Cascade network——multi-stage refinement
文章目录
- List
- Preview
- AttractioNet(2016)
- CRAFT:CRAFT Objects from Images(2016)
- CC-Net:chained cascade network for object detection(ICCV2017)
- IoUNet(2018)
- Cascade R-CNN
- Hybrid Task Cascade for Instance Segmentation(cvpr 2019)
List
- Cascade R-CNN
- Combine Cascade R-CNN and Mask R-CNN——Cascade Mask R-CNN
- Hybrid Task Cascade for Instance Segmentation
Preview
目前,目前实例分割可以分成两个大类:(1)基于检测;(2)基于分割
- 基于检测:产生bounding box或者是region proposal,并利用这些bounding box来预测mask,如DeepMask, SharpMask, Instance-FCN,近段时间,就有继承了Instance-FCN的FCIS,以及Mask R-CNN,PANet, MaskLab。
- 基于分割:首先是获取像素级分割map,再去识别具体的个体目标。这方面工作目前还有许多跟传统方法相结合的地方,似乎没有基于检测的流行。
现在对于目标检测,有比较主流的分法是one-stage和two-stage,但是现在有一个分支就是multi-stage for finetune,这里之所以说是fintune,是因为这里multi-stage说的是级联的结构,一般是在头部进行几次级联结构,而且是为了对上一步的检测结果进行更加精炼的修正。
Multi-stage Object Detection
目标检测最开始应该是2016年开始的,摘抄自论文Hybrid Task Cascade for Instance segmentation],但实际上级联进行迭代修正的做法很早就出现,早在2010年的关于人脸的一些算法就有出现,应该还有更早的:
- AttractioNet:引入了一个
Attend&refine module来对bounding box的定位进行迭代的更新 - CRAFT:将级联的结构整合进RPN和head里
- CC-Net:chained cascade network for object detection:略
- IoUNet:没有很明确的表达了级联结构,但是对bounding box refine做得很好
- Cascade R-CNN :略
AttractioNet(2016)
网络的核心组件是基于CNN的category-agnostic目标位置修正模块,用来产生精确稳定的bounding box,还有一点,就是这个方法还可以对unseen categories(应该指的是数据集未指定的类别)进行定位。在当时,在coco2014以及VOC2007达到SOTA。以下是论文中算法的代码部分,由其中的反复迭代进行Attend & Refine来看,已经有了级联的意思了。
