YOLOv2简述
前些日子看了看YOLOv2算法,算是引领了本人在分类检测算法中的入门吧,综合了一下自己看论文和博客的收获,根据自己的理解简单说一下YOLOv2是怎么回事儿。
如果哪里表述有不妥当或者理解偏差欢迎各位大神批评指正。
好了那我们进入正题。
YOLOv2在原版本的基础上进行改进,在精度上有所提升。
为了精度的提升,YOLOv2使用了一些方法和技巧
图片中展示了各方法对模型性能的提高:

本文主要针对其中几项技术进行分析:
High Resolution Classifier
Convolutional With Anchor Boxes
Dimension Clusters
Direct Location Prediction
Fine-Grained Features
Multi-Scale Training
训练过程中,每层卷积神经网络的输入分布会向两极偏移,而Batch Normalization会调整输入分布,从而使得每层输入保持相同分布,减小训练难度,提高mAP。
(官方论文中的提升为2%)
对Batch Normalization这项技术不了解的朋友们可以参看本人的另外一篇博客:
机器学习中的一些基本概念(未完待续)
【High Resolution Classifier】
对于这项技术,本人的理解是:分辨率越高,单位面积内的像素越多,保留原图片的信息越完整,目标检测越容易也越准确。YOLOv2首先对分类网络(darknet)进行fine tune,进行预训练,使训练后的网络适应高分辨率输入。然后,对检测网络也进行fine tune。
通过提升分辨率,提升了mAP。
(官方论文中的提升为4%)
【Convolutional With Anchor Boxes】
这项技术主要是在卷积过程中的feature map中使用anchor boxes,像这样:

(图片来自:YOLOv2论文笔记)
论文通过缩减网络,让图片分辨率为416*416,这是为了让后面产生的卷积feature map宽高都为奇数,以产生一个center box,位于图像中间。
以factor = 32进行降采样,得到13*13的的卷积特征图(上文中提到的宽高均为奇数的feature map)。(注:降采样即为池化)
feature map中的每个cell预测一定数量的anchor boxes(官方论文中为9),加了anchor boxes之后,recall上升,precision下降。
为什么recall会上升,precision会下降呢?
由于对每个cell均进行anchor boxes生成,集合更多,选到该类物体的概率更大,故recall更大;
但可能对非该类的(类似)物体也生成anchor box并将其分类为该类,故precision下降。
对recall、precision不了解的朋友们同样可以参看本人的另外一篇博客:
机器学习中的一些基本概念(未完待续)
【Dimension Clusters】
在以往的算法中(例如SSD),anchor boxes的宽高比往往是提前确定的。如果事先确定的宽高维度不具有代表性,那么在训练中,网络将对其进行调整,最终得到准确的bounding boxes。这也就意味着,更好的先验boxes维度将使得网络预测的位置更加准确,学习速度也会更快。所以,论文中使用了利用IoU(交并比)的K-means聚类方法训练bounding boxes,自动找到更具有代表性的宽高维度。
论文通过改进后的K-means方法(原来K-means方法利用欧式距离计算距离,而论文中利用IoU计算距离)对boxes进行聚类,最终认为k = 5时算法复杂度和IoU之间有较好的balance,选择5种不同大小的boxes维度进行预测。
有趣的是,进行聚类实验过后,boxes中瘦高的框较多,矮胖的框较少。
改进后的聚类函数:
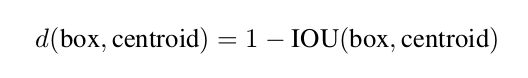
聚类结果图:

这种聚类方法有效地提高了recall,如下图所示:
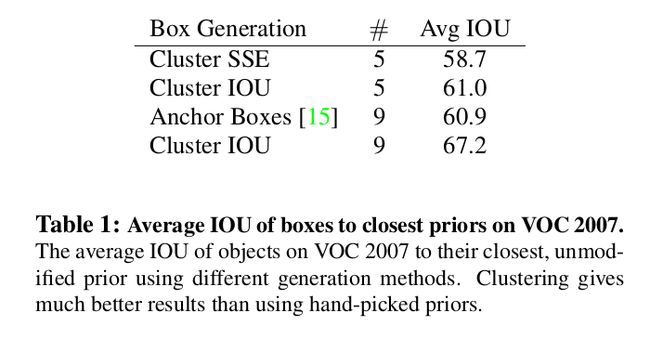
利用Cluster IoU生成9个anchor boxes的平均IoU(67.2)要明显高于先验anchor boxes的效果(60.9)。
【Direct Location Prediction】
直接使用anchor box导致模型不稳定(原公式不对横纵坐标进行约束,所以anchor可能会检测很远的目标box,效率很低)。所以,使用预测相对于grid cell(grid cell就是feature map中的cell)坐标位置的方法:
相应cell距离整张图(feature map)的左上角边距为c(x),c(y),利用sigmoid函数将函数值约束到[0,1],预测相对于该cell中心的偏移。
该方法主要解决的问题是:使得anchor box只对相应cell内的目标进行检测,以解决模型不稳定的问题。
具体的公式在该博客中有详细给出说明和解释:
YOLOv2论文笔记
【Fine-Grained Features】
利用转移层(passthrough layer)把26*26*512的特征图连接到了13*13*2048的特征图(前者进行细粒度检测,后者进行粗粒度检测),有利于检测小目标。这样,就提高了物体检测的包容度,进而提升了模型的性能。
(官方论文中获得了1%的性能提升)
【Multi-Scale Training】
网络输入的图片为416*416,而论文作者需要YOLOv2对不同尺寸的图片具有鲁棒性,因此进行Multi-Scale Training(多尺度训练)。
在之前的介绍中有提到,YOLO网络使用的降采样 factor = 32。
所以利用32的倍数进行池化(官方论文中利用320,352,……,608进行池化)。处理过后,最小的尺寸为320*320,最大的尺寸为608*608。
在10个epoch过后,对网络进行fine tune,随机选择新的图片尺寸,然后按照输入尺寸进行训练。实验表明,Multi-Scale Training使得同一个网络对不同分辨率的图片都可以进行检测,提高了网络性能。
下为YOLOv2与其他网络在某数据集上进行的对比表、图:


除精度外,YOLOv2在分类种类上也有了一个飞跃:
【交叉数据集训练】
利用ImageNet训练分类,COCO和VOC数据集训练检测。但问题在于:ImageNet对应分类有9000种,COCO只提供80种目标检测,这该怎么办?
论文中提出了一种新方法:利用multi-label模型,假定一张图片可以有多个label,且不要求label间独立(即,不要求mutual exclusion——相互排斥)。
交叉数据集训练图(很震撼):

分级分类
ImageNet的label提取自WordNet,WordNet是一个表明语言(我的理解是单词)结构概念和其间关系的数据库。
用一段论文中的原文可能会加强对语言关系的理解:
In WordNet, “Norfolk terrier” and “Yorkshire terrier” are both hyponyms of “terrier” which is a type of “hunting dog”, which is a type of “dog”, which is a “canine”, etc.
WordNet结构是一个有向图,根据该有向图构造分级树WordTree。
先将所有到WordNet的原点(称为physical object)只有单路径的词语的该路径加入分级树,再将剩余其他词汇相对原点的最短路径加入分级树,得到WordTree。
下图表述了WordTree和ImageNet在预测上的区别:
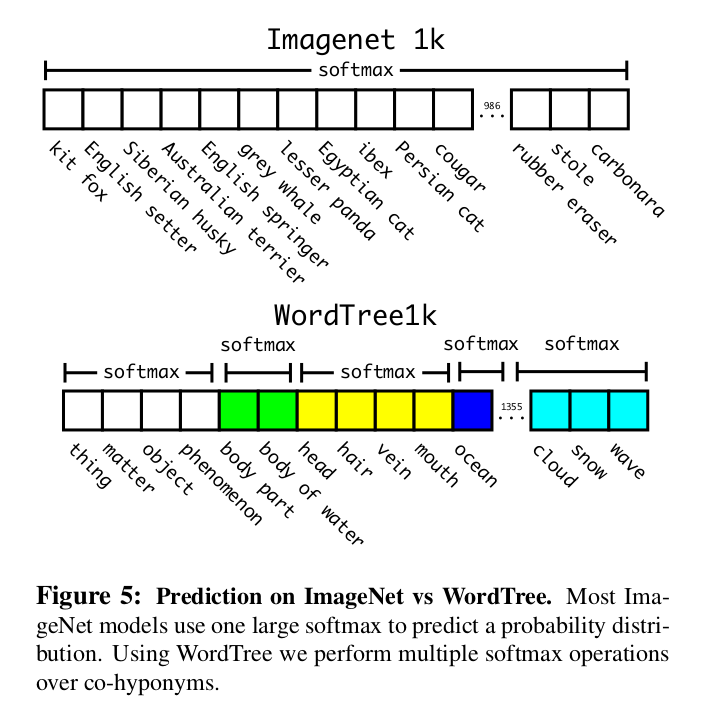
分类:
ground truth label沿着树向根节点传播,所以,如果image被label成 'norfolk terrier',那么它也会获取到 'dog' 和 'mammal' 标签。
检测:
预测bounding box和概率树,将树由上向下遍历,在每个分支找到最高的confidence直到它小于事先设定的某阈值。
通过交叉数据集训练以及WordTree,可以得到9000+种分类。
参考博客:
YOLOv2论文笔记
官方论文下载地址:
YOLO9000: Better, Faster, Stronger