MobileNetV2论文笔记
原文链接:https://blog.csdn.net/Dlyldxwl/article/details/79101293
论文:Inverted Residuals and Linear Bottlenecks: Mobile Networks for Classification, Detection and Segmentation.
Introduction
本文是谷歌公司的又一新作,目标主要是在提升现有算法的精度的同时也提升速度,以便加速深度网络在移动端的应用。网络的名字是Mobilenet V2,很明显可以看出是对Mobilenet的改进。那么Mobilenet存在一些什么问题呢?相信大多数朋友和我一样,第一次看到Mobilenet的时候就觉得为什么这个网络的“形态”设计的和VGG差不多,都是直筒状。后续大量的实验表明,基于resnet,densenet 等对feature复用的结构是很奏效的。所以Mobilenet V2采用了Shortcut connection的思想,因此个人觉得本文也是对现有的Residual block的一个改进,差不多也就是改进Resnet+mobilenet网络。
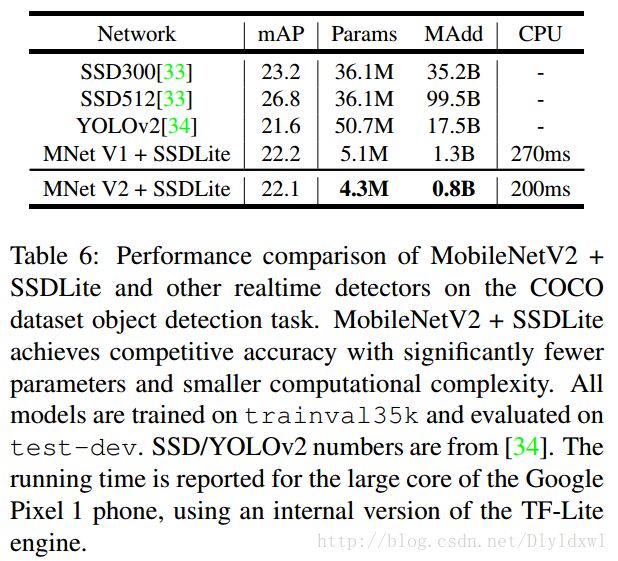
直观感受一下在detection领域mobilenet v2+ssdlite对比其他算法的效果。
Approach
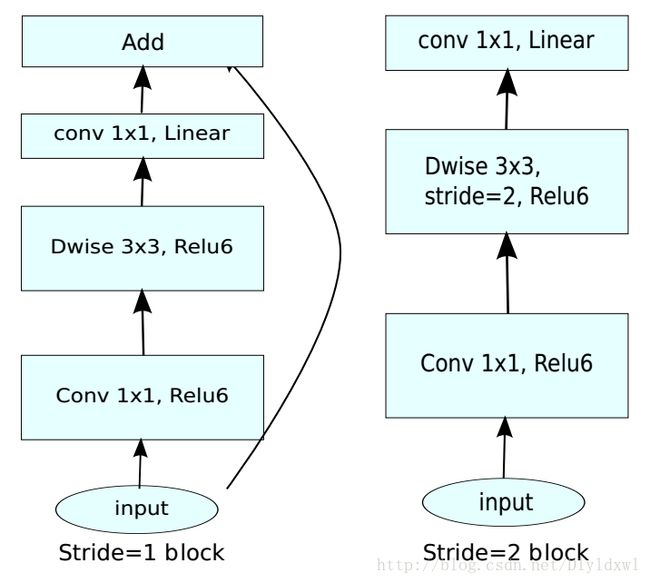
先看一下Mobilenet V2的conv block。如下图所示,以s=1为例说明,矩形框的宽度表示该layer的“宽度”,即channels。和传统的residuals block对比主要有以下两个创新点:一是block里的第二个conv1×1后面并没有接relu,而是用的linear,作者称之为Line Bottlenecks;二是传统的residuals block属于沙漏形状,即input和output很宽,中间接了一个降维的bottleneck layer,但是mobilnet V2更像是一个梭子形状,即input和output较窄,中间是一个升维的layer,因此作者称之为Inverted residuals。下面就这两个创新点展开介绍。
Line Bottlenecks
个人觉得本部分是全文最难懂的一部分,看起来比较玄乎,由于本人水平有限,以下描述均为个人理解,各位看官发现不正确的请告知我。
首先称经过激活层后的张量为感兴趣流形,维度为H×W×D,D为channel,文中称之为宽度。作者说长期以来一直认为神经网络中感兴趣的流形可以嵌入到低维子空间中,什么意思呢?也就是说实际中的感兴趣流形并不是D channel的所有信息,只是一个它的一个低维子空间。这似乎意味着降低空间维度就可以解决问题了。其实在mobilenet里面已经有了这方面的应用(mobilenet有一个宽度乘数和一个分辨率乘数,对mobilenet不清楚的同学可以移步这里)。宽度乘数通过降低激活空间的维度最终希望让感兴趣流形充满整个空间,但是每个深度网络都会有非线性激活函数(例如Relu,负值置0,正值保留),很容易想到,对于感兴趣流形占比大的低维子空间,通过relu层有较高的概率使得较多输出置0,这显然是丢失了一些有用的信息。考虑到如果经过relu后参数非0,那么输出和输入必定是经过了一个线性变换,也就是说此时relu仅仅是一个线性分类器。另一方面,作者在附录中说明了一个道理,如果输入流形可以嵌入到激活空间的一个子空间里(这个子空间可以通过Relu的非零部分),Relu可以保留信息并引入一定的复杂性。
总结起来,就是说明两个事实:一是经过relu后要是感兴趣流形都非零,就意味着其仅仅是经过了一个线性变换;二是要想保持输入流形的完整信息,就必须要让输入流形位于输入空间的低维子空间。
通俗的来说就是,要想提升效果,维度是要降的,但channel数较低时通过relu层会有相对高的概率使较多的输出为0,要想不为0,就要使用relu的线性部分,相当于接了个线性分类器。正如下图第三行所示,channel从tk降为k‘并使用了linear,消除了低维空间中relu对特征的破坏。

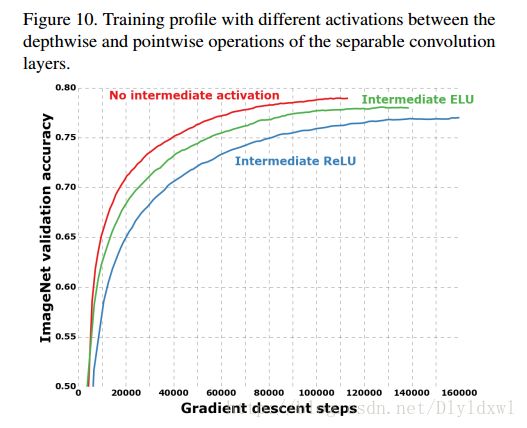
话外篇:其实在xception中,已经提到了dw conv layer后面不接relu是比接relu效果好的,并做了对比实验。如下图所示。
Inverted residuals
顾名思义,倒置的residual,就是bottlenecks layer放在首尾,中间是channel高的layer。如下图所示。其实这两个连接在去掉skip connection后本质上是一样的,只不过观察的起点不一样罢了。但是前面的理论介绍过了,感兴趣流形是在低维的空间里,所以mobilenet V2的连接形式就变成了Inverted residual梭子形。
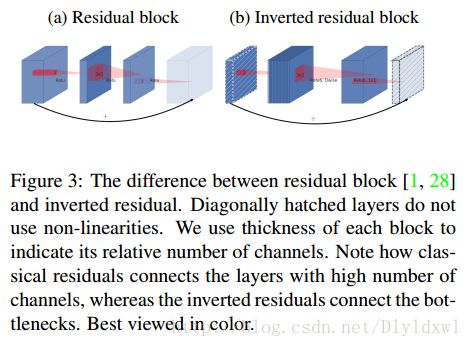
现在两个创新点都已经说明了,总领起来看一下:对于mobilenet V2的每个bottleneck residual block,先进行升维,在接dw layer+relu,最后在降维+linear,并且还做了shortcut connection。升维、降维的作用是什么呢?通俗的解释一下:比如dw conv layer的输入是128个channel,mobilenet就直接用128个filter去卷积,这必然会导致信息流通不好(毕竟这是channel和spatial的完全解耦),但是V2却先把128维升为128×6,然后再进行dw layer,这分明就是冗余的思想嘛!一对一可能效果不好,但是我6对1 ,总有好的吧!接下来,再用1×1的 layer 去降维,这个layer的作用和一般的residual block可不一样了!在传统的residual block中,1×1的作用是用来降低计算量的,此处的作用确是让网络自己去找到起主要作用的channel!这比模型训练完剪枝等操作有用多了!