需要注意的几点:
- 以下的
ObjectnessScoring是对框与预标定的目标的贴近程度来打分,而非类别信息。(可以对比IoUNet) seed boxes是需要通过算法选出来的,但不是使用滑动窗口,这里有提到选seed boxes的方法类似于Cracking Bing(这里不做重点关注),目的是尽量少的初始框却要将所有区域进行有效的覆盖。

上图似乎有些步骤没表达出来:

CRAFT:CRAFT Objects from Images(2016)
code
这个时候R-CNN系列都已经出来了,论文里有引用。再说一下论文题目的含义:Cascade Region proposal-network And FasT-rcnn,即级联的RPN和fast R-CNN,也就是开始说的在RPN和head部分进行级联操作。数据集是PASCAL VOC 07/12 and ILSVRC
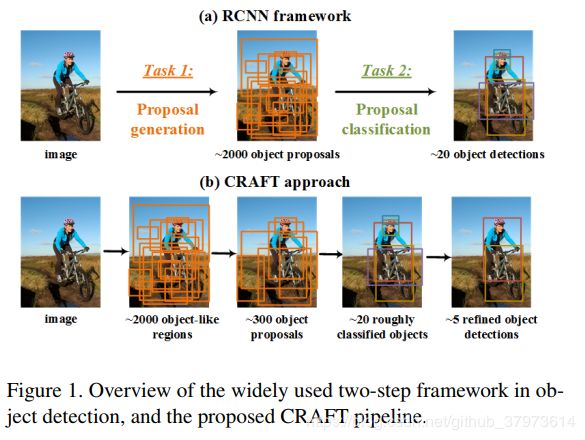
这是论文里给出一个对比图。
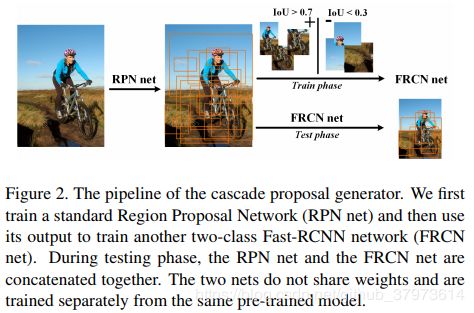
- RPN:论文之所以要在RPN使用级联结构,是因为单独做了RPN处的实验,结论就是如果是有比较极端的
scale, ratio的目标,或者是those usually immersed in object clutters, are also difficult to be distinguished from background, 如植物、电视机、椅子等。训练的时候是连续训练RPN net和二分类FRCN net(Fast R-CNN)(即后面头部那一块)。- 1.使用滑动窗口的方式去训练RPN net,一些参数设置同Faster R-CNN
- 2.RPN训练好后,在训练集上进行测试,每张图产生2000原始proposals
- 3.使用上面产生的proposals去训练二分类FRCN net,使用与RPN相同的正抽样和负抽样标准(正的0.7个IoU以上,负的0.3个IoU以下)。
- 4.测试的时候,同2步骤,不过会经过阈值操作或者抑制,会将proposals控制到300以下。
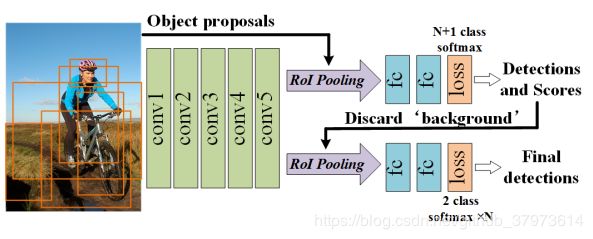
- head:此处基于上面的FRCN的二分类输出训练FRCN-2,FRCN-2与FRCN相同的部分权重共享(最后预测的分支则无法共享)
在做对比实验的时候主要与fast R-CNN和faster R-CNN(主干皆为VGG16)在Pascal VOC数据集上进行对比。
文章只是大致的介绍一下,本身也是多Stage的方法,其中代码非end-to-end进行训练,可以参考faster R-CNN论文中提到的多阶段训练方式,这里非重点关注。其实在此处,个人认为级联的一些需要思考的地方:什么结构去级联以及怎么控制级联带来的运算代价。
