PRML阅读笔记(三)
CH3 Linear models for regression回归的线性模型
3.1线性基函数模型
-
回归的最简单模型
y ( x , w ) = w 0 + w 1 x 1 + … + w D x D y(\boldsymbol x,\boldsymbol w)=w_0+w_1x_1+\ldots+w_Dx_D y(x,w)=w0+w1x1+…+wDxD
其中 x = ( x 1 , … , x D ) T \boldsymbol x=(x_1,\ldots,x_D)^T x=(x1,…,xD)T. -
扩展模型
将输入变量的固定的非线性函数进行线性组合
形式为
y ( x , w ) = w 0 + ∑ j = 1 M − 1 w j ϕ j ( x ) y(\boldsymbol x,\boldsymbol w)=w_0+\sum_{j=1}^{M-1}w_j\phi_j(\boldsymbol x) y(x,w)=w0+j=1∑M−1wjϕj(x)
其中 ϕ j ( x ) \phi_j(\boldsymbol x) ϕj(x)称为基函数(basis function)。此模型中的参数总数为 M M M。参数 w 0 w_0 w0称为偏置参数(bias parameter)定义 ϕ 0 ( x ) = 1 \phi_0(\boldsymbol x)=1 ϕ0(x)=1,此时
y ( x , w ) = ∑ j = 0 M − 1 w j ϕ j ( x ) = w T ϕ ( x ) y(\boldsymbol x,\boldsymbol w)=\sum_{j=0}^{M-1}w_j\phi_j(\boldsymbol x)=\boldsymbol w^T\phi(\boldsymbol x) y(x,w)=j=0∑M−1wjϕj(x)=wTϕ(x)
其中 w = ( w 0 , … , w M − 1 ) T \boldsymbol w=(w_0,\ldots,w_M-1)^T w=(w0,…,wM−1)T且 ϕ = ( ϕ 0 , … , ϕ M − 1 ) T \phi=(\phi_0,\ldots,\phi_{M-1})^T ϕ=(ϕ0,…,ϕM−1)T。基函数{ ϕ j ( x ) \phi_j(\boldsymbol x) ϕj(x)}可以表示原始变量 x \boldsymbol x x的特征(预处理或特征抽取后的) -
基函数选择
多项式拟合,基函数: ϕ j ( x ) = x j \phi_j(x)=x^j ϕj(x)=xj。局限性:是输入变量的全局函数,因此对于输入空间一个区域的改变将会影响所有其他的区域。解决:把输入空间切分成若干个区域,对每个区域用不同的多项式函数拟合。----样条函数(spline function)???
高斯基函数, ϕ j ( x ) = exp { − ( x − μ j ) 2 2 s 2 } \phi_j(x)=\exp\left\{-\frac{(x-\mu_j)^2}{2s^2}\right\} ϕj(x)=exp{−2s2(x−μj)2},其中 μ j \mu_j μj控制了基函数在输入空间中的位置,参数 s s s控制了基函数的空间大小。未必是一个概率表达式。归一化系数不重要,因为有调节参数 w j w_j wj
sigmoid基函数, ϕ j ( x ) = σ ( x − μ j s ) \phi_j(x)=\sigma(\frac{x-\mu_j}{s}) ϕj(x)=σ(sx−μj),其中 σ ( a ) = 1 1 + exp ( − a ) \sigma(a)=\frac{1}{1+\exp(-a)} σ(a)=1+exp(−a)1是logistic sigmoid函数。等价地可以使用tanh函数,和logistic sigmoid函数的关系为tanh( a a a)= 2 σ ( 2 a ) − 1 2\sigma(2a)-1 2σ(2a)−1
傅里叶基函数,用正弦函数展开。

3.1.1最大似然与最小平方
假设目标变量 t t t由确定的函数 y ( x , w ) y(\boldsymbol x,\boldsymbol w) y(x,w)给出,附加高斯噪声,即
t = y ( x , w ) + ϵ t=y(\boldsymbol x,\boldsymbol w)+\epsilon t=y(x,w)+ϵ
其中 ϵ \epsilon ϵ是一个零均值的高斯随机变量,精度为 β \beta β,有
p ( t ∣ x , w , β ) = N ( t ∣ y ( x , w ) , β − 1 ) p(t|\boldsymbol x,\boldsymbol w,\beta)=\mathcal N(t|y(\boldsymbol x,\boldsymbol w),\beta^{-1}) p(t∣x,w,β)=N(t∣y(x,w),β−1)
ch1中,假设一个平方损失函数,对于 x \boldsymbol x x的一个新值,最优预测由目标变量的条件均值给出,在高斯条件分布的情况下,条件均值可写成
E [ t ∣ x ] = ∫ t p ( t ∣ x ) d t = y ( x , w ) \mathbb E[t|\boldsymbol x]=\int tp(t|\boldsymbol x)dt=y(\boldsymbol x,\boldsymbol w) E[t∣x]=∫tp(t∣x)dt=y(x,w)
高斯噪声的假设表明,给定 x \boldsymbol x x的条件下, t t t的条件分布是单峰的,可以扩展到条件高斯分布的混合,描述多峰的条件分布
考虑一个输入数据集 X = { x 1 , … , x N } \boldsymbol X=\left\{\boldsymbol x_1,\ldots,\boldsymbol x_N\right\} X={x1,…,xN},对应的的目标值为 t 1 , … , t N t_1,\ldots,t_N t1,…,tN,将目标向量{ t n t_n tn}组成一个列向量,记作 t \boldsymbol t t。假设数据点独立,得到似然函数为
p ( t ∣ X , w , β ) = ∏ n = 1 N N ( t n ∣ w T ϕ ( x n ) , β − 1 ) p(\boldsymbol t|\boldsymbol X,\boldsymbol w,\beta)=\prod_{n=1}^N\mathcal N(t_n|\boldsymbol w^T\phi(\boldsymbol x_n),\beta^{-1}) p(t∣X,w,β)=n=1∏NN(tn∣wTϕ(xn),β−1)
取对数似然函数,有(不显式地写出 x \boldsymbol x x)
ln p ( t ∣ w , β ) = ∑ n = 1 N ln N ( t n ∣ w T ϕ ( x n ) , β − 1 ) = N 2 ln β − N 2 ln ( 2 π ) − β E D ( w ) \ln p(\boldsymbol t|\boldsymbol w,\beta)=\sum_{n=1}^N\ln \mathcal N(t_n|\boldsymbol w^T\phi(\boldsymbol x_n),\beta^{-1})=\frac{N}{2}\ln\beta-\frac{N}{2}\ln(2\pi)-\beta E_D(\boldsymbol w) lnp(t∣w,β)=n=1∑NlnN(tn∣wTϕ(xn),β−1)=2Nlnβ−2Nln(2π)−βED(w)
其中平方和误差函数为
E D ( w ) = 1 2 ∑ n = 1 N { t n − w T ϕ ( x n ) } 2 E_D(\boldsymbol w)=\frac{1}{2}\sum_{n=1}^N\left\{t_n-\boldsymbol w^T\phi(\boldsymbol x_n)\right\}^2 ED(w)=21n=1∑N{tn−wTϕ(xn)}2
对数似然函数的梯度为
∇ ln p ( t ∣ w , β ) = β ∑ n = 1 N { t n − w T ϕ ( x n ) } ϕ ( x n ) T \nabla \ln p(\boldsymbol t|\boldsymbol w,\beta)=\beta\sum_{n=1}^N\left\{t_n-\boldsymbol w^T\phi(\boldsymbol x_n)\right\}\phi(\boldsymbol x_n)^T ∇lnp(t∣w,β)=βn=1∑N{tn−wTϕ(xn)}ϕ(xn)T
令梯度为0,得
0 = ∑ n = 1 N t n ϕ ( x n ) T − w T ( ∑ n = 1 N ϕ ( x n ) ϕ ( x n ) T ) 0=\sum_{n=1}^Nt_n\phi(\boldsymbol x_n)^T-\boldsymbol w^T(\sum_{n=1}^N\phi(\boldsymbol x_n)\phi(\boldsymbol x_n)^T) 0=n=1∑Ntnϕ(xn)T−wT(n=1∑Nϕ(xn)ϕ(xn)T)
求解 w \boldsymbol w w,有
w M L = ( Φ T Φ ) − 1 Φ T t \boldsymbol w_{ML}=(\boldsymbol \Phi^T\boldsymbol \Phi)^{-1}\boldsymbol \Phi^T\boldsymbol t wML=(ΦTΦ)−1ΦTt
称为最小平方问题的规范方程(normal equation), Φ \boldsymbol \Phi Φ是 N × M N\times M N×M的矩阵,称为设计矩阵(design matrix),元素为 Φ n j = ϕ j ( x n ) \Phi_{nj}=\phi_j(\boldsymbol x_n) Φnj=ϕj(xn),即
Φ = ( ϕ 0 ( x 1 ) ϕ 1 ( x 1 ) ⋯ ϕ M − 1 ( x 1 ) ϕ 0 ( x 2 ) ϕ 1 ( x 2 ) ⋯ ϕ M − 1 ( x 2 ) ⋮ ⋮ ⋱ ⋮ ϕ 0 ( x N ) ϕ 1 ( x N ) ⋯ ϕ M − 1 ( x N ) ) \boldsymbol \Phi=\begin{pmatrix}\phi_0(\boldsymbol x_1) &\phi_1(\boldsymbol x_1) & \cdots & \phi_{M-1}(\boldsymbol x_1) \\ \phi_0(\boldsymbol x_2) & \phi_1(\boldsymbol x_2) &\cdots & \phi_{M-1}(\boldsymbol x_2) \\ \vdots &\vdots&\ddots&\vdots \\\phi_0(\boldsymbol x_N)&\phi_1(\boldsymbol x_N)&\cdots&\phi_{M-1}(\boldsymbol x_N)\end{pmatrix} Φ=⎝⎜⎜⎜⎛ϕ0(x1)ϕ0(x2)⋮ϕ0(xN)ϕ1(x1)ϕ1(x2)⋮ϕ1(xN)⋯⋯⋱⋯ϕM−1(x1)ϕM−1(x2)⋮ϕM−1(xN)⎠⎟⎟⎟⎞
量
Φ † ≡ ( Φ T Φ ) − 1 Φ T \boldsymbol \Phi^\dagger\equiv (\boldsymbol \Phi^T\boldsymbol \Phi)^{-1}\boldsymbol \Phi^T Φ†≡(ΦTΦ)−1ΦT
