Hadoop2.7.4 MapReduce开发部署步骤
一、 目标
基于Hadoop2.X 开发及部署MapReduce任务
l 案例需求
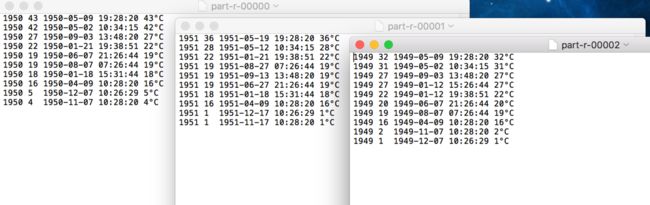
计算在1949年-1951年,每年温度最高的前3天
l 思路:
1.按年份升序排序,同时每一年中温度按降序排序
2.按年分组,每一年对应一个reduce任务
l 技术实现:
1.mapreduce四个步骤:split、mapper、shuffle、reduce,其中shuffle分组、排序
2.设计mapper输出,将年份和温度封装为一个key,hadoop按key排序
3.自定义策略开发
自定义key,KeyPair
自定义排序,SortDegree
自定义分区,YearPartition
自定义分组,YearGroup
l 测试数据
| 1949-05-02 10:34:15 31°C 1950-05-09 19:28:20 43°C 1951-04-09 10:28:20 16°C 1951-05-12 10:34:15 28°C 1950-06-07 21:26:44 19°C 1950-08-07 07:26:44 19°C 1951-05-19 19:28:20 36°C 1951-11-17 10:28:20 1°C 1951-12-17 10:26:29 1°C 1949-05-09 19:28:20 32°C 1949-06-07 21:26:44 20°C 1949-08-07 07:26:44 19°C 1949-09-03 13:48:20 27°C 1949-11-07 10:28:20 2°C 1949-12-07 10:26:29 1°C 1950-01-18 15:31:44 18°C 1950-01-21 19:38:51 22°C 1950-04-09 10:28:20 16°C 1949-01-12 15:26:44 27°C 1949-01-12 19:38:51 22°C 1951-06-27 21:26:44 19°C 1951-08-27 07:26:44 19°C 1951-09-13 13:48:20 19°C 1949-04-09 10:28:20 16°C 1950-05-02 10:34:15 42°C 1950-09-03 13:48:20 27°C 1950-11-07 10:28:20 4°C 1950-12-07 10:26:29 5°C 1951-01-18 15:31:44 18°C 1951-01-21 19:38:51 22°C |
二、 新建工程
1. eclipse中新建Java project
2. 导包common、hdfs、mapreduce、yarn

3. 编写自定义key
| package org.hippo.mr; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.io.WritableComparable; /** * 自定义MapReduce的key,使用年和温度作为key */ public class KeyPair implements WritableComparable private int year; private int degree; public int getYear() { return year; } public void setYear(int year) { this.year = year; } public int getDegree() { return degree; } public void setDegree(int degree) { this.degree = degree; } //反序列化过程,将数据读取为对象 @Override public void readFields(DataInput in) throws IOException { this.year = in.readInt(); this.degree = in.readInt(); } //序列化过程,将对象写出为数据 @Override public void write(DataOutput out) throws IOException { out.writeInt(year); out.writeInt(degree); } @Override public int compareTo(KeyPair o) { int result = Integer.compare(year, o.getYear()); if (result != 0) { return result; } return Integer.compare(degree, o.getDegree()); } @Override public String toString() { return year + " " + degree; } @Override public int hashCode() { return new Integer(year + degree).hashCode(); } } |
4. 编写自定义排序
| package org.hippo.mr; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.io.WritableComparator; /** * 自定义排序 * 按年升序,按温度降序 */ public class SortDegree extends WritableComparator { public SortDegree() { super(KeyPair.class, true); } //按年份升序排序,同时每一年中温度按降序排序 @SuppressWarnings("rawtypes") @Override public int compare(WritableComparable a, WritableComparable b) { KeyPair o1 = (KeyPair) a; KeyPair o2 = (KeyPair) b; //compare默认升序排序,按年升序 int result = Integer.compare(o1.getYear(), o2.getYear()); if (result != 0) { return result; } //按月降序 return -Integer.compare(o1.getDegree(), o2.getDegree()); } } |
5. 编写自定义分区
| package org.hippo.mr; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Partitioner; /** * 自定义分区 */ public class YearPartition extends Partitioner @Override public int getPartition(KeyPair key, Text text, int num) { //按年份分区,乘以127为了使数据分散 return (key.getYear() * 127) % num; } } |
