基于Pandas和PyEcharts的当当网图书信息可视化分析
1 绘制python图书封面的照片墙
import math
import os
from PIL import Image
def makePicturesWall(picdir):
picslist = os.listdir(picdir)
num_pics = len(picslist)
size = 64
line_numpics = int(math.sqrt(num_pics))
picwall = Image.new('RGBA', (line_numpics * size, line_numpics * size))
x = 0
y = 0
for pic in picslist:
img = Image.open(os.path.join(picdir, pic))
img = img.resize((size, size), Image.ANTIALIAS)
picwall.paste(img, (x * size, y * size))
x += 1
if x == line_numpics:
x = 0
y += 1
print('[INFO]: Generate pictures wall successfully......')
picwall.save('picwall.png')
if __name__ == '__main__':
imgDir = '/home/kiosk/PycharmProjects/Spider/mySpider/img/full'
makePicturesWall(imgDir)
- 照片墙效果显示如下:
2 图书的价格分布南丁格尔图
import pandas as pd
from pyecharts import Pie
def load_data(filename):
"""
:param filename: 加载数据的文件名
:return:
prices: 书籍的价格
null_price_count: 空数据的个数
"""
# 1). 读取csv文件;
df = pd.read_csv(filename)
# 2). 删除缺失值;
# axis=0:----表示轴向。默认为0,表示删除所有含有空值的行
# how='any'----表示删除的方式。默认为any。为any的时候,表示只要存在缺失值就删除。
# 为all的时候,表示全部是缺失值才能删除。
all_count = df.shape[0]
prices = df.price.dropna(axis=0, how='any')
data_count = prices.shape[0]
null_price_count = all_count - data_count
print("缺失值数量为:", null_price_count)
# 3). 对书籍的价格数据进行预处理, 转换成float类型;
prices = [float(price.strip('¥')) for price in prices]
return prices, null_price_count
def data_cut(prices):
"""
根据书籍价格的区域进行切分, 返回切分后的统计数据;
:param prices:
:return:
"""
# 设置切分区域
priceBins = [0, 50, 100, 150, 200, 10000]
# 设置切分后对应标签
priceLabels = ['50元以下', '50-100', '100-150', '150-200', '200以上']
# 利用pd.cut进行数据离散化切分
# pd.cut(price, bins=5, right=True, labels=None, retbins=False, precision=3, include_lowest=False)
cut_prices = pd.cut(prices, bins=priceBins, labels=priceLabels, include_lowest=True).value_counts()
return cut_prices
def show_picture(cut_prices):
pie = Pie("python书籍价格分布")
pie.add("", cut_prices.keys(), cut_prices.values(),
# center为调整饼图圆心坐标
center=[50, 50],
# is_random是否随即排列颜色列表(bool)
is_random=False,
# radius为半径,第一个为内半径,第二个是外半径
radius=[30, 75],
# rosetype为是否展示成南丁格尔图
# 'radius' 圆心角展现数据半分比,半径展现数据大小
# 'area' 圆心角相同,为通过半径展现数据大小
rosetype='area',
is_legend_show=False,
# is_label_show为是否显示标签(各个属性的数据信息)
is_label_show=True,
# label_text_size为调整标签字体大小
label_text_size=18
)
pie.render()
if __name__ == '__main__':
filename = 'items.csv'
prices, null_price_count = load_data(filename)
cut_prices = dict(data_cut(prices))
cut_prices['缺失值'] = null_price_count
show_picture(cut_prices)