成为矩阵的Moore-Penrose伪逆矩阵(pseudo-inverse matrix),可被看成逆矩阵的概念对于非方阵的矩阵的推广
显式地写出偏置参数,误差函数为
E D ( w ) = 1 2 ∑ n = 1 N { t n − w 0 − ∑ j = 1 M − 1 w j ϕ j ( x n ) } 2 E_D(\boldsymbol w)=\frac{1}{2}\sum_{n=1}^N\left\{t_n-w_0-\sum_{j=1}^{M-1}w_j\phi_j(x_n)\right\}^2 ED(w)=21n=1∑N{tn−w0−j=1∑M−1wjϕj(xn)}2
令关于 w o w_o wo的导数等于零,解出 w o w_o wo,得
w 0 = t ˉ − ∑ j = 1 M − 1 w j ϕ ˉ j w_0=\bar t-\sum_{j=1}^{M-1}w_j\bar \phi_j w0=tˉ−j=1∑M−1wjϕˉj
其中定义了
t ˉ = 1 N ∑ n = 1 N t n \bar t=\frac{1}{N}\sum_{n=1}^Nt_n tˉ=N1n=1∑Ntn
ϕ ˉ j = 1 N ∑ n = 1 N ϕ j ( x n ) \bar \phi_j=\frac{1}{N}\sum_{n=1}^N\phi_j(\boldsymbol x_n) ϕˉj=N1n=1∑Nϕj(xn)
因此偏置 w 0 w_0 w0补偿了目标值的平均值(在训练集上的)与基函数的值的平均值的加权求和之间的差。
关于噪声精度参数 β \beta β最大化似然函数
1 β M L = 1 N ∑ n = 1 N { t n − w M L T ϕ ( x n ) } 2 \frac{1}{\beta_{ML}}=\frac{1}{N}\sum_{n=1}^N\left\{t_n-w_{ML}^T\phi(x_n)\right\}^2 βML1=N1n=1∑N{tn−wMLTϕ(xn)}2
因此噪声精度的倒数由目标值在回归函数周围的残留方差给出
3.1.2最小平方的几何描述
考虑一个 N N N维空间,坐标轴由 t n t_n tn给出, t = ( t 1 , … , t N ) \boldsymbol t=(t_1,\ldots,t_N) t=(t1,…,tN)是空间中的一个向量 ,每个在 N N N个数据点处估计的基函数 ϕ j ( x n ) \phi_j(\boldsymbol x_n) ϕj(xn)可以表示为这个空间中的一个向量,记作 φ j \varphi_j φj,对应于 Φ \Phi Φ的第 i i i列
如果基函数的数量 M M M小于数据点的数量 N N N,那么 M M M个向量 φ j \varphi_j φj将会张成一个 M M M维的子空间 S S S。
定义 y \boldsymbol y y是一个 N N N维向量,第 n n n个元素为 y ( x n , w ) y(\boldsymbol x_n,\boldsymbol w) y(xn,w),由于 y \boldsymbol y y是向量 φ j \varphi_j φj的任意线性组合,因此可以位于 M M M维子空间的任何位置
平方和误差函数等于 y \boldsymbol y y和 t \boldsymbol t t之间的平方欧式距离(相差一个因子 1 2 \frac{1}{2} 21)
因此, w \boldsymbol w w的最小平方解对应于子空间 S S S上的正交投影

3.1.3顺序学习
随机梯度下降(stochastic gradient descent):
如果误差函数由数据点的和组成 E = ∑ n E n E=\sum_nE_n E=∑nEn,那么在观测到模式 n n n之后,使用下式更新参数向量 w \boldsymbol w w
w ( τ + 1 ) = w ( τ ) − η ∇ E n \boldsymbol w^{(\tau+1)}=\boldsymbol w^{(\tau)}-\eta\nabla E_n w(τ+1)=w(τ)−η∇En
其中 τ \tau τ表示迭代次数, η \eta η是学习率参数。 w \boldsymbol w w被初始化为某个起始向量 w ( 0 ) \boldsymbol w^{(0)} w(0)
对于平方和误差函数的情形,有
w ( τ + 1 ) = w ( τ ) + η ( t n − w ( τ ) T ϕ n ) ϕ n \boldsymbol w^{(\tau+1)}=\boldsymbol w^{(\tau)}+\eta(t_n-\boldsymbol w^{(\tau)T}\phi_n)\phi_n w(τ+1)=w(τ)+η(tn−w(τ)Tϕn)ϕn
其中 ϕ n = ϕ ( x n ) \phi_n=\phi(\boldsymbol x_n) ϕn=ϕ(xn),称为最小均方(least-mean-squares)或LMS算法, η \eta η的值需要选择以确保算法收敛
3.1.4正则化最小平方
需要最小化的总的误差函数为
E D ( w ) + λ E W ( w ) E_D(\boldsymbol w)+\lambda E_W(\boldsymbol w) ED(w)+λEW(w)
正则化项的一个最简单的形式为权向量的各个元素的平方和
E W ( w ) = 1 2 w T w 2 E_W(\boldsymbol w)=\frac{1}{2}\boldsymbol w^T\boldsymbol w^2 EW(w)=21wTw2
考虑平方和误差函数后的总误差函数为
1 2 ∑ n = 1 N { t n − w T ϕ ( x n ) } + λ 2 w T w \frac{1}{2}\sum_{n=1}^N\left\{t_n-\boldsymbol w^T\phi(\boldsymbol x_n)\right\}+\frac{\lambda}{2}\boldsymbol w^T\boldsymbol w 21n=1∑N{tn−wTϕ(xn)}+2λwTw
称为权值衰减(weight decay),在顺序学习算法中,倾向于让权值向0的方向衰减,除非有数据支持。优点是,误差函数是 w \boldsymbol w w的二次函数,精确的最小值有解析解。
w = ( λ I + Φ T Φ ) − 1 Φ T t \boldsymbol w=(\lambda I+\Phi^T\Phi)^{-1}\Phi^T\boldsymbol t w=(λI+ΦTΦ)−1ΦTt
用更加一般的正则化项,为
1 2 ∑ n = 1 N { t n − w T Φ ( x n ) } 2 + λ 2 ∑ j = 1 M ∣ w j ∣ q \frac{1}{2}\sum_{n=1}^N\left\{t_n-w^T\Phi(x_n)\right\}^2+\frac{\lambda}{2}\sum_{j=1}^M|w_j|^q 21n=1∑N{tn−wTΦ(xn)}2+2λj=1∑M∣wj∣q
其中 q = 2 q=2 q=2对应于二次正则化项
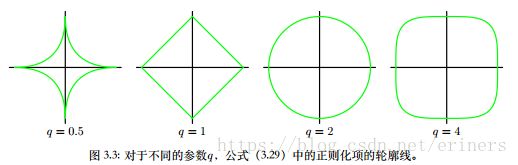
q = 1 q=1 q=1的情形称为套索(lasso)。性质为:如果 λ \lambda λ充分大,,那么某些系数 w j w_j wj会变为0,从而产生了一个稀疏模型(sparse),这个模型中对应的基函数不起作用。
最小化公式 w 0 = t ˉ − ∑ j = 1 M − 1 w j ϕ ˉ j w_0=\bar t-\sum_{j=1}^{M-1}w_j\bar \phi_j w0=tˉ−∑j=1M−1wjϕˉj等价于在满足下面限制的条件下最小化未正则化的平方和误差函数(???不懂)
∑ j = 1 M ∣ w j ∣ q ≤ η \sum_{j=1}^M|w_j|^q\leq \eta j=1∑M∣wj∣q≤η
参数 η \eta η要选择一个合适的值,这样这两种方法通过拉格朗日乘数法联系到一起。
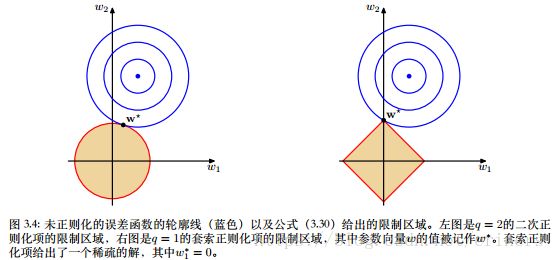
正则化方法通过限制模型的复杂度,使得复杂的模型能在有限大小的数据集上进行训练而不会产生严重的过拟合。这样就使确定最优的模型复杂度的问题从确定合适的基函数数量的问题转移到了确定正则化系数 λ \lambda λ的合适值的问题上
3.1.5多个输出
多个目标变量,记作目标向量 t \boldsymbol t t,
方法一:对于 t \boldsymbol t t的每个分量,引入一个不同的基函数集合,变成多个独立的回归问题
方法二:更常用。对目标向量的所有分量使用一组相同的基函数建模,即
y ( x , w ) = W T ϕ ( x ) \boldsymbol y(\boldsymbol x,\boldsymbol w)=\boldsymbol W^T\phi(\boldsymbol x) y(x,w)=WTϕ(x)
其中 y \boldsymbol y y是一个 K K K为列向量, W \boldsymbol W W是 M × K M\times K M×K的参数矩阵, ϕ ( x ) \phi(\boldsymbol x) ϕ(x)是 M M M列向量,每个元素为 ϕ j ( x ) \phi_j(\boldsymbol x) ϕj(x),且 ϕ 0 ( x ) = 1 \phi_0(\boldsymbol x)=1 ϕ0(x)=1
假设令目标向量的条件概率分布是一个各向同性的高斯分布,形式为
p ( t ∣ x , W , β ) = N ( t ∣ W T ϕ ( x ) , β − 1 I ) p(\boldsymbol t|\boldsymbol x,\boldsymbol W,\beta)=\mathcal N(\boldsymbol t|\boldsymbol W^T\phi(\boldsymbol x),\beta^{-1}I) p(t∣x,W,β)=N(t∣WTϕ(x),β−1I)
若有一组观测 t 1 , … , t N \boldsymbol t_1,\ldots,\boldsymbol t_N t1,…,tN,组合成一个 N × K N\times K N×K的矩阵 T T T,使得矩阵的第 n n n行为 t n T \boldsymbol t_n^T tnT.类似地,把输入向量 x 1 , … , x N \boldsymbol x_1,\ldots,\boldsymbol x_N x1,…,xN组合成矩阵 X \boldsymbol X X.此时对数似然函数为
ln p ( T ∣ X , W , β ) = ∑ n = 1 N ln N ( t n ∣ W T ϕ ( x n ) , β − 1 I ) \ln p(\boldsymbol T|\boldsymbol X,\boldsymbol W,\beta)=\sum_{n=1}^N\ln \mathcal N(t_n|\boldsymbol W^T\phi(\boldsymbol x_n),\beta^{-1}I) lnp(T∣X,W,β)=n=1∑NlnN(tn∣WTϕ(xn),β−1I)
= N K 2 ln ( β 2 π ) − β 2 π ∑ n = 1 N ∣ ∣ t n − W T ϕ ( x n ) ∣ ∣ 2 =\frac{NK}{2}\ln(\frac{\beta}{2\pi})-\frac{\beta}{2\pi}\sum_{n=1}^N||\boldsymbol t_n-\boldsymbol W^T\phi(\boldsymbol x_n)||^2 =2NKln(2πβ)−2πβn=1∑N∣∣tn−WTϕ(xn)∣∣2