6. 编写自定义分组
| package org.hippo.mr; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.io.WritableComparator; /** * 按年份分组 * @author GavinGuo * */ public class YearGroup extends WritableComparator { public YearGroup() { super(KeyPair.class, true); } //按年份升序排序 @SuppressWarnings("rawtypes") @Override public int compare(WritableComparable a, WritableComparable b) { KeyPair o1 = (KeyPair) a; KeyPair o2 = (KeyPair) b; return Integer.compare(o1.getYear(), o2.getYear()); } } |
7. 编写测试主程序
| package org.hippo.mr;
import java.io.IOException; import java.text.ParseException; import java.text.SimpleDateFormat; import java.util.Calendar; import java.util.Date;
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/** * 执行的主任务 */ public class MainJob {
public static SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
/** * job的入口方法 * @param args */ public static void main(String[] args) {
Configuration conf = new Configuration(); try { Job job = Job.getInstance(conf, "MR-YearDegree");
//设置主执行类 job.setJarByClass(MainJob.class); //设置Mapper类 job.setMapperClass(DegreeMapper.class); //设置Reducer类 job.setReducerClass(DegreeReducer.class); //设置输出的key类 job.setMapOutputKeyClass(KeyPair.class); //设置输出的value类 job.setMapOutputValueClass(Text.class);
//设置reduce任务的个数,每个年份对应一个reduce job.setNumReduceTasks(3); //设置分区类 job.setPartitionerClass(YearPartition.class); //设置排序类 job.setSortComparatorClass(SortDegree.class); //设置分组类 job.setGroupingComparatorClass(YearGroup.class);
//设置输入和输出路径 FileInputFormat.addInputPath(job, new Path("/usr/mr/input/")); FileOutputFormat.setOutputPath(job, new Path("/usr/mr/output/"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
} catch (IOException | ClassNotFoundException | InterruptedException e) { e.printStackTrace(); } }
/** * MapReduce任务的核心类-Mapper(必须) * * LongWritable 读取文件所处的下标(参数不变) * Text 文件内容(参数不变) * KeyPair 输出key为自定义key * Text 数据结果内容 */ static class DegreeMapper extends Mapper @Override protected void map(LongWritable key, Text inText, Context context) throws IOException, InterruptedException { //读取数据文件 String line = inText.toString();
String[] lineEntrys = line.split(" "); if (lineEntrys.length == 3) { try { //根据数据格式准备key的各部分数据 Date date = format.parse(lineEntrys[0] + " " + lineEntrys[1]); Calendar cal = Calendar.getInstance(); cal.setTime(date); int year = cal.get(1); String degree = lineEntrys[2].split("°C")[0];
//设置Map的key KeyPair kp = new KeyPair(); kp.setYear(year); kp.setDegree(Integer.parseInt(degree));
context.write(kp, inText);
} catch (ParseException e) { e.printStackTrace(); } }
} }
/** * MapReduce任务的核心类-Reducer(必须) * * KeyPair mapper的输出key * Text mapper的输出内容 * KeyPair reducer的输出key * Text reducer的输出内容 */ static class DegreeReducer extends Reducer @Override protected void reduce(KeyPair key, Iterable throws IOException, InterruptedException {
//数据在shuffle阶段已经排好序了,在这里直接循环输出合并即可 for (Text v : value) { context.write(key, v); } } } } |
8. 打包
三、 部署测试
1. 上传测试文件(不要建输出文件夹)
| ssh node0 hdfs dfs -rm -r /usr/mr/output hdfs dfs -mkdir -p /usr/mr/input hdfs dfs -put /share/mapreduce-test/data /usr/mr/input exit |
2. 执行job
| hadoop jar /share/mapreduce-test/mr.jar org.hippo.mr.MainJob |
3. 查看执行结果
| [root@gyrr-centos-node-0 /]# hadoop jar /share/mapreduce-test/mr.jar org.hippo.mr.MainJob 17/09/08 11:54:38 INFO client.RMProxy: Connecting to ResourceManager at node0/192.168.2.200:8032 17/09/08 11:54:50 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 17/09/08 11:54:54 INFO input.FileInputFormat: Total input paths to process : 1 17/09/08 11:54:55 INFO mapreduce.JobSubmitter: number of splits:1 17/09/08 11:54:55 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1504841269293_0001 17/09/08 11:54:56 INFO impl.YarnClientImpl: Submitted application application_1504841269293_0001 17/09/08 11:54:56 INFO mapreduce.Job: The url to track the job: http://node0:8088/proxy/application_1504841269293_0001/ 17/09/08 11:54:56 INFO mapreduce.Job: Running job: job_1504841269293_0001 17/09/08 11:55:40 INFO mapreduce.Job: Job job_1504841269293_0001 running in uber mode : false 17/09/08 11:55:40 INFO mapreduce.Job: map 0% reduce 0% 17/09/08 11:56:04 INFO mapreduce.Job: map 100% reduce 0% 17/09/08 11:56:25 INFO mapreduce.Job: map 100% reduce 33% 17/09/08 11:56:39 INFO mapreduce.Job: map 100% reduce 67% 17/09/08 11:56:43 INFO mapreduce.Job: map 100% reduce 100% 17/09/08 11:56:54 INFO mapreduce.Job: Job job_1504841269293_0001 completed successfully 17/09/08 11:56:55 INFO mapreduce.Job: Counters: 50 File System Counters FILE: Number of bytes read=1092 FILE: Number of bytes written=493415 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=875 HDFS: Number of bytes written=1008 HDFS: Number of read operations=12 HDFS: Number of large read operations=0 HDFS: Number of write operations=6 Job Counters Killed reduce tasks=1 Launched map tasks=1 Launched reduce tasks=4 Data-local map tasks=1 Total time spent by all maps in occupied slots (ms)=20562 Total time spent by all reduces in occupied slots (ms)=92760 Total time spent by all map tasks (ms)=20562 Total time spent by all reduce tasks (ms)=92760 Total vcore-milliseconds taken by all map tasks=20562 Total vcore-milliseconds taken by all reduce tasks=92760 Total megabyte-milliseconds taken by all map tasks=21055488 Total megabyte-milliseconds taken by all reduce tasks=94986240 Map-Reduce Framework Map input records=30 Map output records=30 Map output bytes=1014 Map output materialized bytes=1092 Input split bytes=102 Combine input records=0 Combine output records=0 Reduce input groups=3 Reduce shuffle bytes=1092 Reduce input records=30 Reduce output records=30 Spilled Records=60 Shuffled Maps =3 Failed Shuffles=0 Merged Map outputs=3 GC time elapsed (ms)=503 CPU time spent (ms)=6790 Physical memory (bytes) snapshot=601763840 Virtual memory (bytes) snapshot=8421953536 Total committed heap usage (bytes)=348389376 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=773 File Output Format Counters Bytes Written=1008 |
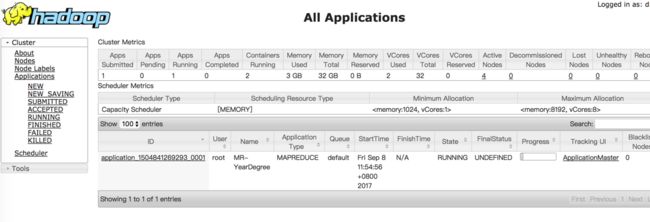
执行中的任务
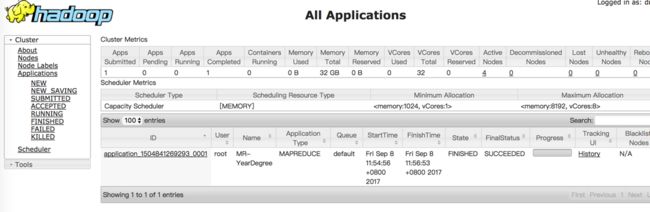
执行成功
查看HDFS结果

结果文件