDriver' on port 37293.
16/04/30 19:28:02 INFO slf4j.Slf4jLogger: Slf4jLogger started
16/04/30 19:31:52 INFO utils.VerifiableProperties: Property zookeeper.connect is overridden to
Exception in thread "main" org.apache.spark.SparkException: org.apache.spark.SparkException: Error getting partition
metadata for 'SparkStreamingDirected'. Does the topic exist?
org.apache.spark.SparkException: Error getting partition metadata for 'SparkStreamingDirected'. Does the topic
exist?
org.apache.spark.SparkException: Error getting partition metadata for 'SparkStreamingDirected'. Does the topic
exist?
at org.apache.spark.streaming.kafka.KafkaCluster$$anonfun$checkErrors$1.apply(KafkaCluster.scala:366)
at org.apache.spark.streaming.kafka.KafkaCluster$$anonfun$checkErrors$1.apply(KafkaCluster.scala:366)
at scala.util.Either.fold(Either.scala:97)
at org.apache.spark.streaming.kafka.KafkaCluster$.checkErrors(KafkaCluster.scala:365)
at org.apache.spark.streaming.kafka.KafkaUtils$.getFromOffsets(KafkaUtils.scala:222)
at org.apache.spark.streaming.kafka.KafkaUtils$.createDirectStream(KafkaUtils.scala:484)
at org.apache.spark.streaming.kafka.KafkaUtils$.createDirectStream(KafkaUtils.scala:607)
at org.apache.spark.streaming.kafka.KafkaUtils.createDirectStream(KafkaUtils.scala)
at com.dt.spark.SparkApps.SparkStreaming.SparkStreamingOnKafkaDirected.main
(SparkStreamingOnKafkaDirected.java:68)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:731)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:181)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:206)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:121)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
16/04/30 19:31:52 INFO spark.SparkContext: Invoking stop() from shutdown hoo
16.重新更新pom文件
17.换个topic名字SparkStreamingDirected161
kafka-topics.sh --create --zookeeper master:2181,worker1:2181,worker2:2181 --replication-factor 1 --partitions 1 --
topic SparkStreamingDirected161
root@master:/usr/local/setup_scripts# kafka-topics.sh --create --zookeeper master:2181,worker1:2181,worker2:2181 --
replication-factor 1 --partitions 1 --topic SparkStreamingDirected161
Created topic "SparkStreamingDirected161".
root@master:/usr/local/setup_scripts# kafka-topics.sh --describe --zookeeper master:2181,worker1:2181,worker2:2181
--topic SparkStreamingDirected161
Topic:SparkStreamingDirected161 PartitionCount:1 ReplicationFactor:1 Configs:
Topic: SparkStreamingDirected161 Partition: 0 Leader: 2 Replicas: 2 Isr: 2
root@master:/usr/local/setup_scripts#
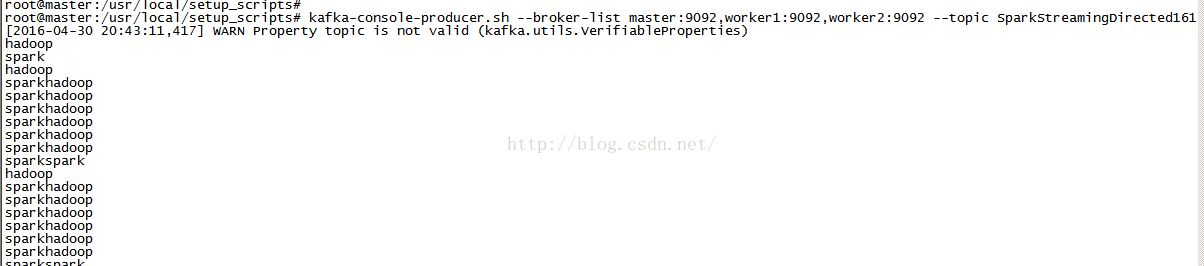
kafka-console-producer.sh --broker-list master:9092,worker1:9092,worker2:9092 --topic SparkStreamingDirected161
root@master:/usr/local/setup_scripts# kafka-console-producer.sh --broker-list master:9092,worker1:9092,worker2:9092
--topic SparkStreamingDirected161
[2016-04-30 20:43:11,417] WARN Property topic is not valid (kafka.utils.VerifiableProperties)
hadoop
spark
hadoop
sparkhadoop
sparkhadoop
sparkhadoop
sparkhadoop
sparkhadoop
sparkhadoop
sparkspark
hadoop
sparkhadoop
sparkhadoop
sparkhadoop
sparkhadoop
sparkhadoop
sparkhadoop
sparkspark
hadoop
sparkhadoop
sparkhadoop
sparkhadoop
root@master:/usr/local/setup_scripts# cat IMFSparkStreamingOnKafkaDirectedSubmit161.sh
/usr/local/spark-1.6.1-bin-hadoop2.6/bin/spark-submit --class
com.dt.spark.SparkApps.SparkStreaming.SparkStreamingOnKafkaDirected --master spark://192.168.189.1:7077 --jars
/usr/local/spark-1.6.1-bin-hadoop2.6/lib/spark-streaming-kafka_2.10-1.6.1.jar,/usr/local/kafka_2.10-