- 效果显示如下:

3 评论数量TOP10的图书条形图
import pandas as pd
def load_data(filename):
"""
加载并处理数据, 返回根据评论数排序好的数据变量df;
:param filename: 文件名
:return:
"""
df = pd.read_csv(filename)
# 根据评论数量进行排序;
sorted_df = df.sort_values(by='comment_num')
return sorted_df
def show_picture(df):
"""
绘制条形图
:param df: 根据评论排序好的数据
:return:
"""
# 1). 获取评论量排前10的书籍名称和评论数量;
commentTop10 = df.tail(10)[['title', 'comment_num']][::-1]
# 2). 绘制条形图
from pyecharts import Bar
bar = Bar("Python相关图书评论数量分布TOP10", title_text_size=24)
bar.add("",
# x轴
commentTop10.title,
# y轴
commentTop10.comment_num,
# 显示label信息
is_label_show=True,
# bar_category_gap调整的是柱形间距
bar_category_gap='70%',
# 标记虚线: 此处标出最大值最小值的虚线。
mark_line=["min", "max"],
# 标记点: 此处标出平均值的地方。
mark_point=["average"],
# 横、纵坐标值偏转的角度,当坐标值过于密集时,可采用此方法。
xaxis_rotate=30,
yaxis_rotate=30,
# 绘图为竖向条形图的设置;
# is_convert=True
)
bar.render()
if __name__ == '__main__':
filename = 'items.csv'
sorted_df = load_data(filename)
show_picture(sorted_df)
- 条形图效果展示:
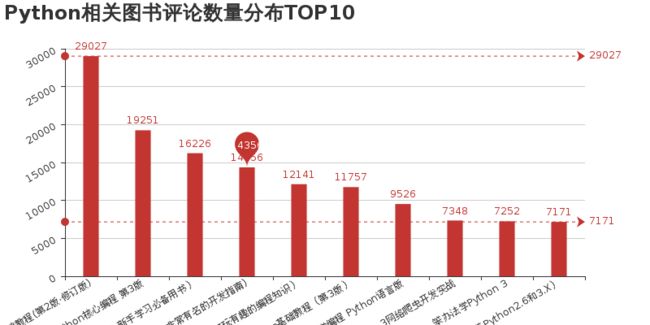
注意: 此处的图书名称太长, 显示不好看, 可以对标题进一步处理,只提取书名的前6个字符即可.
3 书籍简介词云可视化分析
import re
from collections import Counter
import pandas as pd
import jieba
from pyecharts import WordCloud
def load_data(filename):
"""
加载与预处理数据
:param filename:
:return:
"""
# 1). 读取当当网数据信息;
df = pd.read_csv(filename)
before_drop_count = df.shape[0]
# 2). 删除书籍简介的缺失值
descs = df.introduction.dropna()
after_drop_count = descs.shape[0]
null_num = before_drop_count - after_drop_count
print('缺失值数量', null_num)
# 3). 拼接所有的书籍简介为一个字符串并清洗数据(删除所有的空格并将大写字母全部转换为小写字母;)
all_descs = "".join(descs)
# 将所有的空格和非字母数字下划线的字符串替换为空;
all_descs = re.sub(r'[\s\W]', '', all_descs).lower()
# 4). 中文分词切割与统计;
cut_descs = list(jieba.cut(descs))
counter_descs = Counter(cut_descs)
counter_descs = {key: value for key, value in counter_descs.items() if len(key) != 1}
return counter_descs
def show_picture(counter_descs):
"""
:param counter_descs: 切割并统计好的书籍简介数据(类似字典格式)
:return:
"""
wordcloud = WordCloud("python书籍评论词云统计", width=1300, height=1000)
wordcloud.add("",
# word数据,词云图中显示的词语;
counter_descs.keys(),
# 词语权重,相当于词频;
counter_descs.values(),
# 生成的词云图轮廓, 有'circle', 'cardioid', 'diamond', 'triangle-forward', 'triangle', 'pentagon', 'star'可选
shape='star',
# 单词间隔,默认为20
word_gap=50,
# 单词字体大小范围,默认为[12,60]
word_size_range=None,
# 旋转单词角度,默认为45; 仅当 shape 为默认的'circle'时 rotate_step 参数才生效
# rotate_step=60
)
wordcloud.render()
if __name__ == '__main__':
filename = 'items.csv'
descs = load_data(filename)
show_picture(descs)
- 效果展示如下:
