最先进模型指南:NLP中的Transformers如何运作?
全文共5257字,预计学习时长11分钟或更长
通过阅读本篇文章,你将理解:
· NLP中的Transformer模型真正改变了处理文本数据的方式。
· Transformer支持NLP的最新变化,包括谷歌的BERT。
· 了解Transformer的运作规律,如何进行语言建模、序列到序列建模以及如何构建Google的BERT模型。
下面,我们开始学习吧!

图片来源:pexels/Dominika Roseclay
当前,自然语言处理(NLP)的技术正以前所未有的速度发展。从超高效的ULMFiT框架到谷歌的BERT,NLP的确处于发展的黄金时代。
这场革命的核心就是Transformer概念,它改变了数据科学家使用文本数据的方式,下文将做具体介绍。
要举个例子证明Transformer的实用吗?请看下一段:

突出显示的词语指的是同一个人——Grieamann,一名受欢迎的足球运动员。对人类而言,弄清楚文本中这些词之间的关系并不困难。然而,对于一台机器来说,这是一项艰巨的任务。
机器要想理解自然语言,明确句子中的此类关系和词语序列至关重要。而Transformer 概念会在其中发挥重要作用。

目录
1. 序列到序列模型——背景
· 基于序列到序列模型的循环神经网络
· 挑战
2. NLP中的Transformer简介
· 理解模型框架
· 获得自注意力
· 计算自注意力
· Transformer的局限
3. 了解Transformer-XL
· 使用Transformer进行语言建模
· 使用Transformer-XL进行语言建模
4. NLP中的新尝试:Google的BERT
· 模型框架
· BERT训练前的任务
序列到序列模型——背景
NLP中的序列到序列(seq2seq)模型用于将A类型的序列转换为B类型的序列。例如,把英语句子翻译成德语句子就是序列到序列的任务。
自2014年引进以来,基于seq2seq模型的循环神经网络(RNN)已经获得了很多关注。当前世界的大多数数据都是序列形式,包括数字序列、文本序列、视频帧序列和音频序列。
2015年,seq2seq模型增加了注意力机制,使性能得到进一步提升。过去5年来NLP发展速度之快,简直令人难以置信!
这些序列到序列模型用途非常广泛,适用于各种NLP任务,例如:
· 机器翻译
· 文本摘要
· 语音识别
· 问答系统等
基于seq2seq模型的循环神经网络
举一个关于seq2seq模型的简单例子。请看下图:

上方的seq2seq模型正将德语短语转换为英语短语。下面进行分解:
· 编码器和解码器都是循环神经网络。
· 在编码器中的每一步,循环神经网络会从输入序列中获取一个字向量(xi),并从上一个时间步骤中获取一隐藏状态(Hi)。
· 隐藏状态会在每个时间步骤更新。
· 最后一个单元的隐藏状态称为上下文向量,包含有关输入序列的信息。
· 将上下文向量传给解码器,生成目标序列(英语短语)。
· 如果使用注意力机制,则隐藏状态的加权之和将作为上下文向量传给解码器。
挑战
尽管seq-2-seq模型表现良好,但仍存在一定的局限性:
· 处理长时依赖仍颇具挑战性。
· 模型框架的顺序阻止了并行化。而Google Brain的Transformer概念解决了这一挑战。
NLP中的Transformer简介
NLP中的Transformer是全新的框架,旨在解决序列到序列的任务,同时轻松处理长时依赖。Transformer是由Attention Is All You Need这篇论文提出的。建议对NLP感兴趣的人阅读该论文。
论文传送门:https://arxiv.org/abs/1706.03762
引自该论文:
Transformer是首个完全依靠自注意力来计算其输入和输出表示,而不使用序列对齐的循环神经网络或卷积的转换模型。
此处,“转换”是指将输入序列转换成输出序列。Transformer的创建理念是通过注意和重复,彻底处理输入和输出之间的依赖关系。
下面请看Transformer的框架。它可能看起来令人生畏,但不要担心,下面将进行分解,以便逐块理解。
理解Transformer的模型框架