关于 W \boldsymbol W W最大化函数,得
W M L = ( Φ T Φ ) − 1 Φ T T \boldsymbol W_{ML}=(\Phi^T\Phi)^{-1}\Phi^TT WML=(ΦTΦ)−1ΦTT
对每个目标变量 t k t_k tk考察这个结果,有
w k = ( Φ T Φ ) − 1 Φ T t k = Φ † t k \boldsymbol w_k=(\Phi^T\Phi)^{-1}\Phi^T\boldsymbol t_k=\Phi^{\dagger}\boldsymbol t_k wk=(ΦTΦ)−1ΦTtk=Φ†tk
其中 t k \boldsymbol t_k tk是一个 N N N维列向量,元素维 t n k t_{nk} tnk,因此不同目标向量得回归问题被分解开,只需要计算逆伪矩阵 Φ † \Phi^{\dagger} Φ†,此矩阵是被所有向量 w k \boldsymbol w_k wk所共享的
3.2偏置-方差分解
-
从频率学家的观点考虑模型的复杂度(bias-variance trade-off)
-
使用平方损失函数时最优的预测由条件期望给出,即
h ( x ) = E [ t ∣ x ] = ∫ t p ( t ∣ x ) d t h(\boldsymbol x)=\mathbb E[t|\boldsymbol x]=\int tp(t|\boldsymbol x)dt h(x)=E[t∣x]=∫tp(t∣x)dt
平方损失函数的期望为
E [ L ] = ∫ { y ( x ) − h ( x ) } 2 p ( x ) d x + ∫ ∫ { h ( x ) − t } 2 p ( x , t ) d x d t \mathbb E[L]=\int\left\{y(\boldsymbol x)-h(\boldsymbol x)\right\}^2p(\boldsymbol x)d\boldsymbol x+\int \int\left\{h(\boldsymbol x)-t\right\}^2p(\boldsymbol x,t)d\boldsymbol xdt E[L]=∫{y(x)−h(x)}2p(x)dx+∫∫{h(x)−t}2p(x,t)dxdt
第二项与 y ( x ) y(\boldsymbol x) y(x)无关,是由数据本身的噪声造成的,表示期望损失能够达到的最小值。第一项与 y ( x ) y(\boldsymbol x) y(x)的选择无关,找一个 y ( x ) y(\boldsymbol x) y(x)的解使得这一项最小。原则上数据无限多计算资源无限多能以任意的精度寻找回归函数 h ( x ) h(\boldsymbol x) h(x),给出 y ( x ) y(\boldsymbol x) y(x)的最优解。在实际应用中,数据集 D \mathcal D D只有有限的 N N N个数据点,不能精确地得到回归函数 h ( x ) h(\boldsymbol x) h(x)
-
如果使用由参数向量 w \boldsymbol w w控制的函数 y ( x , w ) y(\boldsymbol x,\boldsymbol w) y(x,w)对 h ( x ) h(\boldsymbol x) h(x)建模
假设有许多大小为 N N N的数据集 D \mathcal D D,学习得到预测函数 y ( x ; D ) y(\boldsymbol x;\mathcal D) y(x;D).不同的数据集给出不同的函数,给出不同的平方损失的值。特定的学习算法的表现就可以通过取各个数据集上的表现的平均值进行评估
考虑上式的第一项的被积函数,对于一个特定的数据集 D \mathcal D D,形式为
{ y ( x ; D ) − h ( x ) } 2 \left\{y(\boldsymbol x;\mathcal D)-h(\boldsymbol x)\right\}^2 {y(x;D)−h(x)}2
这个量与特定的数据集 D \mathcal D D相关,因此对所有的数据集取平均。在括号内做处理,有
{ y ( x ; D ) − E D [ y ( x ; D ) ] + E D [ y ( x ; D ) ] − h ( x ) } 2 \left\{y(\boldsymbol x;\mathcal D)-\mathbb E_{\mathcal D}[y(\boldsymbol x;\mathcal D)]+\mathbb E_{\mathcal D}[y(\boldsymbol x;\mathcal D)]-h(\boldsymbol x)\right\}^2 {y(x;D)−ED[y(x;D)]+ED[y(x;D)]−h(x)}2= { y ( x ; D ) − E D [ y ( x ; D ) ] } 2 + { E D [ y ( x ; D ) ] − h ( x ) } 2 =\left\{y(\boldsymbol x;\mathcal D)-\mathbb E_{\mathcal D}[y(\boldsymbol x;\mathcal D)]\right\}^2+\left\{E_{\mathcal D}[y(\boldsymbol x;\mathcal D)]-h(\boldsymbol x)\right\}^2 ={y(x;D)−ED[y(x;D)]}2+{ED[y(x;D)]−h(x)}2
+ 2 { y ( x ; D ) − E D [ y ( x ; D ) } { E D [ y ( x ; D ) ] − h ( x ) } +2\left\{y(\boldsymbol x;\mathcal D)-\mathbb E_{\mathcal D}[y(\boldsymbol x;\mathcal D)\right\}\left\{\mathbb E_{\mathcal D}[y(\boldsymbol x;\mathcal D)]-h(\boldsymbol x)\right\} +2{y(x;D)−ED[y(x;D)}{ED[y(x;D)]−h(x)}
关于 D \mathcal D D求期望,得
E D [ { y ( x ; D ) − h ( x ) } 2 ] \mathbb E_{{\mathcal D}}[\left\{y(\boldsymbol x;\mathcal D)-h(\boldsymbol x)\right\}^2] ED[{y(x;D)−h(x)}2]= { E D [ y ( x ; D ) ] − h ( x ) } 2 ⎵ ( 偏 置 ) 2 + E D [ { y ( x ; D ) − E D [ y ( x ; D ) ] } 2 ] ⎵ 方 差 =\begin{matrix}\underbrace{\left\{E_{\mathcal D}[y(\boldsymbol x;\mathcal D)]-h(\boldsymbol x)\right\}^2}\\{(偏置)^2}\end{matrix}+\begin{matrix}\underbrace{\mathbb E_{{\mathcal D}}[\left\{y(\boldsymbol x;\mathcal D)-E_{\mathcal D}[y(\boldsymbol x;\mathcal D)]\right\}^2]}\\{方差}\end{matrix} = {ED[y(x;D)]−h(x)}2(偏置)2+ ED[{y(x;D)−ED[y(x;D)]}2]方差
第一项称为平方偏置(bias),表示所有数据集的平均预测与预期的回归函数之间的差异。第二项称为方差(variance),度量了对于单独的数据集,模型所给出的解在平均值附近波动的情况,度量了函数 y ( x , D ) y(\boldsymbol x,\mathcal D) y(x,D)对于特定的数据集的选择的敏感程度
期望平方损失的分解
期 望 损 失 = 偏 置 2 + 方 差 + 噪 声 期望损失=偏置^2+方差+噪声 期望损失=偏置2+方差+噪声
其中
偏 置 2 = ∫ { E D [ y ( x ; D ) ] − h ( x ) } 2 p ( x ) d x 偏置^2=\int \left\{E_{\mathcal D}[y(\boldsymbol x;\mathcal D)]-h(\boldsymbol x)\right\}^2p(\boldsymbol x)d\boldsymbol x 偏置2=∫{ED[y(x;D)]−h(x)}2p(x)dx方 差 = ∫ E D [ { y ( x ; D ) − E D [ y ( x ; D ) ] } 2 ] p ( x ) d x 方差=\int \mathbb E_{{\mathcal D}}[\left\{y(\boldsymbol x;\mathcal D)-E_{\mathcal D}[y(\boldsymbol x;\mathcal D)]\right\}^2]p(\boldsymbol x)d\boldsymbol x 方差=∫ED[{y(x;D)−ED[y(x;D)]}2]p(x)dx
噪 声 = ∫ ∫ { h ( x ) − t } 2 p ( x , t ) d x d t 噪声=\int \int\left\{h(\boldsymbol x)-t\right\}^2p(\boldsymbol x,t)d\boldsymbol xdt 噪声=∫∫{h(x)−t}2p(x,t)dxdt
在偏置和方差之间有一个折中。对于非常灵活的模型来说,偏置较小、方差较大。对于相对固定的模型来说,偏置较大,方差较小。有着最优预测能力的模型是在偏置和方差之间取得最优的平衡的模型。
-
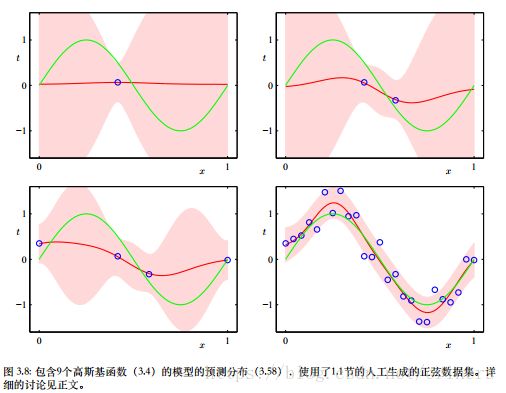
例子:产生100个数据集合,每个集合都包含 N = 25 N=25 N=25个数据点,独立地从正弦曲线 h ( x ) = s i n ( 2 π x ) h(x)=sin(2\pi x) h(x)=sin(2πx)抽取,数据集的编号为 l = 1 , … , L l=1,\ldots,L l=1,…,L,且对于每个数据集 D ( l ) \mathcal D^{(l)} D(l),通过最小化正则化的误差函数拟合了一个带有24个高斯基函数的模型,给出了预测函数 y ( l ) ( x ) y^{(l)}(x) y(l)(x)
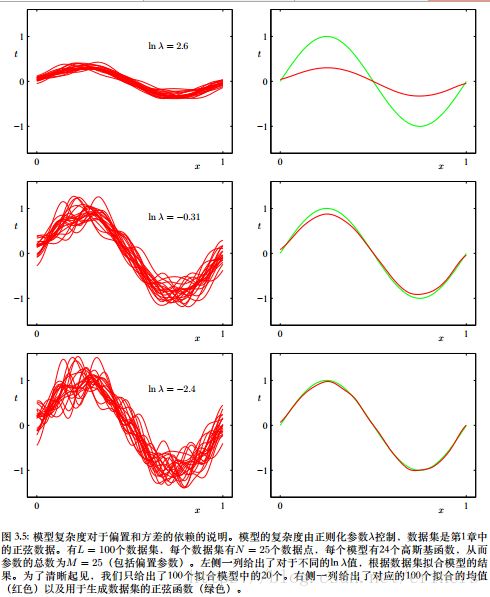
上图中第一行对应着较大的正则化系数 λ \lambda λ,模型的方差很小(看左侧),偏置很大(看右侧);最后一行的正则化系数 λ \lambda λ很小,方差较大,偏置很小。
把 M = 25 M=25 M=25这种复杂模型的多个解进行平均,会产生对于回归函数非常好的拟合,表明平均是一个很好的步骤。将多个解加权平均是贝叶斯方法的核心!这种求平均针对的是参数的后验分布,而不是针对多个数据集。
-
定量考察偏置-方差折中,平均预测由下式求出
y ˉ ( x ) = 1 L ∑ l = 1 L y ( l ) ( x ) \bar y(x)=\frac{1}{L}\sum_{l=1}^Ly^{(l)}(x) yˉ(x)=L1l=1∑Ly(l)(x)
且积分后的平方偏置及积分后的方差为
