数据分析基础笔记
1、概述
近来开始做kangle的项目,从Titanic开始,一个星期,不断试验,将很多之前学习过的东西都用起来了。这里统一汇总一下,记录下数据分析常用的一些函数、方法等。这些东西属于数据分析的范畴,是特征工程的基础。
下面以Titanic、Iris等数据尽量给出示例。
2、Pandas做数据分析的常用函数
(1)DataFrame.describe
能够对number类数据进行统计,能够对数据有一个大概的认识
include=[np.object]能够对非number类数据进行统计
还可以设置exclude=[np.number]
(2)DataFrame.info
能够对DataFrame的没以列进行统计,是否NaN
(3)pd.contact([a,b,c...], axis=)
将若干个DataFrame连接起来
(4)DataFrame.loc
用loc可以对数据进行切片,赋值等
dataset.loc[dataset['Fare'] <= 7.91, 'Fare'] = 0 dataset.loc[(dataset['Fare'] > 7.91) & (dataset['Fare'] <= 14.454), 'Fare'] = 1 dataset.loc[(dataset['Fare'] > 14.454) & (dataset['Fare'] <= 31), 'Fare'] = 2 dataset.loc[dataset['Fare'] > 31, 'Fare'] = 3
(5)Series.astype()
对某一列数据的数据类型进行转换,比如int转换为float
dataset['Fare'] = dataset['Fare'].astype(int)
(6)head
返回前若干行数据
(7)tail
返回后若干行数据
(8)cut、qcut
cut将数据范围等分,然后返回每个数据落在的区间
参数不一样,返回也不一样
一种是不指定label的,返回对应数据所在的范围:

如果指定label,也就是每个区间的编号,则会返回编号

qcut
(9)drop
丢弃某些行、列数据,注意需要指定axis,返回的是丢弃后的新数据

(10)groupby
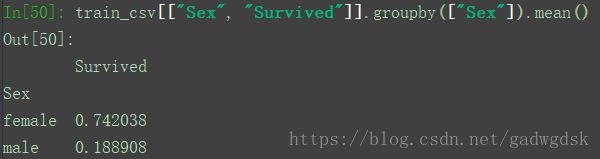
groupby是个强大的工具,能够将数据分组,这对数据分析非常有帮助。比如分析Sex与Survived的关系,按Sex分组来统计Survived:

上图显示female有314人,而male有577个

sum为求和,将Survived求和就是标记为1的求和,也就是female和male分别存活的人数
还可以算比例
还可以画出来:
rain_csv[["Sex", "Survived"]].groupby(["Sex"]).sum().plot.bar()

还可以按照多个参数来分组。比如想分析,Survived与Pclass、Sex的关系:

显然社会等级越高存活率也越高

也可以对group进行排序
train_csv[['Embarked', 'Pclass', 'Sex', 'Survived']].groupby(['Embarked', 'Pclass', 'Sex'], as_index=False).mean().sort_values(by=['Embarked', 'Pclass', 'Sex'], ascending=True)
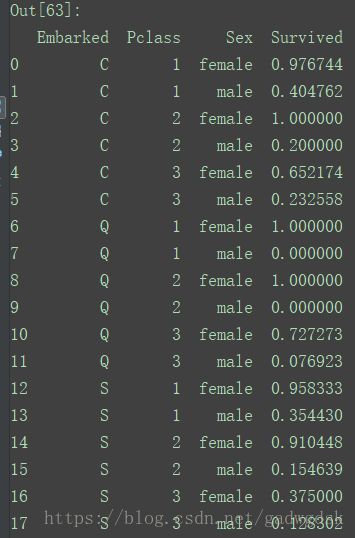
依次按照Embared、Pclass、Sex来排序,ascending=True表示升序,as_index=False表示不用Embared、Pclass、Sex这些列的columns作为index,这样会插入0,1,2,。。作为index,而Embared、Pclass、Sex会作为columns,从而构造成一个DataFrame。
验证一下:train_csv[(train_csv.Embarked=="C") & (train_csv.Pclass==1) & (train_csv.Sex=="female")]["Survived"].mean()
![]()
(11)数据筛选,赋值loc
如果需要对原数据复制,应使用loc
test_csv.loc[test_csv.Age.isnull(),"Age"] = 1
test_csv.loc[:, "Age"] = 2
如果是读取,切片则不需要使用loc
aa = test_csv[(test_csv.Age>1) & (test_csv.Age < 10)]
注意括号不能少
3、因子化、类别编号
因子化:将类别用01序列表示,一行只会有一个1,其余都是0,有1的位置表示是对应类别,因此序列的长度就是类别的数量,若为NaN,则全部是0
类别编号:将列表用自然数编号类别,若为NaN则用-1表示
pandas和sklearn都有因子化和列表编号的函数,pandas能够处理NaN数据,sklearn则需要手工预先填充NaN数据。pandas好像不能储存转换的方式,不能多次以相同的方式转换不同的数据序列,这应该是一个很大的缺陷,而sklearn这点做得很好。此背景下,pandas可能必须将训练和测试集合并然后统一处理,否则可能会导致特征维度都不一样,完全错误。
(1)pd.get_dummies()

(2)pd.Categorical().codes

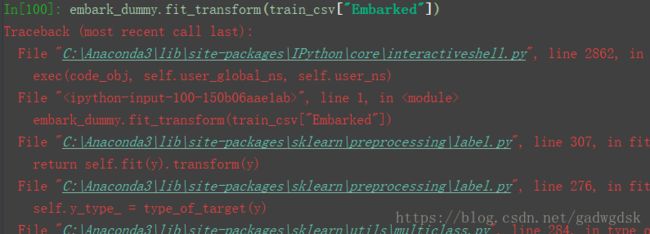
(3)sklearn.preprocessing.LabelBinarizer()

处理不了NaN:
(4)sklearn.preprocessing.LabelEncoder()
对类别进行编号:

age_label.transform(test_csv["Embarked"])
(5)map到字典直接转换
train_csv["sex_map"]= train_csv["Sex"].map({"female":1, "male":2})
不过该方式需要提前知道每一个种类,并手工建立分类。
map的参数也可以是函数
4、sort argsortsort_values sort_index的区别
为了测试,首先:

sort会将Age和Survived分别排序,因为np的sort把它当做Array来处理了,输出也是Array的二维数组
np.sort(a, aixs=0)
若axis=1则是另外一种形式
argsort是排序,然后输出每个元素的下标
sort_values功能则比较强大,可以对DataFrame多个columns进行排序