CC-Net:chained cascade network for object detection(ICCV2017)
多个stage来去除easy background sample。针对分类来做的cascade。
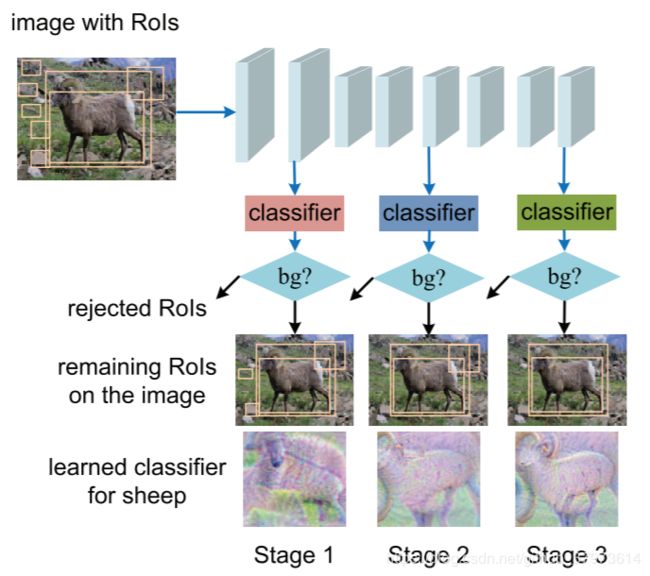
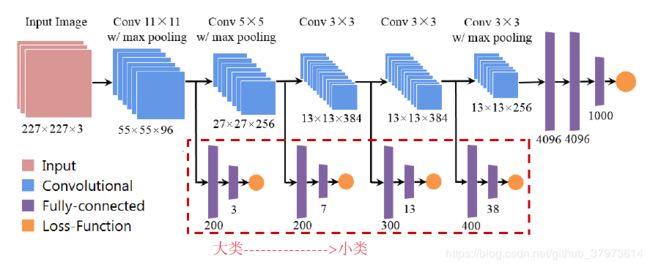
类似
来自论文Do Convolutional Neural Networks Learn Class Hierarchy
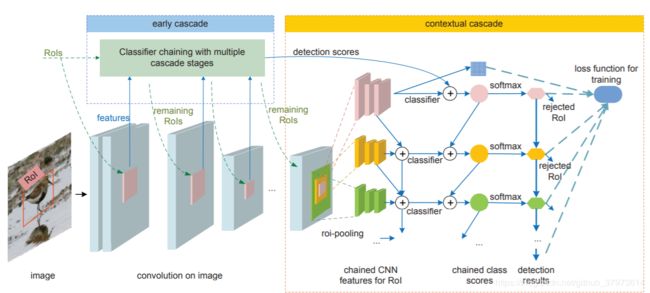
ROI的产生还是使用selective research或者是上面的craft里的方法。
- earlly cascade: rejecting RoIs belonging to background by multiple cascade stages
- contextual cascade:If a RoI is not rejected by the cascade, its final classification score is used as the detection score
IoUNet(2018)
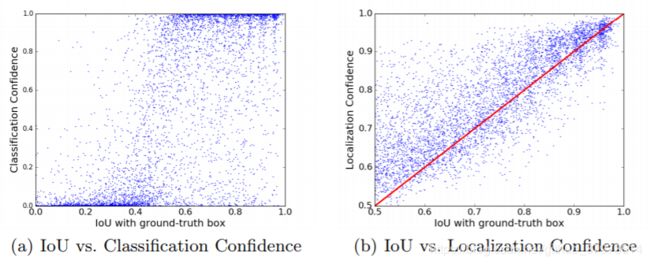
在NMS阶段,通常会使用cls_score来对box进行质量评估,但实际上cls_score与box质量并无很直接的关系。在我们看来,bbox与gt之间的IoU可以在一定程度上做到:IoU越高,定位质量越好。
- IoUNet的做法就是在NMS阶段将衡量bbox定位质量的cls_score替换为IoU score。下图就很直接的说明了这一点,后者比前者在bbox质量和选取指标之间的联系会强很多。
- 基于IoU score,本文提出了基于优化的bbox refine方案,该方案将预测的IoU score作为优化目标。
- 将IoUNet作为组件与FPN、Cascade RCNN,Mask RCNN集成时,都带来了提升。
方案:
- IoU-guided NMS,将cls score 改为pred IoU score:操作还是一样,但是就是在NMS过程中将评价指标变成了pred IoU score,而且当某个bbox1通过IoU score将另一个bbox2淘汰时候,bbox1的cls score需要替换成 m a x ( c l s _ s c o r e b b o x 1 , c l s _ s c o r e b b o x 2 ) max(cls\_score_{bbox1}, cls\_score_{bbox2}) max(cls_scorebbox1,cls_scorebbox2)
- prRoI pooling :离散的值都通过双线性插值来计算
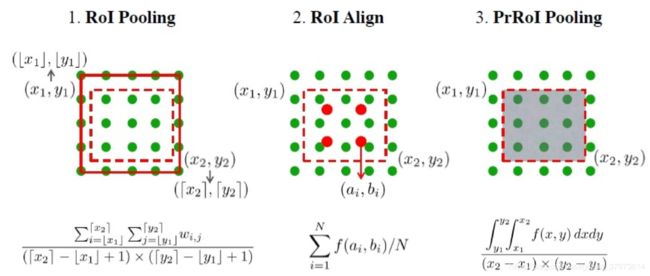
- 基于优化的bbox refine方案;
以下是bbox修正过程:将IoU score作为最终的优化目标,基于IoU score来计算梯度并迭代优化bbox坐标。