偏 差 2 = 1 N ∑ n = 1 N { y ˉ ( x n ) − h ( x n ) } 2 偏差^2=\frac{1}{N}\sum_{n=1}^N\left\{\bar y(x_n)-h(x_n)\right\}^2 偏差2=N1n=1∑N{yˉ(xn)−h(xn)}2方 差 = 1 N ∑ n = 1 N 1 L ∑ l = 1 L { y ( l ) ( x n ) − y ˉ ( x n ) } 2 方差=\frac{1}{N}\sum_{n=1}^N\frac{1}{L}\sum_{l=1}^L\left\{y^{(l)}(x_n)-\bar y(x_n)\right\}^2 方差=N1n=1∑NL1l=1∑L{y(l)(xn)−yˉ(xn)}2
其中由概率分布 p ( x ) p(x) p(x)加权的 x x x的积分由来自此概率分布的有限数据点的加和来近似
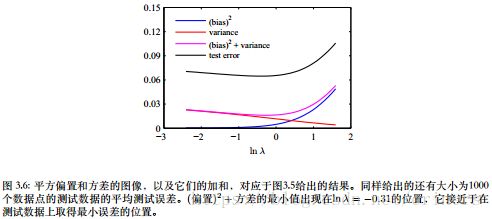
可以看出,小的 λ \lambda λ使得模型对于各个数据集里的噪声的拟合效果非常好,导致了较大的方差。大的 λ \lambda λ把权值参数拉向0,导致了较大的偏置。
-
实用价值有限
因为偏置-方差分解依赖于对所有的数据集求平均,在实际应用中只有一个观测数据集。如果有大量的已知规模的独立的训练数据集,最好的方法是组合成一个大的训练集,这会降低给定复杂度的模型的过拟合程度
3.3贝叶斯线性回归
3.3.1参数分布
-
引入模型参数 w \boldsymbol w w的先验概率分布,把噪声精度参数 β \beta β当作已知常数
似然函数 p ( t ∣ w ) p(\boldsymbol t|\boldsymbol w) p(t∣w)是 w \boldsymbol w w的二次函数的指数形式,对应的共轭先验是高斯分布,形式为
p ( w ) = N ( w ∣ m 0 , S 0 ) p(\boldsymbol w)=\mathcal N(\boldsymbol w|\boldsymbol m_0,\boldsymbol S_0) p(w)=N(w∣m0,S0)
均值为 m 0 \boldsymbol m_0 m0,协方差为 S 0 \boldsymbol S_0 S0后验概率分布的形式
p ( w ∣ t ) = N ( w ∣ m N , S N ) p(\boldsymbol w|\boldsymbol t)=\mathcal N(\boldsymbol w|\boldsymbol m_N,\boldsymbol S_N) p(w∣t)=N(w∣mN,SN)
其中
m N = S N ( S 0 − 1 m 0 + β Φ T t ) \boldsymbol m_N=\boldsymbol S_N(\boldsymbol S_0^{-1}\boldsymbol m_0+\beta\Phi^T\boldsymbol t) mN=SN(S0−1m0+βΦTt)S N − 1 = S 0 − 1 + β Φ T Φ \boldsymbol S_N^{-1}=\boldsymbol S_0^{-1}+\beta\Phi^T\Phi SN−1=S0−1+βΦTΦ
由于后验分布是高斯分布,它的众数与均值相同。(?前面好像有?)因此最大后验权向量的结果即 w M A P = m N \boldsymbol w_{MAP}=\boldsymbol m_N wMAP=mN.考虑一个无限宽的先验 S 0 = α − 1 I \boldsymbol S_0=\alpha^{-1}I S0=α−1I,其中 α → 0 \alpha \to 0 α→0,那么后验概率分布的均值 m N \boldsymbol m_N mN就变成了最大似然值 w M L \boldsymbol w_{ML} wML;类似地,如果 N = 0 N=0 N=0,那么后验概率分布就变成了先验分布;如果数据点是顺序到达的,那么任何一个阶段的后验概率分布都可以看成后续数据点的先验
-
考虑零均值各向同性高斯分布,由精度参数 α \alpha α控制,即
p ( w ∣ α ) = N ( w ∣ 0 , α − 1 I ) p(\boldsymbol w|\alpha)=\mathcal N(\boldsymbol w|0,\alpha^{-1}I) p(w∣α)=N(w∣0,α−1I)
对应的 w \boldsymbol w w的后验概率分布形式同上
p ( w ) = N ( w ∣ m 0 , S 0 ) p(\boldsymbol w)=\mathcal N(\boldsymbol w|\boldsymbol m_0,\boldsymbol S_0) p(w)=N(w∣m0,S0)
其中
m N = β S N Φ T t \boldsymbol m_N=\beta \boldsymbol S_N\Phi^T\boldsymbol t mN=βSNΦTtS N − 1 = α I + β Φ T Φ \boldsymbol S_N^{-1}=\alpha I+\beta \Phi ^T\Phi SN−1=αI+βΦTΦ
后验概率分布的对数由对数似然函数与先验的对数求和的方式得到,形式为
ln p ( w ∣ t ) = − β 2 ∑ n = 1 N { t n − w T ϕ ( x n ) } 2 − α 2 w T w + 常 数 \ln p(\boldsymbol w|\boldsymbol t)=-\frac{\beta}{2}\sum_{n=1}^N\left\{t_n-\boldsymbol w^T\phi(x_n)\right\}^2-\frac{\alpha}{2}\boldsymbol w^T\boldsymbol w+常数 lnp(w∣t)=−2βn=1∑N{tn−wTϕ(xn)}2−2αwTw+常数
后验分布关于 w \boldsymbol w w的最大化等价于对平方和误差函数假设一个正则化项进行最小化,其中 λ = α β \lambda=\frac{\alpha}{\beta} λ=βα -
考虑一个单一输入变量 x x x,一个单一目标变量 t t t,形式为 y ( x , w ) = w 0 + w 1 x y(x,\boldsymbol w)=w_0+w_1x y(x,w)=w0+w1x的线性模型
从函数 f ( x , α ) = α 0 + α 1 x f(x,\boldsymbol \alpha)=\alpha_0+\alpha_1x f(x,α)=α0+α1x中人工生成数据,其中 α 0 = − 0.3 \alpha_0=-0.3 α0=−0.3且 α 1 = 0.5 \alpha_1=0.5 α1=0.5
生成数据的方法为:从均匀分布 U ( x ∣ − 1 , 1 ) U(x|-1,1) U(x∣−1,1)中选择 x n x_n xn的值,计算 f ( x n , α ) f(x_n,\boldsymbol \alpha) f(xn,α),增加一个标准差为0.2的高斯噪声,得到目标变量 t n t_n tn
假设噪声方差是已知的,把精度参数设置为真实值 β = ( 1 0.2 ) 2 = 25 \beta=(\frac{1}{0.2})^2=25 β=(0.21)2=25;类似地把 α \alpha α固定为2.0

图上第一行是观测到任何数据点之前的情况,给出了 w \boldsymbol w w空间的先验概率分布的图像
图上第二行是观测到一个数据点之后的情形,似然函数提供了一个温和的限制,即直线必须穿过数据点附近的位置,其中附近位置的范围由噪声精度 β \beta β确定。
图上第三行是两个数据点
图上第四行是20个数据点
在无穷多个数据点的极限情况下,后验概率分布会变成一个Delta函数,函数的中心是用白色十字标记出的真实参数值
-
高斯先验分布
得到
p ( w ∣ α ) = [ q 2 ( α 2 ) 1 q 1 Γ ( 1 q ) ] M exp ( − α 2 ∑ j = 1 M ∣ w j ∣ q ) p(\boldsymbol w|\alpha)=[\frac{q}{2}(\frac{\alpha}{2})^{\frac{1}{q}}\frac{1}{\Gamma(\frac{1}{q})}]^M\exp (-\frac{\alpha}{2}\sum_{j=1}^M|w_j|^q) p(w∣α)=[2q(2α)q1Γ(q1)1]Mexp(−2αj=1∑M∣wj∣q)
其中 q = 2 q=2 q=2的情形对应于高斯分布,且只有在这种情形下的先验才是共轭先验,找到 w \boldsymbol w w的后验概率分布的最大值对应于找到正则化误差函数的最小值。在高斯先验的情况下,后验概率分布的众数等于均值。若 q ≠ 2 q\ne2 q̸=2,此性质则不成立
3.3.2预测分布
预测分布定义为
p ( t ∣ t , α , β ) = ∫ p ( t ∣ w , β ) p ( w ∣ t , α , β ) d w p(t|\boldsymbol t,\alpha,\beta)=\int p(t|\boldsymbol w,\beta)p(\boldsymbol w|\boldsymbol t,\alpha,\beta)d\boldsymbol w p(t∣t,α,β)=∫p(t∣w,β)p(w∣t,α,β)dw
其中 t \boldsymbol t t是训练数据的目标变量的值组成的向量。此公式涉及到两个高斯分布得卷积,得预测分布的形式为
p ( t ∣ x , t , α , β ) = N ( t ∣ m N T ϕ ( x ) , σ N 2 ( x ) ) p(t|\boldsymbol x,\boldsymbol t,\alpha,\beta)=\mathcal N(t|\boldsymbol m^T_N\phi(\boldsymbol x),\sigma_N^2(\boldsymbol x)) p(t∣x,t,α,β)=N(t∣mNTϕ(x),σN2(x))
其中方差为
σ N 2 ( x ) = 1 β + ϕ ( x ) T S N ϕ ( x ) \sigma_N^2(\boldsymbol x)=\frac{1}{\beta}+\phi(\boldsymbol x)^TS_N\phi(\boldsymbol x) σN2(x)=β1+ϕ(x)TSNϕ(x)
第一项表示数据中的噪声,第二项反映了与参数 w \boldsymbol w w关联的不确定性。由于噪声和 w \boldsymbol w w的分布是相互独立的高斯分布,因此它们的值是可以相加的。注意,当额外的数据点被观测到的时候,后验概率分布会变窄,从而可以证明 σ N + 1 2 ( x ) ≤ σ N 2 ( x ) \sigma_{N+1}^2(\boldsymbol x)\leq \sigma_N^2(\boldsymbol x) σN+12(x)≤σN2(x).在极限 N → ∞ N\to \infty N→∞的情况下,第二项趋于0,从而预测分布的方差只与参数 β \beta β控制的具有可加性的噪声有关。
红色曲线是对应的高斯预测分布的均值,红色阴影区域是均值两侧的一个标准差范围的区域。预测的不确定性依赖于 x x x,并且在数据点的领域内最小。不确定性的程度随着观测到的数据点的增多而逐渐减小

不同的 x x x值的预测之间的协方差。从 w \boldsymbol w w的后验概率分布中抽取样本,得到对应的函数 y ( x , w ) y(x,\boldsymbol w) y(x,w),如上图
使用局部的基函数(例如高斯基函数),在距离基函数中心较远的区域,上式第二项的贡献将会趋于零,只剩下噪声的贡献 β − 1 \beta^{-1} β−1。因此,当对基函数所在的区域之外的区域进行外插的时候,模型对于它所做的预测会变得相当确定。这通常不是我们想要的结果。通过使⽤被称为⾼斯过程的另⼀种贝叶斯回归⽅法,这个问题可以被避免。
如果 w \boldsymbol w w和 β \beta β都被当成是位置的,可以引入一个由高斯-Gamma分布定义的共轭先验分布 p ( w , β ) p(\boldsymbol w,\beta) p(w,β),在这种情况下,预测分布是一个学生t分布
3.3.3等价核
把线性基函数模型的后验均值 m N = β S N Φ T t \boldsymbol m_N=\beta \boldsymbol S_N\Phi^T\boldsymbol t mN=βSNΦTt代入 y ( x , w ) = ∑ j = 0 M − 1 w j ϕ j ( x ) = w T ϕ ( x ) y(\boldsymbol x,\boldsymbol w)=\sum_{j=0}^{M-1}w_j\phi_j(\boldsymbol x)=\boldsymbol w^T\phi(\boldsymbol x) y(x,w)=∑j=0M−1wjϕj(x)=wTϕ(x)中,预测均值可以写成
y ( x , m N ) = m N T ϕ ( x ) = β ϕ ( x ) T S N Φ T t = ∑ n = 1 N β ϕ ( x ) T S N ϕ ( x n ) t n y(\boldsymbol x,\boldsymbol m_N)=\boldsymbol m_N^T\phi(x)=\beta\phi(\boldsymbol x)^T\boldsymbol S_N\Phi^T\boldsymbol t=\sum_{n=1}^N\beta\phi(\boldsymbol x)^T\boldsymbol S_N\phi(\boldsymbol x_n)t_n y(x,mN)=mNTϕ(x)=βϕ(x)TSNΦTt=n=1∑Nβϕ(x)TSNϕ(xn)tn
因此在 x \boldsymbol x x处的预测均值由训练集目标变量 t n t_n tn的线性组合给出,即
y ( x , m N ) = ∑ n = 1 N k ( x , x n ) t n y(\boldsymbol x,\boldsymbol m_N)=\sum_{n=1}^Nk(\boldsymbol x,\boldsymbol x_n)t_n y(x,mN)=n=1∑Nk(x,xn)tn
其中,
k ( x , x ′ ) = β ϕ ( x ) T S N ϕ ( x ′ ) k(\boldsymbol x,\boldsymbol x^{'})=\beta \phi(\boldsymbol x)^T\boldsymbol S_N\phi(\boldsymbol x^{'}) k(x,x′)=βϕ(x)TSNϕ(x′)
被称为平滑矩阵(smoother matrix)或者等价核(equivalent kernel),像这样的回归函数通过对训练集里目标值进行线性组合做预测称为线性平滑(linear smoother)
等价核依赖于来自数据集的输入值 x n \boldsymbol x_n xn,这些输入值出现在 S N \boldsymbol S_N SN中

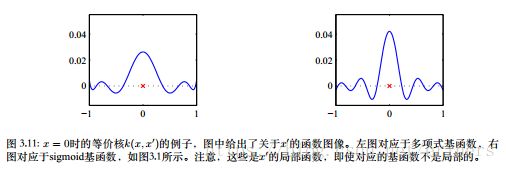
上图给出了三个不同的 x x x值的情况下,核函数 k ( x , x ′ ) k(x,x^{'}) k(x,x′)与 x ′ x^{'} x′的函数关系(这幅图没看懂)它们在局限在 x x x的周围,因此在 x x x处的预测分布的均值 y ( x , m N ) y(x,\boldsymbol m_N) y(x,mN)可以通过对⽬标值加权组合的⽅式获得。距离 x x x较近的数据点可以赋⼀个较⾼的权值,⽽距离 x x x较远的数据点可以赋⼀个较低的权值。直观来看,与远处的证据相⽐,我们把局部的证据赋予更⾼的权值似乎是更合理的。
这种局部性不仅对于局部的高斯基函数成立,对于非局部的多项式基函数和sigmoid基函数也成立
考虑 y ( x ) y(\boldsymbol x) y(x)和 y ( x ) ′ y(\boldsymbol x)^{'} y(x)′的协方差
c o v [ y ( x ) , y ( x ) ′ ] = c o v [ ϕ ( x ) T w , w T ϕ ( x ′ ) ] = ϕ ( x ) T S N ϕ ( x ′ ) = β − 1 k ( x , x ′ ) \mathrm{cov}[y(\boldsymbol x),y(\boldsymbol x)^{'}]=\mathrm{cov}[\phi(\boldsymbol x)^T\boldsymbol w,\boldsymbol w^T\phi(\boldsymbol x^{'})]=\phi(\boldsymbol x)^T\boldsymbol S_N\phi(\boldsymbol x^{'})=\beta^{-1}k(\boldsymbol x,\boldsymbol x^{'}) cov[y(x),y(x)′]=cov[ϕ(x)Tw,wTϕ(x′)]=ϕ(x)TSNϕ(x′)=β−1k(x,x′)
k可以看到在附近的点处的预测均值相关性较高,而距离较远的点对相关性较低
-
用核函数表示线性回归
给出了解决回归问题的另一种方法,不引入一组基函数(隐式地定义了一个等价的核),而是直接定义一个局部的核函数,然后在给定观测数据集的条件下,使用这个核函数对新的输入变量 x \boldsymbol x x做预测。这就是用于回归问题(及分类问题)的一个很实用的框架,叫高斯过程
-
等价核定义了模型的权值
通过这个权值,训练数据集里的目标值被组合,然后对新的 x \boldsymbol x x做预测,这些权值的和等于1,即
∑ n = 1 N k ( x , x n ) = 1 \sum_{n=1}^Nk(\boldsymbol x,\boldsymbol x_n)=1 n=1∑Nk(x,xn)=1
对于所有的 x \boldsymbol x x值都成立。等价于对所有的 n n n都有 t n = 1 t_n=1 tn=1的目标数据集的预测均值 y ^ ( x ) \hat y(\boldsymbol x) y^(x).假设基函数是线性独立的,且数据点的数量多于基函数的数量,且其中一个基函数是常量(对应于偏置参数),那么可以精确地拟合训练数据,因此预测均值就是简单的 y ^ ( x ) = 1 \hat y(\boldsymbol x)=1 y^(x)=1.
注意,核函数可以为负也可以为正,因此虽然满足加和限制,但对应的预测未必是训练集的目标值的凸组合
-
等价核满足一般核函数共有的重要性质,即
k ( x , z ) = ψ ( x ) T ψ ( Z ) k(\boldsymbol x,\boldsymbol z)=\psi(\boldsymbol x)^T\psi(\boldsymbol Z) k(x,z)=ψ(x)Tψ(Z)
其中 ψ ( x ) = β 1 2 S N 1 2 ψ ( x ) \psi(\boldsymbol x)=\beta^{\frac{1}{2}}\boldsymbol S_N^{\frac{1}{2}}\psi(\boldsymbol x) ψ(x)=β21SN21ψ(x)
3.4贝叶斯模型比较
-
使用概率来表示模型选择的不确定性,恰当地使用概率的加和规则和乘积规则
-
假设比较 L L L个模型{ M i \mathcal M_i Mi},一个模型指的是观测数据 D \mathcal D D上的概率分布
在多项式曲线拟合的问题中,概率分布被定义在目标值 t \boldsymbol t t上,而输入值 x \boldsymbol x x被假定为已知的。其他类型的模型定义了 x \boldsymbol x x和 t \boldsymbol t t上的联合分布。
假设数据是由这些模型中的一个生成的,但不清楚究竟是哪一个,不确定性通过先验概率分布 p ( M i ) p(\mathcal M_i) p(Mi)表示
给定一个训练数据集 D \mathcal D D,估计后验分布
p ( M i ∣ D ) ∝ p ( M i ) p ( D ∣ M i ) p(\mathcal M_i|\mathcal D)\propto p(\mathcal M_i)p(\mathcal D|\mathcal M_i) p(Mi∣D)∝p(Mi)p(D∣Mi)
先验分布能表达不同模型之间的优先级。假设所有的模型都有相同的先验概率模型证据(model evidence) p ( D ∣ M i ) p(\mathcal D|\mathcal M_i) p(D∣Mi)表达了数据展现出的不同的模型的优先级,也称为边缘似然(marginal likelihood),可以被看作在模型空间中的似然函数,在这个空间中参数已经被求和或者积分
贝叶斯因子(Bayes factor)是两个模型的模型证据的比值 p ( D ∣ M i ) p ( D ∣ M j ) \frac{p(\mathcal D|\mathcal M_i)}{p(\mathcal D|\mathcal M_j)} p(D∣Mj)p(D∣Mi)
根据概率的加和与乘积规则,预测分布为
p ( t ∣ x , D ) = ∑ i = 1 L p ( t ∣ x , M i , D ) p ( M i ∣ D ) p(t|\boldsymbol x,\mathcal D)=\sum_{i=1}^Lp(t|\boldsymbol x,\mathcal M_i,\mathcal D)p(\mathcal M_i|\mathcal D) p(t∣x,D)=i=1∑Lp(t∣x,Mi,D)p(Mi∣D)
这是混合分布(mixture distribution)的一个例子。在这个公式中,整体的预测分布由下面的方式获得:对各个模型的预测分布 p ( t ∣ x , M i , D ) p(t|\boldsymbol x,\mathcal M_i,\mathcal D) p(t∣x,Mi,D)求加权平均,权值为这些模型的后验概率 p ( M i ∣ D ) p(\mathcal M_i|\mathcal D) p(Mi∣D) -
例子:两个模型,后验概率相等。一个模型预测了 t = a t=a t=a附近的一个很窄的分布,另一个模型预测了 t = b t=b t=b附近的一个很窄的分布。这样整体的预测分布是一个双峰的概率分布,峰值位于 t = a t=a t=a和 t = b t=b t=b处,而不是在 t = a + b 2 t=\frac{a+b}{2} t=2a+b处的一个单一模型
-
模型选择(model selection)
使用对可能的一个模型自己做预测是对于模型求平均的一个简单的近似
对于一个由参数 w \boldsymbol w w控制的模型,根据概率的加和规则和乘积规则,模型证据为
p ( D ∣ M i ) = ∫ p ( D ∣ w , M i ) p ( w ∣ M i ) d w p(\mathcal D|\mathcal M_i)=\int p(\mathcal D|\boldsymbol w,\mathcal M_i)p(\boldsymbol w|\mathcal M_i)d\boldsymbol w p(D∣Mi)=∫p(D∣w,Mi)p(w∣Mi)dw
