hadoop完全分布式
Hadoop完全分布式
本人刚刚学习hadoop,今天就趁有点时间来写一下博客吧作为抛砖引玉,如有不当敬请指出,大家一起讨论进步。
本人使用三台虚拟机配置完全分布式,配置如下:
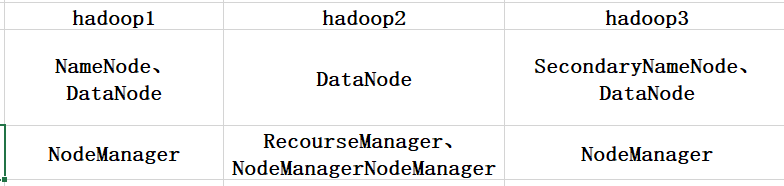
三台虚拟机的IP以我的为例依次为:
hadoop1 192.168.85.11
hadoop2 192.168.85.12
hadoop3 192.168.85.13
一.准备软件
1.vmvare虚拟机(如果是土豪可以上物理机 :))
2.secure CRT 或Xshell
3.hadoop2.7.3
4.jdk
二.虚拟机配置过程
1.安装centos自行百度(本人使用的centos6.8)
1.克隆虚拟机按照如下顺序,必须克隆完整(被克隆的虚拟机必须是关闭的)
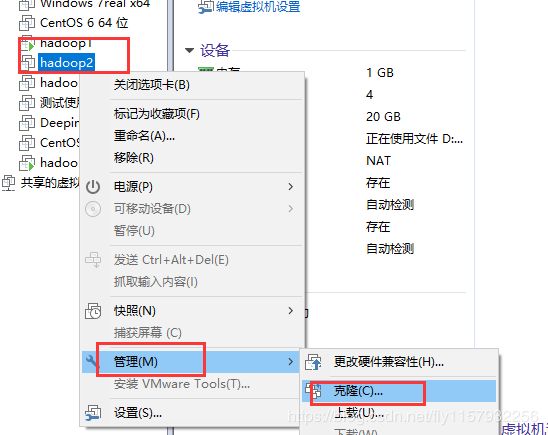




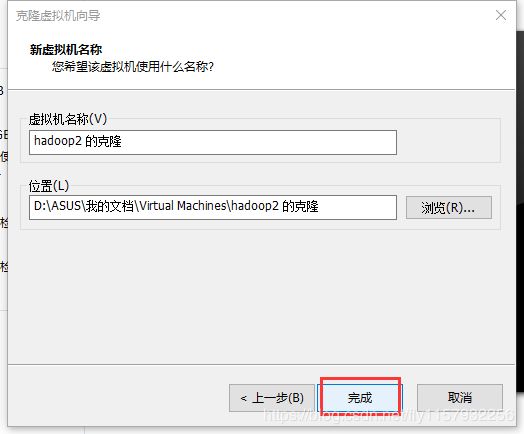
等一段时间克隆成功。需要几台克隆几台(本人使用三台)
2.界面设置(如果是最小化安装略过此步)
1、由于是在虚拟机中搭建环境对于物理机的要求会很高,为了节约不必要的资源消耗,我们把Centos的界面换成命令行的方式。
1.进入图形化界面打开终端,在终端中输入 su 然后输入密码, 进入root用户
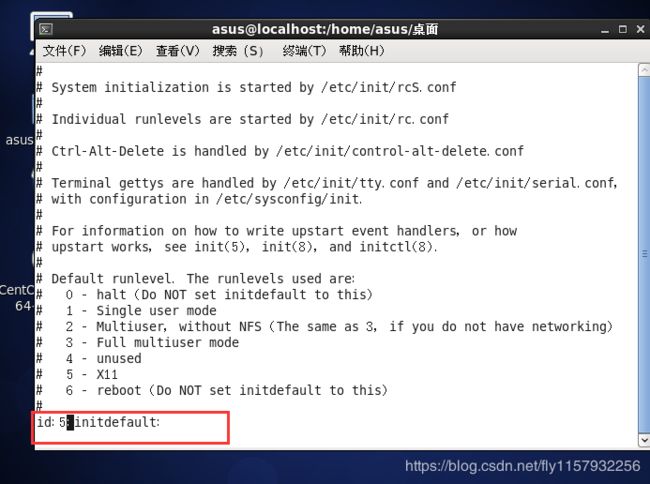
2.输入cd /etc/inittab进入inittab文件编辑界面
3.将光标移动到最后你会看到默认的runlevel 为5 如果要修改成命令行就把id:5 修改为id:3即可然后重启即可
2.配置静态网络修改主机名配置环境
刚克隆好的虚拟机内容都是一样的,所以哈需要为每台虚拟机配置静态ip。
hadoop1 192.168.85.11
hadoop2 192.168.85.12
hadoop3 192.168.85.13
上面是我的三台机器的ip
1.进入命令行界面输入ifconfig 看看你的网络属性。
2.看看你的网卡是哪一个,是enth0 还是enth1
3.可以看到我的是enth1
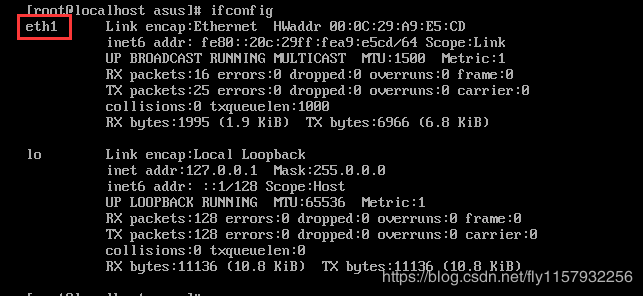
4.修改网卡名称首先执行命令,打开.rules文件如图:
![]()