图片来源: https://arxiv.org/abs/1706.03762
上图是Transformer框架的精彩插图。首先只需关注编码器和解码器的部分。
现在看看下图。编码器块具有一多头注意力层,然后另一层是前馈神经网络。而解码器具有额外的遮挡式多头注意力层。
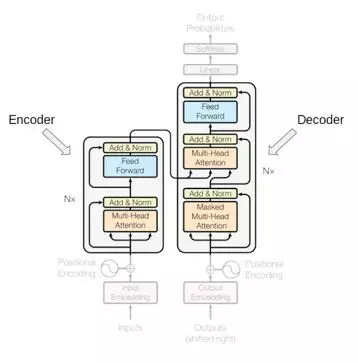
编码器和解码器块实际上是由多个相同的编码器和解码器彼此堆叠而成的。编码器堆栈和解码器堆栈具有相同数量的单元。
编码器和解码器单元的数量是超参数的。在本文中,使用了6个编码器和解码器。
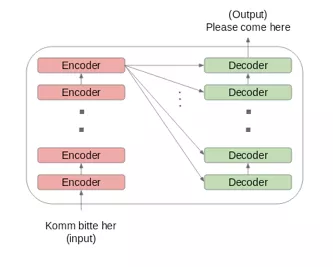
如何设置编码器和解码器堆栈:
· 将输入序列的嵌入词传给第一个编码器。
· 然后进行转换并传给下一个编码器。
· 将编码器堆栈中最后一个编码器的输出传给解码器堆栈中的所有解码器,如下图所示:
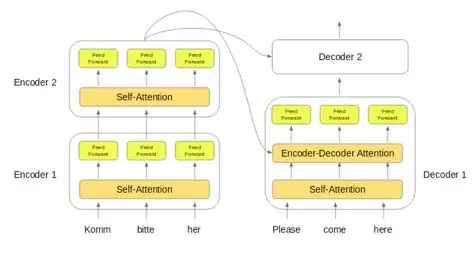
此处需要注意的重要事项——除了自注意力和前馈层外,解码器还有一层编码器——解码器注意层。这有助于解码器聚焦于输入序列的适当部分。
你可能会想这个“自注意力”层究竟在Transformer中做了什么?好问题!这可以说是整个设置中最重要的组成部分,所以首先要理解这个概念。
获得自注意力
根据该论文:
自注意力,有时称为内部注意力,是注意力机制,其关联单个序列的不同位置以计算序列的表示。

请看上方图片,你能弄清楚这句话中的“it”这个词的意思吗?
“it”指的是街道还是动物?对人们来说,这是个简单的问题。但对于算法而言,并非如此。模型处理“它”一词时,自注意力试图将“它”与同一句子中的“animal”联系起来。
自注意力允许模型查看输入序列中的其他词语,以更好地理解序列中的某个词语。现在,请看如何计算自注意力。
计算自注意力
为便于理解,笔者将此节分为以下步骤。
1. 首先,需要从编码器的每个输入向量中创建三个向量:
· 查询矢量
· 关键矢量
· 价值矢量
训练过程中会训练和更新这些向量。看完本节后,将更加了解其作用。
2. 接下来,将计算输入序列中每个词语的自注意力。
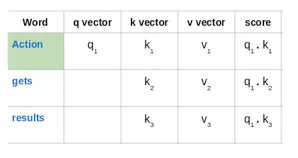
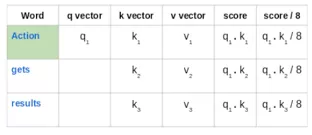
3. 以“Action gets results”这一短语为例。为计算第一个单词“Action”的自注意力,将计算短语中与“Action”相关的所有单词的分数。当对输入序列中某个单词编码时,该分数将确定其他单词的重要性。
第一个单词的得分是通过将查询向量(q1)的点积与所有单词的关键矢量(k1,k2,k3)进行计算得出的:
然后,将这些得分除以8,即关键矢量维数的平方根:
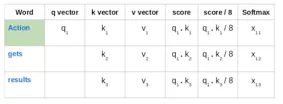
接下来,使用softmax激活函数使这些分数标准化:
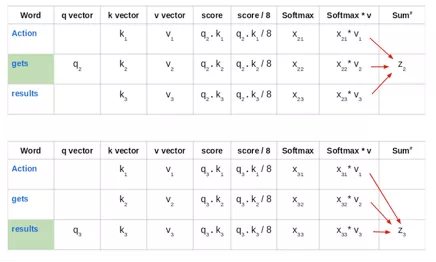
然后将这些标准化后的分数乘以价值向量(v1,v2,v3),并将其相加,得到最终向量(z1)。这是自注意力层的输出。然后将其作为输入传给前馈网络:

因此,z1是输入序列“Action gets results”的首个单词的自注意力向量。以相同的方式获取输入序列中其余单词的向量:
在Transformer的框架中,多次而非一次并行或独立地计算自注意力。因此,自注意力被称为多头注意力。输出的连接与线性转换如下图所示:
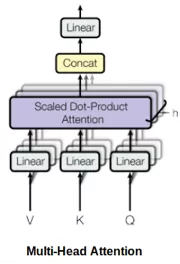
根据论文:
多头注意力允许模型共同关注来自不同位置的、不同子空间表示的信息。
Transformer的局限
Transformer无疑是对基于循环神经网络的seq2seq模型的巨大改进。但其本身有一些局限:
· 注意力只能处理固定长度的文本字符串。在作为输入进入馈入系统前,必须将文本分成一定数量的段或块。
· 这种文本分块会导致上下文碎片化。例如,如果句子从中间分割,则会丢失大量上下文。换句话说,文本分块时,未考虑句子或其他语义边界。
那么如何处理这些非常重要的问题呢?这是与Transformer合作的人们提出的问题,在此基础上产生了Transformer-XL。
了解Transformer-XL
Transformer 框架可习得长时依赖性。但由于使用了固定长度的上下文(输入文本段),框架无法超出一定的水平。为克服这一缺点,提出了一种新的框架——Transformer-XL:超出固定长度上下文的注意语言模型。
在该框架中,前段中获得的隐藏状态被再次用作当前段的信息源。它可以建模长时依赖性,因为信息可从一段流向下一段。
使用Transformer进行语言建模
将语言建模视为在给定前一单词后,估计下一单词概率的过程。
Al-Rfou等人 (2018)提出了将Transformer模型应用于语言建模的想法。根据该论文,整个语料库应依照可管理能力,划分固定长度段。然后,在段上单独训练Transformer模型,忽略所有来自前段的上下文信息:

图片来源:https://arxiv.org/abs/1901.02860
这种框架不会出现消失梯度的问题。但语境碎片限制了其习得长期依赖性。在评估阶段,该段仅会向右移动一个位置。新段必须完全从头开始处理。遗憾的是,这种评估方法计算量非常大。
使用Transformer-XL进行语言建模
在Transformer-XL的训练阶段,之前状态计算的隐藏状态被用作当前段的附加上下文。Transformer-XL的这种重复机制解决了使用固定长度上下文的限制。
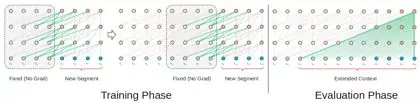
在评估阶段,可重复使用前段的表示,而非从头开始计算(如Transformer模型)。当然,这会提高计算速度。
NLP中的新尝试:Google的BERT(来自Transformers双向编码器的表示)
众所周知迁移学习在计算机视觉领域的重要性。例如,可针对ImageNet数据集上的新任务微调预训练的深度学习模型,并仍然可在相对较小的标记数据集上得到适当的结果。
同样,语言模型预训练可有效改进许多自然语言处理任务。
传送门:https://paperswithcode.com/paper/transformer-xl-attentive-language-models
BERT框架是Google AI新的语言表示模型,可进行预训练和微调,为各种任务创建最先进的模型。这些任务包括问答系统、情感分析和语言推理。
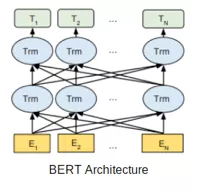
BERT的模型框架
BERT使用多层双向Transformer编码器。其自注意力层在两个方向上都有自注意力。谷歌发布了该模型的两个变体:
1BERT Base:Transformers 层数 = 12, 总参数 = 110M
2BERT Large:Transformers 层数 = 24, 总参数 = 340M
BERT通过双向性完成几项任务的预训练——遮挡式语言模型和下一句预测。下面将详细讨论这两项任务。
BERT训练前的任务
使用以下两个无人监督的预测任务对BERT进行预训练。
1. 遮挡式语言模型(MLM)
根据该论文:
遮挡式语言模型随机地从输入中遮挡了一些标记,目的是仅根据其上下文,预测被遮挡单词的原始词汇。与从左到右的语言模型预训练不同,MLM目标允许表示融合左右的上下文,这使我们可以对双向Transformer进行深度预训练。
Google AI研究人员随机遮挡每个序列中15%的单词。任务是什么呢?预测这些被遮挡的单词。需要注意——遮挡的单词并非总是带有遮挡的标记[MASK],因为在微调期间不会出现[MASK]标记。
因此,研究人员使用以下方法:
· 80%的单词带有被遮挡的标记[MASK]
· 10%的单词被随机单词替换
· 10%的单词保持不变
2. 下一句话预测
通常,语言模型不会理解连续句子间的关系。BERT也接受过这项任务的预训练。
对于语言模型预训练,BERT使用成对的句子作为其训练数据。每对句子的选择非常有趣。举个例子,以便更好地理解。
假设一个文本数据集有100,000个句子,想要使用这个数据集对BERT语言模型进行预训练。因此,将有50,000个训练样例或50,000对句子作为训练数据。
· 50%的句对中,第二句实际上是第一句的下一句。
· 其余50%的句对,第二句是来自语料库的随机句子。
· 第一种情况的标签将成为第二种情况的'IsNext'和'NotNext'。
像BERT这样的框架表明,无人监督学习(预训练和微调)将成为许多语言理解系统的关键要素。低资源任务尤其可从这些深度双向框架中获得巨大收益。
下面是一些NLP任务的快照,BERT在其中扮演着重要角色:

图片来源:https://arxiv.org/abs/1810.04805
我们应该很庆幸,在自己身处的时代里,NLP发展如此迅速,Transformers和BERT这样的架构正在为未来几年更为先进的突破铺平道路。
更多课程传送门:https://courses.analyticsvidhya.com/courses/natural-language-processing-nlp??utm_source=blog&utm_medium=understanding-transformers-nlp-state-of-the-art-models

留言 点赞 关注
我们一起分享AI学习与发展的干货
欢迎关注全平台AI垂类自媒体 “读芯术”
(添加小编微信:dxsxbb,加入读者圈,一起讨论最新鲜的人工智能科技哦~)