从取样的角度看,边缘似然函数可被看成从一个模型中生成数据集 D \mathcal D D的概率,此模型的参数是从先验分布中随机取样的。模型证据恰好是在估计参数的后验分布时出现在贝叶斯定理的分母中的归一化项,因为
p ( w ∣ D , M i ) = p ( D ∣ w , M i ) p ( w ∣ M i ) p ( D ∣ M i ) p(\boldsymbol w|\mathcal D,\mathcal M_i)=\frac{p(\mathcal D|\boldsymbol w,\mathcal M_i)p(\boldsymbol w|\mathcal M_i)}{p(\mathcal D|\mathcal M_i)} p(w∣D,Mi)=p(D∣Mi)p(D∣w,Mi)p(w∣Mi) -
认识模型证据,对参数的积分进行一个简单的近似
-
首先考虑模型有一个参数 w \boldsymbol w w的情形,参数的后验概率正比于 p ( D ∣ w ) p ( w ) p(\mathcal D|w)p(w) p(D∣w)p(w)(省略了对模型 M i \mathcal M_i Mi的依赖)
假设后验分布在最大似然值 w M A P w_{MAP} wMAP附近是一个尖峰,宽度为 Δ w 后 验 \Delta w_{后验} Δw后验,用被积函数的值乘以尖峰的宽度来近似这个积分。进一步假设先验分布是平的,宽度为 Δ w 先 验 \Delta w_{先验} Δw先验,即 p ( w ) = 1 Δ w 先 验 p(w)=\frac{1}{\Delta w_{先验}} p(w)=Δw先验1,有
p ( D ) = ∫ p ( D ∣ w ) p ( w ) d w ≅ p ( D ∣ w M A P ) Δ w 后 验 Δ w 先 验 p(\mathcal D)=\int p(\mathcal D|w)p(w)dw \cong p(\mathcal D|w_{MAP})\frac{\Delta w_{后验}}{\Delta w_{先验}} p(D)=∫p(D∣w)p(w)dw≅p(D∣wMAP)Δw先验Δw后验
取对数得
ln p ( D ) ≅ ln p ( D ∣ w M A P ) + ln ( Δ w 后 验 Δ w 先 验 ) \ln p(\mathcal D)\cong \ln p(\mathcal D|w_{MAP})+\ln(\frac{\Delta w_{后验}}{\Delta w_{先验}}) lnp(D)≅lnp(D∣wMAP)+ln(Δw先验Δw后验)

第一项表示拟合由最可能参数给出的数据。对于平的先验分布来说,对应于对数似然。
第二项用于根据模型的复杂度来惩罚模型。由于 Δ w 后 验 < Δ w 先 验 \Delta w_{后验}<\Delta w_{先验} Δw后验<Δw先验,为负,随着 Δ w 后 验 Δ w 先 验 \frac{\Delta w_{后验}}{\Delta w_{先验}} Δw先验Δw后验的减小,这一项的绝对值增加。因此,如果参数精确地调整为后验分布的数据,惩罚项会很大
-
有 M M M个参数的模型,对每个参数进行类似的近似
假设所有的参数的 Δ w 后 验 Δ w 先 验 \frac{\Delta w_{后验}}{\Delta w_{先验}} Δw先验Δw后验相同,有
ln p ( D ) ≅ ln p ( D ∣ w M A P ) + M ln ( Δ w 后 验 Δ w 先 验 ) \ln p(\mathcal D)\cong \ln p(\mathcal D|w_{MAP})+M\ln(\frac{\Delta w_{后验}}{\Delta w_{先验}}) lnp(D)≅lnp(D∣wMAP)+Mln(Δw先验Δw后验)
复杂度惩罚项的大小随着模型中可调节参数 M M M的数量线性增加增加模型的复杂度,第一项通常会增大,因为一个更复杂的模型能更好地拟合数据;第二项会减小,因为它依赖于 M M M.由最大模型证据确定的最优的模型复杂度需要在这两个相互竞争的项之间进行折中
-
-
认识贝叶斯模型比较
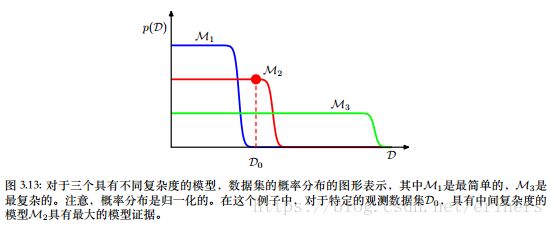
图中横轴是可能的数据集构成的空间的一维表示,轴上的每个点对应着一个具体的数据集。假设让这三个模型自动产生样本数据集,观察生成数据集的分布。任意给定的模型都能生成一系列不同的数据集,因为模型的参数由先验概率分布控制,对于任意一种参数的选择,在目标变量上都可能有随机的噪声。
为了从具体的模型中⽣成⼀个特定的数据集, ⾸先从先验分布 p ( w ) p(w) p(w)中选择参数的值,然后对于这些参数的值,我们按照概率 p ( D ∣ w ) p(\mathcal D|w) p(D∣w)对数据进⾏采样。
简单的模型(例如基于一阶多项式的模型)几乎没有变化性,生成的数据集之间十分相似,于是它的分布 p ( D ) p(\mathcal D) p(D)被限制在横轴的一个相对小的区域
复杂的模型(例如九阶多项式)可以生成变化性相当大的数据集,分布 p ( D ) p(\mathcal D) p(D)遍布了数据集空间的一个相当大的区域。
由于概率分布 p ( D , M i ) p(\mathcal D,\mathcal M_i) p(D,Mi)是归一化的,因此特定的数据集 D 0 \mathcal D_0 D0对中等复杂度的模型有最高的模型证据。
本质上说,简单的模型不能很好地拟合数据,⽽复杂的模型把它的预测概率散布于过多的可能的数据集当中,从⽽对它们当中的每⼀个赋予的概率都相对较⼩。
-
贝叶斯模型比较框架的优劣
隐含了一个假设,生成数据的真实的概率分布包含在考虑的模型集合中。
平均来看,贝叶斯模型会比较倾向于选择出正确的模型。
证明:考虑两个模型 M 1 \mathcal M_1 M1和 M 2 \mathcal M_2 M2,其中真实的概率分布对应于模型 M 1 \mathcal M_1 M1。对于给定的有限数据集,确实有可能出现错误的模型反⽽使贝叶斯因⼦较⼤的事情。 但是,如果把贝叶斯因⼦在数据集分布上进⾏平均,得到期望贝叶斯因子
∫ p ( D ∣ M 1 ) ln p ( D ∣ M 1 ) p ( D ∣ M 2 ) d D \int p(\mathcal D|\mathcal M_1)\ln \frac{p(\mathcal D|\mathcal M_1)}{p(\mathcal D|\mathcal M_2)}d\mathcal D ∫p(D∣M1)lnp(D∣M2)p(D∣M1)dD
上式是关于数据的真实分布求得平均值。这是Kullback-Leibler散度的⼀个例⼦,满⾜下⾯的性 质:如果两个分布相等,则Kullback-Leibler散度等于零,否则恒为正。因此平均来讲,贝叶斯因⼦总会倾向于选择正确的模型。优:避免了过拟合,使得模型能基于训练数据自身进行对比
劣:需要对模型得形式做出假设,假设不合理,结果就错

可以看出模型证据对先验分布的很多方面都很敏感,例如在低概率处的行为
如果先验分布是反常的,那么模型证据⽆法定义,因为反常的先验分布有着任意的缩放因⼦(换句话说,归⼀化系数⽆法 定义,因为分布根本⽆法被归⼀化)。
如果我们考虑⼀个正常的先验分布,然后取⼀个适当的极限来获得⼀个反常的先验(例如⾼斯先验中,我们令⽅差为⽆穷⼤),那么模型证据就会趋于零,这可以从上图中看出来。但是这种情况下也可能通过⾸先考虑两个模型的证据⽐值,然后取极限的⽅式来得到⼀个有意义的答案。
在实际应⽤中,⼀种明智的做法是,保留⼀个独⽴的测试数据集,⽤来评估最终系统的整体表现。
3.5证据近似
在处理线性基函数模型的纯粹的贝叶斯方法中,会引入超参数 α \alpha α和 β \beta β的先验分布,然后通过对超参数及参数 w \boldsymbol w w求积分的方式做预测。
虽然可以解析地求出对 w \boldsymbol w w的积分或者求出对超参数的积分,但是对所有变量完整地求积分是没有解析解的。
-
一种近似方法----经验贝叶斯(empirical Bayes)或第二类最大似然(type2 maximumu likelihood)或推广的最大似然(generalized maximum likelihood)或证据近似(evidence approximation)
首先对参数 w \boldsymbol w w求积分,得到边缘似然函数,最大化边缘似然函数,确定超参数的值
引入 α \alpha α和 β \beta β上的超先验分布,预测分布可以通过对 w , α , β w,\alpha,\beta w,α,β求积分的方法得
p ( t ∣ t ) = ∫ ∫ ∫ p ( t ∣ w , β ) p ( w ∣ t , α , β ) p ( α , β ∣ t ) d w d α d β p(t|\boldsymbol t)=\int\int\int p(t|\boldsymbol w,\beta)p(\boldsymbol w|\boldsymbol t,\alpha,\beta)p(\alpha,\beta|\boldsymbol t)d\boldsymbol wd\alpha d\beta p(t∣t)=∫∫∫p(t∣w,β)p(w∣t,α,β)p(α,β∣t)dwdαdβ
根据贝叶斯定理, α \alpha α和 β \beta β的后验分布为
p ( α , β ∣ t ) ∝ p ( t ∣ α , β ) p ( α , β ) p(\alpha,\beta|\boldsymbol t)\propto p(\boldsymbol t|\alpha,\beta)p(\alpha,\beta) p(α,β∣t)∝p(t∣α,β)p(α,β)
如果先验分布相对⽐较平,那么在证据框架中, α ^ \hat \alpha α^和 β ^ \hat \beta β^可以通过最⼤化边缘似然函数 p ( t ∣ α , β ) p(\boldsymbol t|\alpha,\beta) p(t∣α,β)来获得。计算线性基函数模型的边缘似然函数,找到最⼤值。能从训练数据本⾝确定这些超参数的值,⽽不需要交叉验证。值得注意的⼀点是,如果我们定义 α \alpha α和 β \beta β上的共轭(Gamma)先验分布,那么超参数求积分可以解析地计算出来,得到 w \boldsymbol w w上的学⽣t分布
可以使⽤拉普拉斯近似⽅法对这个积分求近似。
拉普拉斯近似⽅法的基础是以后验概率分布的众数为中⼼的局部⾼斯近似⽅法。然⽽,作为 w \boldsymbol w w的函数的被积函数的众数通常很不准确,因此拉普拉斯近似⽅法不能描述概率质量中的⼤部分信息。导致最终的结果要⽐最⼤化证据的⽅法给出的结果更差 。
两种最大化对数证据的方法:解析地计算证据函数令导数等于0得到对于 α \alpha α和 β \beta β的重新估计房产;使用期望最大化(EM)算法。
这两种方法会收敛到同一个解
3.5.1计算证据函数
边缘似然函数 p ( t ∣ α , β ) p(\boldsymbol t|\alpha,\beta) p(t∣α,β)是通过对权值参数 w \boldsymbol w w进行积分得到的,即
p ( t ∣ α , β ) = ∫ p ( t ∣ w , β ) p ( w ∣ α ) d w p(\boldsymbol t|\alpha,\beta)=\int p(\boldsymbol t|\boldsymbol w,\beta)p(\boldsymbol w|\alpha)d\boldsymbol w p(t∣α,β)=∫p(t∣w,β)p(w∣α)dw