修改完成重启电脑,之后输入ifconfig eth1变为eth0

5.配置 静态IP执行如图命令
![]()
查看是否有ifcfg-eth0如果没有就复制ifcfg-lo修改里面的内容如图(改成自己的IP不要照搬我的):
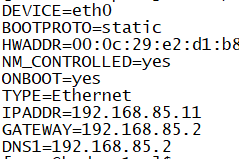
修改主机名修改成对应的主机名
![]()

修改hosts
![]()
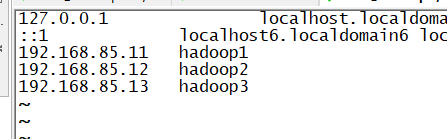
三台机器的配置一样的,这里不一一赘述了。
三、jdk、hadoop安装环境变量配置(以一台电脑为例,配置完一台然后使用集群同步一下就行了)
1.jdk和hadoop安装
把jdk和hadoop安装包上传至虚拟机解压到合适的地方,再上传的过程中可能会遇到权限问题,如果这样的话可以向上传到/home/user(user为你的用户名)然后使用root用户移动过去(我使用root用户在/opt下新建了两个文件夹soft和modules,soft存放压缩包,modules存放解压后的软件包),然后执行命令
tar -zxvf jdk-8u11-linux-x64.tar.gz -C ../modules/ 解压jdk到modules
tar -zxvf hadoop-2.7.3.tar.gz -C ../modules/ 解压jhadoop到modules
修改文件夹所属的用户和组(将/opt/ 下的文件夹以及文件修改为普通用户的asus为我的普通用户)
chown asus:asus -R softs/ modules/
然后在修改、/etc/sudoers 赋予asus更多权利
vi /etc/sudoers
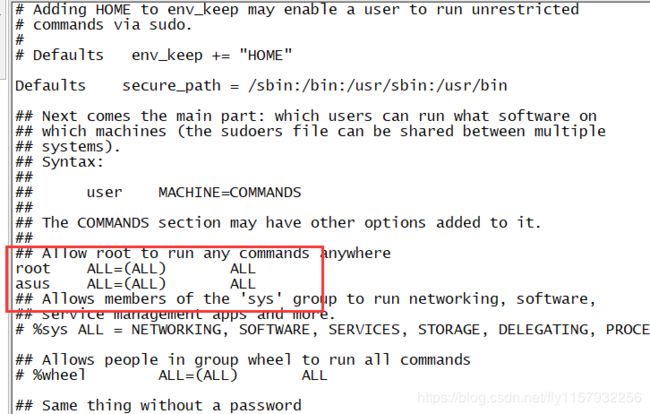

防止出现问题切换为普通用户,然后配置环境变量,切记!切记!
配置环境变量
sudo vi /etc/profile
然后在最后添加如下图
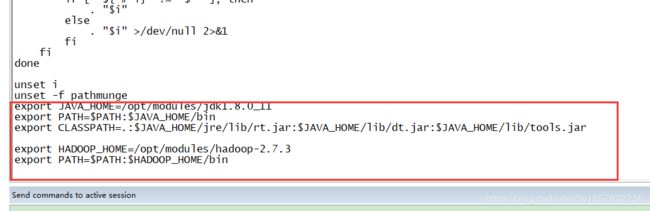
保存如果出现只读执行 shift+:wq!
然后执行source /etc/profile
测试是否配置成功(如下图配置成功)


四、这里是重点(hadoop完全分布式集群配置,首先配置一台之后同步。)
Core-site.xml 配置文件系统的类型和地址,配置运行时临时文件存放目录
Hdfs-site.xml 配置HDFS副本数量
yarn-site.xml 配置nodemanager(服务),rescoursemanager(主机地址),日志聚集(开关,存放时间)
mapred-default.xml 配置MapReduce框架,历史服务器地址和端口,历史服务器网页访问地址和端口
1.core-site.xml
2.hdfs-site.xml
3.hadoop-env.sh

4.yar-site.xml
5.mapred-site.xml (这个刚开始是不存在的,需要复制mapred-site.xml.template 修改为mapred-site.xml)
配置历史服务器时必须先关闭resourcemanager和nodemanager
6.配置slaves 一定要配置slaves(3.0版本这个文件改成了workers )
配置完成,在第一次使用之前必须格式化集群
执行命令如下
hadoop namenode -format
单点启动

yarn单点启动类似执行命令如下(必须在yarn配置的那台服务器 例如我的就是必须在hadoop2上启动,必须在namenode 和datanode启动后才能启动yarn)
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanager
执行命令之后中间不能有任何提示否则就是格式化失败。这样这一台就配置好了,其他两台等一会直接同步即可。
五、配置免密登录
1.免密登录原理
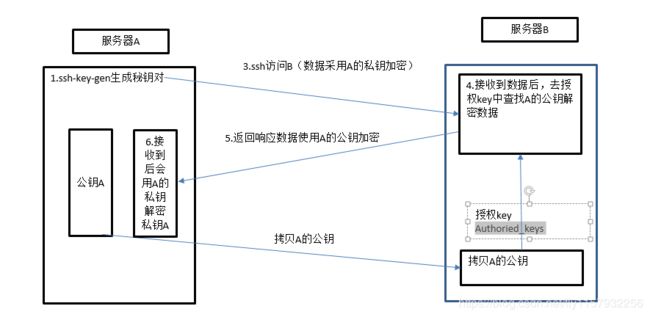
执行
ssh-key-gen -t rsa
然后敲三次回车生成密钥对
将公钥拷贝到三台机器上
ssh-copy-id hadoop1
ssh-copy-id hadoop2
ssh-copy-id hadoop3
为什么本机还要拷贝一遍?
因为每次解密的时候都是从Authoried_keys 查找解密钥匙 所以如果自己没有也是解不了的,所以自己也要给自己拷贝一份。
好了这些都配置好了 我们就可以配置集群分发了
六、集群分发
1.远程拷贝
(1).scp
scp可以实现服务器到服务器之间的数据拷贝
(2).基本语法
scp -r(文件夹) dir/filename [email protected]:/opt/soft
命令 拷贝文件夹 本机文件路径 用户名@主机地址:文件夹
例如(3种形式):
scp -r /opt/modules [email protected]:/opt/modules 这是发送过去
scp -r [email protected]:/opt/modules ./ 这是拉过来
scp -r [email protected]:/opt/modules [email protected]:/opt/modules 第三人帮助
这三种形式用哪一种都行,这只是远程拷贝,这样太慢。

其语法和scp大同小异



1.首先在~目录下建立一个bin文件夹然后进去在建立一个xsync文件 过程如下
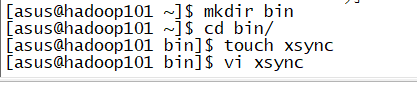
然后把脚本全部复制到xsync里面
#!/bin/bash
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
p1=$1
fname=`basename $p1`
echo fname=$fname
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
user=`whoami`
for((host=1; host<4; host++)); do
echo ----------------------- hadoop$host -----------------------
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
done
保存
调用脚本形式 例如你想同步/opt/modules
执行命令
xsync /opt/modules
这样就可以同步到你所需要的机器上了,脚本中写的是hadoop1 -hadoop3

所以完成第五步之后直接使用脚本分发就可以了例如
同步软件包
xsync /opt/soft
同步安装包和配置文件
xsync /opt/modules
同步环境变量
xsync /ect/profiles
这样脚本里所写的服务器都配置了相同的参数
七.集群启动
如果集群第一次启动需要格式化
执行
hadoop namenode -format
群起
sbin/start-all.sh
然后使用jps查看
ok到此结束 测试的话还用wordcount 前一个博客有提到