文中还有一些有关内存优化的细节,抽空再过来写。
突然有种知道但是说不好的感觉。。原理太难说清楚了。。大概也是我理解的不够深刻。。
Experiments
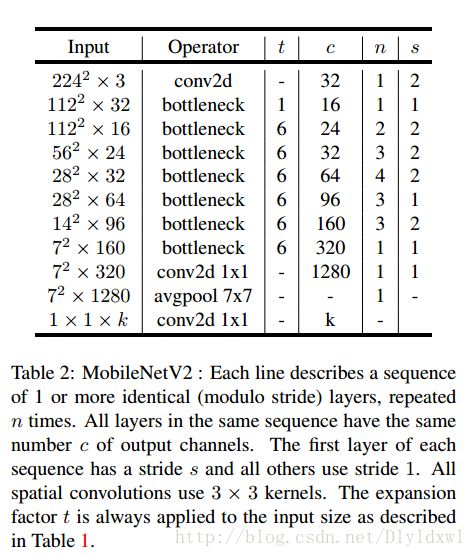
先看一下mobilenet V2的结构。个人觉得图片是有一定问题的,第五行28*28*32经过s=2后size并没有降低,而且文中说明了使用19个bottleneck block,图中却展示了17个bottleneck block,此处还是等源码公开再商榷吧。
作者在classification,detection,segmentation三个领域均做了实验,并和其他网络进行对比,此处以detection为例说明,就不贴那么多实验图了。
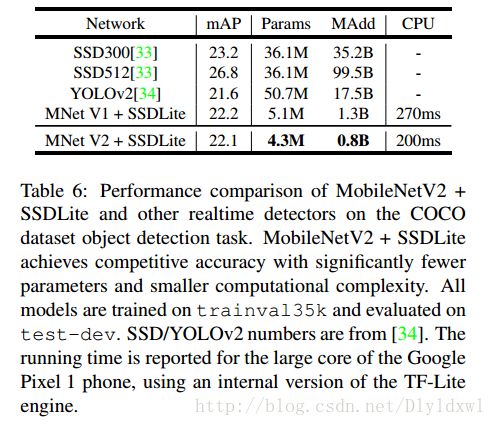
因为mobilenet v2是追求在移动端的应用,所以文中没有和速度较慢的two-stage进行比较。文中提到的SSDLite是改进过的SSD算法,其实就是把SSD的prediction layer也换成了dw+pw结构,参数从14.8M降低到了2.1M。v2和V1与SSDLite的连接大致是相仿的,结果如下图所示。 效果是显而易见的。
Conclusion
大致看完了文章后反过来回想一下,作者是怎么设计出这样的网络的?以下是本人的“意淫”过程,可以选择性忽略。。本人比较喜欢还原作者的思路。。
首先dw conv对参数量的缩减作用是明显,这也导致了其表达能力不强(channel和spital的完全解耦),因为1个feature map和1个filter连接。如果可以把channel shuffle一下,那么效果肯定会提升的,因此shufflenet提出了;1个人处理不好一个问题,我让多个人去干,这样做好的可能性就大大提升了啊。虽然这个比喻不太恰当,但我觉得够说明问题,因此先把channel升到6倍,再进行dw,然后再降维选出“做得好”的那些channell,因此Inverted residuals结构出来了(当然还有skip connection在复用特征和解决梯度问题上起到了重要作用),然后训练过程发现低维空间中relu对特征破坏严重,linear才是王道(其实这个在shufflenet和xceeption里面也提到了),又诞生了“Line Bottlenecks”,因此V2也就出来了。哈哈哈
等有空,画个图直观对比V1,V2, Resnet等网络结构。
本人水平有限,博客中说的不准确的还望指出,共同进步~
关于mobilenet 系列,本人写了一些关于网络设计的见解,移步这里
2018.05.3 补充
试想一下为什么mobilenet 在检测任务上比VGG 差那么多,谷歌出过一篇不同算法和不同backbone在coco数据集上的detect 结果对比。paper中说movilenet ssd略差于vgg ssd。我不是很相信,因为本人自己在caffe下多次训练mobilenet ssd,即使是自己进行过部分feature fuse,在voc07 test上map也不过74。
这是为什么呢?结合自己的工作今天好好想了一下,主要是因为mobilenet 让网络变得稀疏。因为dw结构,一个filter仅和一张feature map卷积,后续接个relu,很容易产生稀疏,造成某个神经元全0. 如果再加上一个宽度乘数,压缩感兴趣流形会造成更多的信息损失,所以效果差。关于稀疏的问题可以参考我做博客的这一篇实验图
那么xception,shufflenet发现了这个问题之后,在DW后面不接relu了,这样就不会丢失信息了,如下图:
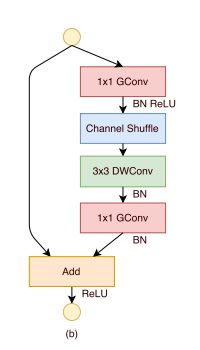
但是在v2中,并不是在DW层后去除relu,而在pw层中去除relu,这又是怎么回事呢?
复看论文发现这是因为v2中dw层是“及其冗余”的,pw“很瘦”,目的就是筛选出低维的感兴趣流形,这意味着只要感兴趣流形信息不丢失就可以了,冗余的dw层接relu就接呗,影响不大,当然个人觉得dw不接也是可以的,不过非线性要弱一些。
此外,mobilenet v2采用1*1conv来进行降维,或说pruning吧,能不能用一种廉价的手段来剪枝呢?比如说在厚的dw层结束后对channel维度进行pooling的操作?这样便大大的加速了网络时间。笔者在此抛砖引玉,能否找到可以替代1*1的廉价升/降维方式呢?