0.8.2.1/libs/kafka-clients-0.8.2.1.jar,/usr/local/kafka_2.10-0.8.2.1/libs/kafka_2.10-0.8.2.1.jar,/usr/local/spark-
1.6.1-bin-hadoop2.6/lib/spark-streaming_2.10-1.6.1.jar,/usr/local/kafka_2.10-0.8.2.1/libs/metrics-core-
2.2.0.jar,/usr/local/kafka_2.10-0.8.2.1/libs/zkclient-0.3.jar,/usr/local/spark-1.6.1-bin-hadoop2.6/lib/spark-
assembly-1.6.1-hadoop2.6.0.jar /usr/local/IMF_testdata/SparkStreamingOnKafkaDirected161.jar
root@master:/usr/local/setup_scripts#
root@master:/usr/local/setup_scripts# IMFSparkStreamingOnKafkaDirectedSubmit161.sh
源代码:
JavaStreamingContext jsc=new JavaStreamingContext(conf, Durations.seconds(15));
Map
kafaParameters.put("metadata.broker.list",
"master:9092,worker1:9092,worker2:9092");
Set
topics.add("SparkStreamingDirected161");
JavaPairInputDStream
String.class,String.class,
StringDecoder.class, StringDecoder.class,
kafaParameters,
topics);
JavaDStream
public Iterable
return Arrays.asList(tuple._2.split(" "));
}
});
JavaPairDStream
@Override
public Tuple2
return new Tuple2
}
});
JavaPairDStream
@Override
public Integer call(Integer i1, Integer i2) {
return i1 + i2;
}
});
wordcount.print();
// wordcount.foreachRDD(foreachFunc);
jsc.start();
jsc.awaitTermination();
jsc.close();
终结者:
将 spark 1.6.0 升级为spark 1.6.1
kafka 从 kafka_2.10-0.9.0.1 调整为 kafka_2.10-0.8.2.1
kafka_2.10-0.8.2.1 + spark-1.6.1 彻底搞定了!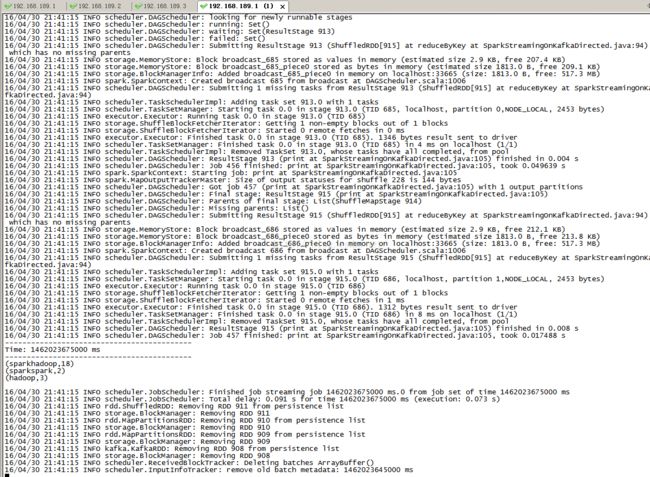

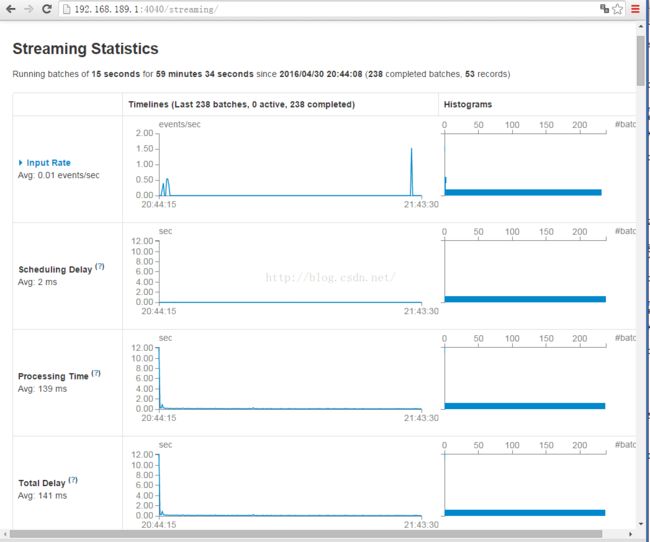
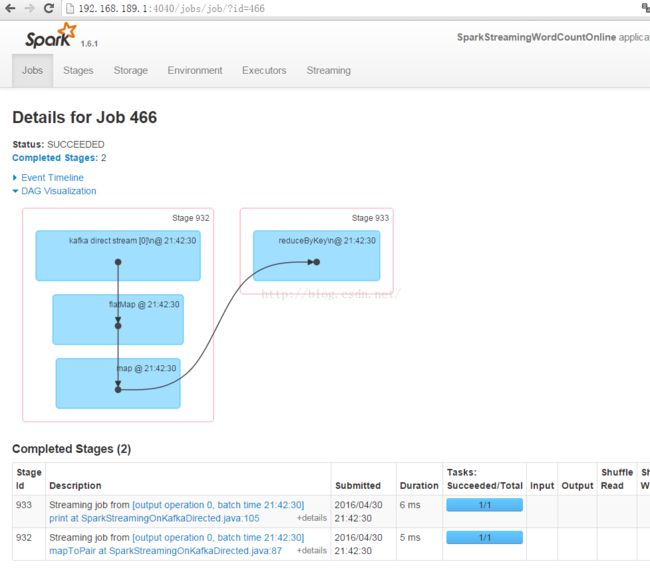
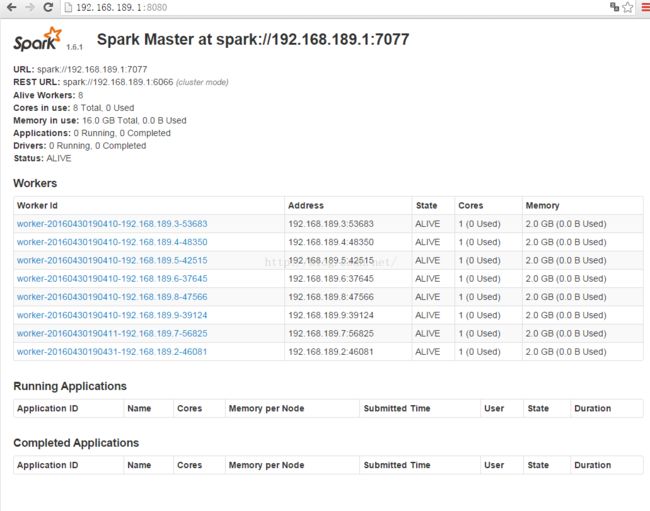
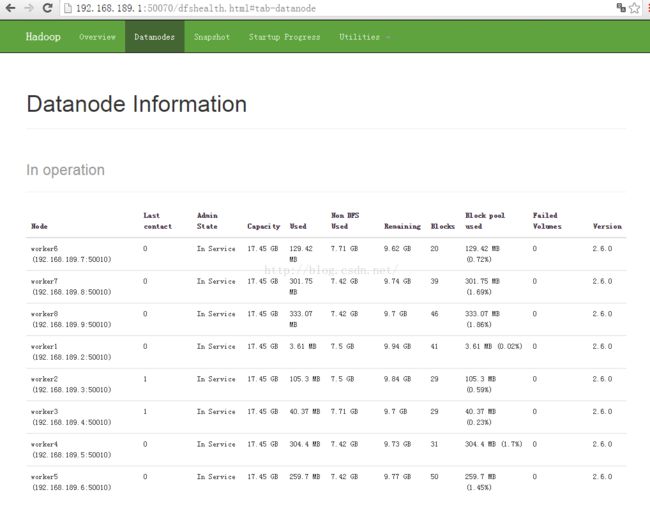
王家林老师 :DT大数据梦工厂创始人和首席专家。
联系邮箱:[email protected] 电话:18610086859 QQ:1740415547
微信号:18610086859 微博:http://weibo.com/ilovepains/
每天晚上20:00YY频道现场授课频道68917580
IMF Spark源代码版本定制班学员 :
上海-段智华 QQ:1036179833 mail:[email protected] 微信 18918561505