基于HBase的工业大数据存储实战
随着工业4.0时代的到来,工业互联网和企业的智能化、信息化都将不断推进,传统的工业实时数据库和关系数据库已经难以完全胜任工业大数据的存储,以HBase为代表的NoSQL数据库正在蓬勃发展,其完全分布式特征、高性能、多副本和灵活的动态扩展等特点,使得HBase在工业大数据的存储上拥有强大的优势,打破了流程工业生产中的"数据壁垒"效应的瓶颈,可以促进工业生产水平和生产管理水平的提高。本期格物汇,就来给大家介绍HBase数据库及格创东智相关实战案例。
了解HBase
HBase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。HBASE的目标是存储并处理大型的数据,更具体来说是仅需使用普通的硬件配置,就能够处理由成千上万的行和列所组成的大型数据。
HBASE是GoogleBigtable的开源实现,但是也有很多不同之处。比如:Google Bigtable使用GFS作为其文件存储系统,HBASE利用HadoopHDFS作为其文件存储系统;Google运行MAPREDUCE来处理Bigtable中的海量数据,HBASE同样利用Hadoop MapReduce来处理HBASE中的海量数据;Google Bigtable利用Chubby作为协同服务,HBASE利用Zookeeper作为协同服务。
与传统数据库的相比,HBASE具备多重优势:
1)线性扩展,随着数据量增多可以通过节点扩展进行支撑;
2)数据存储在hdfs上,备份机制健全;
3)通过zookeeper协调查找数据,访问速度快。
HBase实战案例
为了更好的介绍 HBase 在人工智能场景下的使用,下面我们以某半导体显示企业为案例,给大家分析格创东智大数据团队如何利用 HBase 设计出一个快速查找面板特征的系统。
目前,该公司的业务场景里面有很多面板相关的特征数据,每张面板数据大概 3.2k。这些面板数据又被分成很多组,每个面板特征属于某个组。组和面板的数据分布如下:
——43%左右的组含有1张面板数据;
——47%左右的组含有 2 ~9张面板数据;
——其余的组面板数范围为 10 ~ 10000张。
现在的业务需求主要有以下两类:
——根据组的 id 查找该组下面的所有面板数据;
——根据组 id +面板id 查找某个面板的具体数据。
原有方案:MySQL+OSS
之前业务数据量比较小的情况使用的存储主要为 MySQL 以及 OSS(对象存储)。相关表主要有面板组表group和面板表face。表的格式如下:
group表:
| group_id | size |
|---|---|
| 1 | 2 |
glass表:
| glass_id | group_id | feature |
|---|---|---|
| “TB7B3695BA05” | 1 | “CASBA” |
其中 feature(特征)大小为3.2k,是二进制数据 base64 后存入的,这个就是真实的面板特征数据。现在面板组 id 和面板id 对应关系存储在MySQL 中,对应上面的 group 表;面板 id 和面板相关的特征数据存储在 OSS 里面,对应上面的 face 表。
因为每个面板组包含的玻璃特征数相差很大(1 ~ 10000),所以基于上面的表设计,我们需要将面板组以及每张面板特征id存储在每一行,那么属于同一个面板组的数据在MySQL 里面上实际上存储了很多行。比如某个组id对应的特征数为10000,那么需要在MySQL 里面存储 10000 行。
我们如果需要根据面板组 id 查找该组下面的所有面板,那么需要从 MySQL 中读取很多行的数据,从中获取到组和面板对应的关系,然后到 OSS 里面根据面板id获取所有相关的特征数据。
这样的查询导致链路非常长。从上面的设计可看出,如果查询的组包含的面板张数比较多的情况下,那么我们需要从 MySQL 里面扫描很多行,然后再从 OSS 里面拿到这些特征数据,整个查询时间在10秒左右,远远不能满足现有业务快速发展的需求。
HBase解决方案:
MySQL + OSS的设计方案有两个问题:第一,原本属于同一条数据的内容由于数据本身大小的原因无法存储到一行里面,导致后续查下需要访问两个存储系统;第二,由于MySQL不支持动态列的特性,所以属于同一个面板组的数据被拆成多行存储。
针对这两个问题,格创东智的大数据团队进行了分析,认为这是 HBase 的典型场景,原因如下:
——HBase 拥有动态列的特性,支持万亿行,百万列;
——HBase 支持多版本,所有的修改都会记录在 HBase 中;
——HBase 2.0 引入了MOB(Medium-Sized Object)特性,支持小文件存储。
HBase 的 MOB 特性针对文件大小在 1k~10MB 范围的,比如图片,短视频,文档等,具有低延迟,读写强一致,检索能力强,水平易扩展等关键能力。
格创东智的大数据团队使用这三个功能重新设计上面 MySQL + OSS 方案。结合应用场景的两大查询需求,将面板组 id 作为 HBase 的 Rowkey,在创建表的时候打开 MOB 功能,如下:
create ‘glass’, {NAME => ‘c’, IS_MOB => true, MOB_THRESHOLD => 2048}
上面我们创建了名为 glass 的表,IS_MOB 属性说明列簇 c 将启用 MOB 特性,MOB_THRESHOLD 是 MOB 文件大小的阈值,单位是字节,这里的设置说明文件大于 2k 的列都当做小文件存储。大家可能注意到上面原始方案中采用了 OSS 对象存储,那我们为什么不直接使用 OSS 存储面板特征数据呢,如果有这个疑问,可以看看下面表的性能测试:
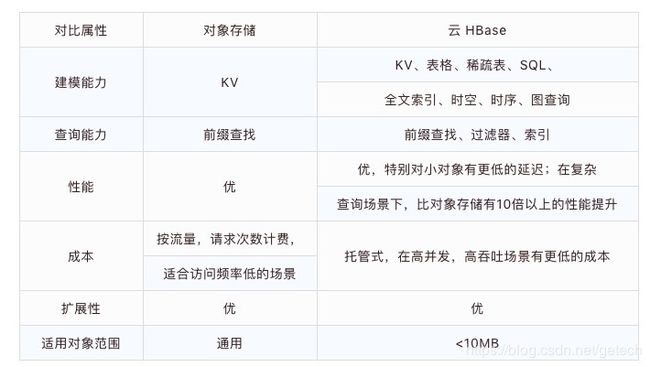
String CF_DEFAULT = “c”;根据上面的对比,使用 HBase MOB特性来存储小于10MB的对象相比直接使用对象存储有一些优势。
我们现在来看看具体的表设计,使用面板id作为列名。我们只使用了HBase 的一张表就替换了之前方面的三张表!虽然我们启用了 MOB,但是具体插入的方法和正常使用一样,代码片段如下:
Put put = new Put(groupId.getBytes());
put.addColumn(CF_DEFAULT.getBytes(),glassId1.getBytes(), feature1.getBytes());
put.addColumn(CF_DEFAULT.getBytes(),glassId2.getBytes(), feature2.getBytes());
……
put.addColumn(CF_DEFAULT.getBytes(),glassIdn.getBytes(), featuren.getBytes());
table.put(put);
用户如果需要根据面板组id获取所有面板数据,可以使用下面方法:
Get get = new Get(groupId.getBytes());
Result re=table.get(get);
这样我们可以拿到某个组id对应的所有面板数据。如果需要根据组id+面板id查找某个面板的具体数据,看可以使用下面方法:
Get get = new Get(groupId.getBytes());
get.addColumn(CF_DEFAULT.getBytes(), glassId1.getBytes())
Result re=table.get(get);
经过上面的改造,在2台 HBaseWorker 节点内存为32GB,核数为8,每个节点挂载四块大小为 250GB 的 SSD 磁盘,并写入100W 行,每行有1W列,读取一行的时间在100ms-500毫秒左右。在每行有1000个face的情况下,读取一行的时间基本在20-50毫秒左右,相比之前的10秒提升200~500倍。
从下面这张对比表,我们可以清楚的看到HBase方案的巨大优势。
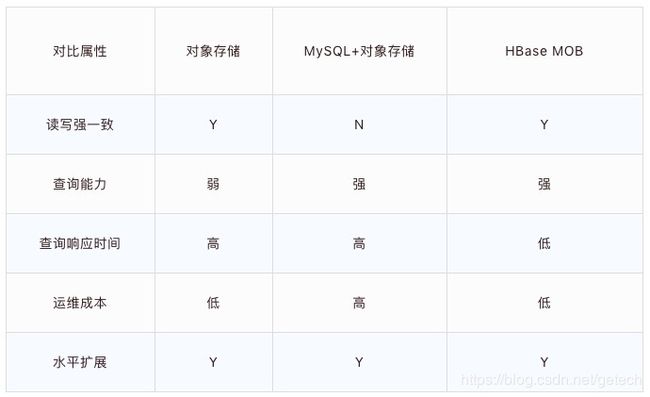
现在,我们已经将面板特征数据存储在Cloudera HBase 之中,这个只是数据应用的第一步,如何将隐藏在这些数据背后的价值发挥出来?这就得借助于数据分析,在这个场景就需要采用机器学习的方法进行操作。我们可以借助大数据分析工具Spark 对存储于 HBase 之中的数据进行分析,而且 Spark 本身支持机器学习的。最后,用户就可以通过访问 HBase 里面已经挖掘好的特征数据进行其他的应用了。
本文作者:格创东智王子超(转载请注明作者及来源)