根据公式
ln p ( t ∣ w , β ) = ∑ n = 1 N ln N ( t n ∣ w T ϕ ( x n ) , β − 1 ) = N 2 ln β − N 2 ln ( 2 π ) − β E D ( w ) \ln p(\boldsymbol t|\boldsymbol w,\beta)=\sum_{n=1}^N\ln \mathcal N(t_n|\boldsymbol w^T\phi(\boldsymbol x_n),\beta^{-1})=\frac{N}{2}\ln\beta-\frac{N}{2}\ln(2\pi)-\beta E_D(\boldsymbol w) lnp(t∣w,β)=n=1∑NlnN(tn∣wTϕ(xn),β−1)=2Nlnβ−2Nln(2π)−βED(w)
E D ( w ) = 1 2 ∑ n = 1 N { t n − w T ϕ ( x n ) } 2 E_D(\boldsymbol w)=\frac{1}{2}\sum_{n=1}^N\left\{t_n-\boldsymbol w^T\phi(\boldsymbol x_n)\right\}^2 ED(w)=21n=1∑N{tn−wTϕ(xn)}2
p ( w ∣ α ) = N ( w ∣ 0 , α − 1 I ) p(\boldsymbol w|\alpha)=\mathcal N(\boldsymbol w|0,\alpha^{-1}I) p(w∣α)=N(w∣0,α−1I)
可以把证据函数写成
p ( t ∣ α , β ) = ( β 2 π ) N 2 ( α 2 π ) M 2 ∫ exp { − E ( w ) } d w p(\boldsymbol t|\alpha,\beta)=(\frac{\beta}{2\pi})^{\frac{N}{2}}(\frac{\alpha}{2\pi})^{\frac{M}{2}}\int \exp\left\{-E(\boldsymbol w)\right\}d\boldsymbol w p(t∣α,β)=(2πβ)2N(2πα)2M∫exp{−E(w)}dw
其中 M M M是 w \boldsymbol w w的维数,且定义
E ( w ) = β E D ( w ) + α E W ( w ) = β 2 ∣ ∣ t − Φ w ∣ ∣ 2 + α 2 w T w E(\boldsymbol w)=\beta E_D(\boldsymbol w)+\alpha E_W(\boldsymbol w)=\frac{\beta}{2}||\boldsymbol t-\Phi\boldsymbol w||^2+\frac{\alpha}{2}\boldsymbol w^T\boldsymbol w E(w)=βED(w)+αEW(w)=2β∣∣t−Φw∣∣2+2αwTw
可以看到忽略一些比例常数,上式等于正则化的平方和误差函数
对 w \boldsymbol w w配平方,得
E ( w ) = E ( m N ) + 1 2 ( w − m N ) T A ( w − m N ) E(\boldsymbol w)=E(\boldsymbol m_N)+\frac{1}{2}(\boldsymbol w-\boldsymbol m_N)^T \boldsymbol A(\boldsymbol w-\boldsymbol m_N) E(w)=E(mN)+21(w−mN)TA(w−mN)
其中令
A = α I + β Φ T Φ \boldsymbol A=\alpha I+\beta\Phi^T\Phi A=αI+βΦTΦ
E ( m N ) = β 2 ∣ ∣ t − Φ m N ∣ ∣ 2 + β 2 m N T m N E(\boldsymbol m_N)=\frac{\beta}{2}||\boldsymbol t-\Phi \boldsymbol m_N||^2+\frac{\beta}{2}\boldsymbol m_N^T\boldsymbol m_N E(mN)=2β∣∣t−ΦmN∣∣2+2βmNTmN
A \boldsymbol A A对应于误差函数的二阶导数
A = ∇ ∇ E ( w ) \boldsymbol A=\nabla\nabla E(\boldsymbol w) A=∇∇E(w)
被称为Hessian矩阵
定义 m N \boldsymbol m_N mN为
m N = β A − 1 Φ T t \boldsymbol m_N=\beta \boldsymbol A^{-1}\Phi^T \boldsymbol t mN=βA−1ΦTt
使用公式 S N − 1 = S 0 − 1 + β Φ T Φ \boldsymbol S_N^{-1}=\boldsymbol S_0^{-1}+\beta\Phi^T\Phi SN−1=S0−1+βΦTΦ,看到 A = S N − 1 \boldsymbol A=\boldsymbol S_N^{-1} A=SN−1.因此 m N = β A − 1 Φ T t \boldsymbol m_N=\beta \boldsymbol A^{-1}\Phi^T \boldsymbol t mN=βA−1ΦTt等价于 m N = β S N Φ T t \boldsymbol m_N=\beta \boldsymbol S_N\Phi^T\boldsymbol t mN=βSNΦTt,表示后验概率分布的均值
比较多元高斯分布的归一化系数,关于 w \boldsymbol w w的积分即
∫ exp { − E ( w ) } d w = exp { − E ( m N ) } ∫ exp { − 1 2 ( w − m N ) T A ( w − m N ) } d w \int \exp\left\{-E(\boldsymbol w)\right\}d\boldsymbol w=\exp\left\{-E(\boldsymbol m_N)\right\}\int \exp\left\{-\frac{1}{2}(\boldsymbol w-\boldsymbol m_N)^T\boldsymbol A(\boldsymbol w-\boldsymbol m_N)\right\}d\boldsymbol w ∫exp{−E(w)}dw=exp{−E(mN)}∫exp{−21(w−mN)TA(w−mN)}dw
= exp { − E ( m N ) } ( 2 π ) M 2 ∣ A ∣ − 1 2 =\exp\left\{-E(\boldsymbol m_N)\right\}(2\pi)^{\frac{M}{2}}|\boldsymbol A|^{-\frac{1}{2}} =exp{−E(mN)}(2π)2M∣A∣−21
使用公式 p ( t ∣ α , β ) = ( β 2 π ) N 2 ( α 2 π ) M 2 ∫ exp { − E ( w ) } d w p(\boldsymbol t|\alpha,\beta)=(\frac{\beta}{2\pi})^{\frac{N}{2}}(\frac{\alpha}{2\pi})^{\frac{M}{2}}\int \exp\left\{-E(\boldsymbol w)\right\}d\boldsymbol w p(t∣α,β)=(2πβ)2N(2πα)2M∫exp{−E(w)}dw,把边缘似然函数的对数写成
ln p ( t ∣ α , β ) = M 2 ln α + N 2 ln β − E ( m N ) − 1 2 ln ∣ A ∣ − N 2 ln ( 2 π ) \ln p(\boldsymbol t|\alpha,\beta)=\frac{M}{2}\ln \alpha+\frac{N}{2}\ln\beta-E(\boldsymbol m_N)-\frac{1}{2}\ln|\boldsymbol A|-\frac{N}{2}\ln(2\pi) lnp(t∣α,β)=2Mlnα+2Nlnβ−E(mN)−21ln∣A∣−2Nln(2π)
这就是证据函数的表达式

图中假定先验分布的形式为 p ( w ∣ α ) = N ( w ∣ y ( 0 , α − 1 I ) = ( α 2 π ) M + 1 2 exp { − α 2 w T w } p(\boldsymbol w|\alpha)=\mathcal N(\boldsymbol w|y(\boldsymbol 0,\alpha ^{-1}\boldsymbol I)=(\frac{\alpha}{2\pi})^{\frac{M+1}{2}}\exp\left\{-\frac{\alpha}{2}\boldsymbol w^T\boldsymbol w\right\} p(w∣α)=N(w∣y(0,α−1I)=(2πα)2M+1exp{−2αwTw}
参数 α \alpha α的值固定为 α = 0.005 \alpha=0.005 α=0.005

可以看到 M = 0 M=0 M=0的多项式对数据的拟合效果⾮常差,结果模型证据的值也相对较⼩。 $M= 1 的 多 项 式 对 于 数 据 的 拟 合 效 果 有 了 显 著 的 提 升 , 因 此 模 型 证 据 变 ⼤ 了 。 但 是 , 对 于 1的多项式对于数据的拟合效果有了显著的提升,因此模型证据变⼤了。但是,对于 1的多项式对于数据的拟合效果有了显著的提升,因此模型证据变⼤了。但是,对于M=2$的多项式,拟合效果又变得很差,因为产⽣数据的正弦函数是奇函数,因此在多项式展开中没有偶次项。
可以看出数据残差从 M = 1 M=1 M=1到 M = 2 M=2 M=2只有微小的减小。由于复杂的模型有着更⼤的复杂度惩罚项,因此从 M = 1 M=1 M=1到 M = 2 M=2 M=2,模型证据实际上减⼩了。当 M = 3 M=3 M=3时,我们对于数据的拟合效果有了很⼤的提升,因此模型证据再次增⼤,给出了多项式拟合的最⾼的模型证据。进⼀步增加 M M M的值,只能少量地提升拟合的效果,但是模型的复杂度却越来越复杂,这导致整体的模型证据会下降。
看到泛化错误在 M = 3 M=3 M=3到 M = 8 M=8 M=8之间⼏乎为常数,因此单独基于这幅图很难对模型做出选择。然⽽,模型证据的值明显地倾向于选择 M = 3 M=3 M=3的模型,因为这是能很好地解释观测数据的最简单的模型。
3.5.2最大化证据函数
-
考虑 p ( t ∣ α , β ) p(\boldsymbol t|\alpha,\beta) p(t∣α,β)关于 α \alpha α的最大化
定义特征向量方程
( β Φ T Φ ) u i = λ i u i (\beta\Phi^T\Phi)\boldsymbol u_i=\lambda_i\boldsymbol u_i (βΦTΦ)ui=λiui
根据 A = α I + β Φ T Φ \boldsymbol A=\alpha I+\beta\Phi^T\Phi A=αI+βΦTΦ,可知 A \boldsymbol A A的特征值为 α + λ i \alpha+\lambda_i α+λi.考虑公式 ln p ( t ∣ α , β ) = M 2 ln α + N 2 ln β − E ( m N ) − 1 2 ln ∣ A ∣ − N 2 ln ( 2 π ) \ln p(\boldsymbol t|\alpha,\beta)=\frac{M}{2}\ln \alpha+\frac{N}{2}\ln\beta-E(\boldsymbol m_N)-\frac{1}{2}\ln|\boldsymbol A|-\frac{N}{2}\ln(2\pi) lnp(t∣α,β)=2Mlnα+2Nlnβ−E(mN)−21ln∣A∣−2Nln(2π)中涉及到 ln ∣ A ∣ \ln|\boldsymbol A| ln∣A∣的项关于 α \alpha α的导数
d d α ln ∣ A ∣ = d d α ln ∏ i ( λ i + α ) = d d α ∑ i ln ( λ i + α ) = ∑ i 1 λ i + α \frac{d}{d\alpha}\ln|\boldsymbol A|=\frac{d}{d\alpha}\ln \prod_i(\lambda_i+\alpha)=\frac{d}{d\alpha}\sum_i\ln (\lambda_i+\alpha)=\sum_i\frac{1}{\lambda_i+\alpha} dαdln∣A∣=dαdlni∏(λi+α)=dαdi∑ln(λi+α)=i∑λi+α1
因此关于 α \alpha α的驻点满足
0 = M 2 α − 1 2 m N T m N − 1 2 ∑ i 1 λ i + α 0=\frac{M}{2\alpha}-\frac{1}{2}\boldsymbol m_N^T\boldsymbol m_N-\frac{1}{2}\sum_i\frac{1}{\lambda_i+\alpha} 0=2αM−21mNTmN−21i∑λi+α1
两侧乘以 2 α 2\alpha 2α,整理得
α m N T m N = M − α ∑ i 1 λ i + α = γ \alpha \boldsymbol m_N^T\boldsymbol m_N=M-\alpha\sum_i\frac{1}{\lambda_i+\alpha}=\gamma αmNTmN=M−αi∑λi+α1=γ
由于 i i i的求和式中一共有 M M M项,因此 γ \gamma γ可以写成
γ = ∑ i λ i α + λ i \gamma=\sum_i\frac{\lambda_i}{\alpha+\lambda_i} γ=i∑α+λiλi
最大化边缘似然函数的 α \alpha α满足
α = γ m N T m N \alpha=\frac{\gamma}{\boldsymbol m_N^T\boldsymbol m_N} α=mNTmNγ
这是 α \alpha α的一个隐式解,因为 γ \gamma γ与 α \alpha α相关,后验概率本身的众数 m N \boldsymbol m_N mN与 α \alpha α的选择有关。因此使用迭代的方法求解。首先选择一个 α \alpha α的初始值,使用初始值找到 m N \boldsymbol m_N mN,计算 γ \gamma γ,估计 α \alpha α。这个过程不断进行,直到收敛。
由于 Φ T Φ \Phi^T\Phi ΦTΦ是固定的,可以在最开始的时候计算一次特征值,只需乘以 β \beta β即可得到 λ i \lambda_i λi的值
α \alpha α的值是纯粹通过观察训练集确定的。与最大似然方法不同,最优化模型复杂度不需要独立的数据集
-
关于 β \beta β最大化对数边缘似然函数
( β Φ T Φ ) u i = λ i u i (\beta\Phi^T\Phi)\boldsymbol u_i=\lambda_i\boldsymbol u_i (βΦTΦ)ui=λiui定义的特征值 λ i \lambda_i λi正比于 β \beta β,因此 d d β = λ i β \frac{d}{d\beta}=\frac{\lambda_i}{\beta} dβd=βλi于是
d d β ln ∣ A ∣ = d d β ∑ i ln ( λ i + α ) = 1 β ∑ i λ i λ i + α = γ β \frac{d}{d\beta}\ln|\boldsymbol A|=\frac{d}{d\beta}\sum_i\ln(\lambda_i+\alpha)=\frac{1}{\beta}\sum_i\frac{\lambda_i}{\lambda_i+\alpha}=\frac{\gamma}{\beta} dβdln∣A∣=dβdi∑ln(λi+α)=β1i∑λi+αλi=βγ
边缘似然函数的驻点满足
0 = N 2 α − 1 2 ∑ n = 1 N { t n − m N T ϕ ( x n ) } 2 − γ 2 β 0=\frac{N}{2\alpha}-\frac{1}{2}\sum_{n=1}^N\left\{t_n-\boldsymbol m_N^T\phi(\boldsymbol x_n)\right\}^2-\frac{\gamma}{2\beta} 0=2αN−21n=1∑N{tn−mNTϕ(xn)}2−2βγ
整理得
1 β = 1 N − γ ∑ n = 1 N { t n − m N T ϕ ( x n ) } 2 \frac{1}{\beta}=\frac{1}{N-\gamma}\sum_{n=1}^N\left\{t_n-\boldsymbol m_N^T\phi(\boldsymbol x_n)\right\}^2 β1=N−γ1n=1∑N{tn−mNTϕ(xn)}2
这是 β \beta β的⼀个隐式解,可以通过迭代的⽅法解出。⾸先选择 β \beta β的⼀个初始值,然后使⽤这个初始值计算 m N \boldsymbol m_N mN和 γ \gamma γ,然后重新估计 β \beta β的值,重复直到收敛。
如果 α \alpha α和 β \beta β的值都要从数据中确定,那么他们的值可以在每次更新 γ \gamma γ之后⼀起重新估计。
3.5.3参数的有效数量
考虑似然函数的轮廓线及先验概率分布

隐式地把参数空间的坐标轴进⾏了旋转变换,使其与特征向量对齐。似然函数的轮廓线变成轴对齐的椭圆。特征值 λ i \lambda_i λi度量了似然函数的曲率,因此在图中特征值 λ 1 \lambda_1 λ1小于 λ 2 \lambda_2 λ2(较小的曲率对应着似然函数轮廓线较大的拉伸)
由于 β Φ T Φ \beta \Phi^T\Phi βΦTΦ是一个正定矩阵,因此特征值为正数,比值 λ i λ i + α \frac{\lambda_i}{\lambda_i+\alpha} λi+αλi位于0和1之间,结果 γ \gamma γ的取值范围为 0 ≤ γ ≤ M 0\leq\gamma\leq M 0≤γ≤M.对于 λ i ≫ α \lambda_i\gg \alpha λi≫α的方向,对应的参数 w i w_i wi将会与最大似然值接近,且比值 λ i λ i + α \frac{\lambda_i}{\lambda_i+\alpha} λi+αλi接近1.这样的参数被称为良好确定的,因为它们的值被数据紧紧限制着。相反,对于 λ i ≪ α \lambda_i\ll \alpha λi≪α的⽅向,对应的参数 w i w_i wi将会接近0,⽐值 λ i λ i + α \frac{\lambda_i}{\lambda_i+\alpha} λi+αλi也会接近0。这些⽅向上,似然函数对于参数的值相对不敏感,因此参数被先验概率设置为较⼩的值。 γ \gamma γ因此度量了良好确定的参数的有效总数。
比较 β \beta β和公式 1 β M L = 1 N ∑ n = 1 N { t n − w M L T ϕ ( x n ) } 2 \frac{1}{\beta_{ML}}=\frac{1}{N}\sum_{n=1}^N\left\{t_n-w_{ML}^T\phi(x_n)\right\}^2 βML1=N1∑n=1N{tn−wMLTϕ(xn)}2比较,这两个公式都把方差表示为目标值和模型预测值的差的平方的平均值。区别在于最大似然结果的分母是数据点的数量 N N N,而贝叶斯结果的分母是 N − γ N-\gamma N−γ
考虑线性回归模型的对应的结果
⽬标分布的均值现在由函数 w T ϕ ( x ) \boldsymbol w^T\phi(\boldsymbol x) wTϕ(x)给出,它包含了 M M M个参数。
但是,并不是所有的这些参数都按照数据进⾏了调解。由数据确定的有效参数的数量为 γ \gamma γ,剩余的 M − γ M-\gamma M−γ个参数被先验概率分布设置为较⼩的值。这可以通过⽅差的贝叶斯结果中的因⼦ N − γ N-\gamma N−γ反映出来,因此修正了最⼤似然结果的偏差。
使用正弦数据超参数的有效框架,以及由9个基函数组成的⾼斯基函数模型,因此模型中的参数的总数为 M = 10 M=10 M=10,这⾥包含了偏置。为了说明的简洁性,把β设置成了真实值11.1,然后使⽤证据框架来确定 α \alpha α

可以看到参数 α \alpha α 是如何控制参数{ w i w_i wi}的⼤⼩的。下图给出了独⽴的参数关于有效参数数量 γ \gamma γ的函数图像。 如果我们考虑极限情况 N ≫ M N\gg M N≫M,数据点的数量⼤于参数的数量,那么所有的参数都可以根据数据良好确定。因为$ \Phi^T\Phi 涉 及 到 数 据 点 的 隐 式 求 和 , 因 此 特 征 值 涉及到数据点的隐式求和,因此特征值 涉及到数据点的隐式求和,因此特征值\lambda_i 随 着 数 据 集 规 模 的 增 加 ⽽ 增 ⼤ 。 在 这 种 情 况 下 , 随着数据集规模的增加⽽增⼤。在这种情况下, 随着数据集规模的增加⽽增⼤。在这种情况下,\gamma=M , 并 且 ,并且 ,并且\alpha 和 和 和\beta$的重新估计⽅程变为了
α = M 2 E W ( m N ) \alpha=\frac{M}{2E_W(\boldsymbol m_N)} α=2EW(mN)M
β = N 2 E D ( m N ) \beta=\frac{N}{2E_D(\boldsymbol m_N)} β=2ED(mN)N
不需要计算Hessian矩阵的一系列特征值
3.6固定基函数的局限性
由固定的非线性基函数的线性组合组成的模型对于参数的线性性质的假设产生有用的性质,包括最小平方问题的解析解,容易计算的贝叶斯方法。
对于⼀个合适的基函数的选择,我们可以建⽴输⼊向量到⽬标值之间的任意⾮线性映射。
假设了基函数在观测到任何数据之前就被固定了下来,这是维度灾难的一个表现形式。基函数的数量随着输⼊空间的维度 D D D迅速增 长,通常是指数⽅式的增长.
真实数据集有两个性质,可以帮助缓解这个问题。
第⼀,数据向量{ x n x_n xn}通常位于⼀个⾮线性流形内部。由于输⼊变量之间的相关性,这个流形本⾝的维度⼩于输⼊空间的维度。如果使⽤局 部基函数,那么可以让基函数只分布在输⼊空间中包含数据的区域。这种⽅法被⽤在径向基函数⽹络中,也被⽤在⽀持向量机和相关向量机当中。神经⽹络模型使⽤可调节的基函数,这些基函数有着sigmoid⾮线性的性质。神经⽹络可以通过调节参数,使得在输⼊空间的区域中 基函数会按照数据流形发⽣变化。
第⼆,⽬标变量可能只依赖于数据流形中的少量可能的⽅ 向。利⽤这个性质,神经⽹络可以通过选择输⼊空间中基函数产⽣响应的⽅向。