IoUNet,会根据一定的策略独立的训练一个IoU predictor,这个是为了生成鲁棒的bbox的IoU score用于IoU-guided NMS。因为其本身的训练是独立于检测算法部分的,所以可以与RoI-based的检测算法兼容。最后有在inference阶段迭代5次,性能却没有下降。
【训练IoU predictor的策略:对训练集图像中的所有gt bbox,通过随机参数手动地调整这些gt bbox(manually transform them with a set of randomized parameters),生成candidate bbox集合,再从candidate bbox集合中剔除与gt bbox的IoU小于Ω_train = 0.5的低质量bbox,最后从剩余的candidate bbox集合中随机采样以生成训练集数据(如fig 5中Jittered RoIs)【摘】】
Cascade R-CNN
目标是提高检测质量,希望能获得更精确的检测结果,是一个很泛化的改进,对R-CNN结构的基本可以带来2-4个点的AP提升。
由以下实验结果图来引入论文讨论的问题:其中的u表示为训练阶段在proposal进入头部时进行positive和negative的IoU阈值。通常我们取的是u=0.5。
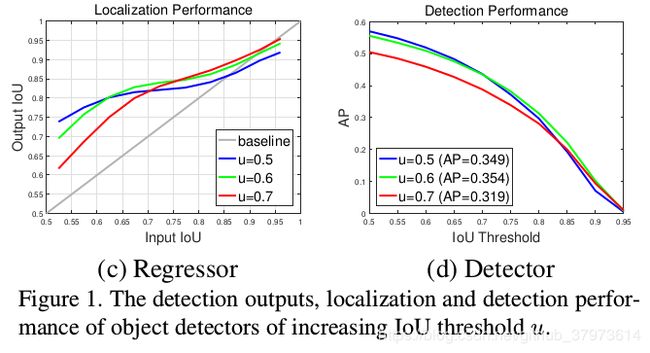
- figure1.c,u表示取的是不同的IoU阈值,横轴表示RPN的输出proposal的IoU,纵轴则表示proposal在经过box reg的新的IoU。可以看出来0.525-0.6范围内是u=0.5检测效果最好(detector对box的定位修正),0.6-0.75范围是u=0.6检测效果好,0.75之后的范围则是u=0.7的效果最好。根据实验结果得到一个结论:只有proposal自身的阈值和detector训练用的阈值比较接近时,detector的效果是最好的。
- figure1.d,AP曲线,横轴表示inference阶段的阈值取值,即AP50, AP55…,纵轴则表示是mAP,可以看出跟figure1.c结论一样。
Cascade Architecture:
b,c是其他人的multi-stage结构
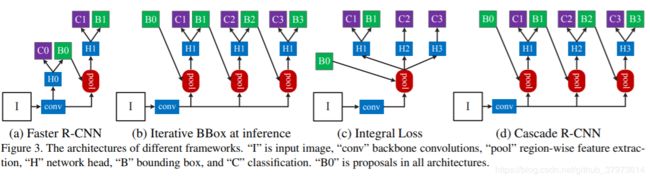
Cascade R-CNN启发于 cascade pose regression(CPR) 2010 and face alignment,其中CPR就是对人脸的特征点的进行标记定位,CPR 通过一系列回归器将一个指定的初始预测值逐步细化,每一个回归器都依靠前一个回归器的输出来执行简单的图像操作【摘】。
以下是cascade和b,c结构的对比:
- 和iterative BBox at inferennce比较
- iterative bbox取的是单一阈值0.5,在figure1的时候就分析了这样的效果不行
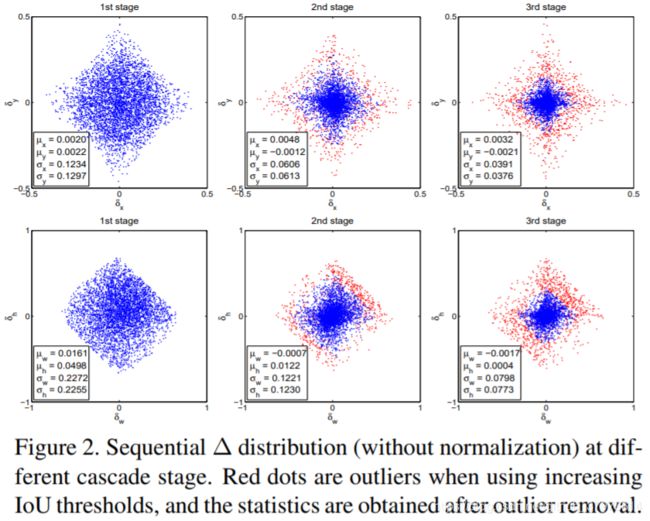
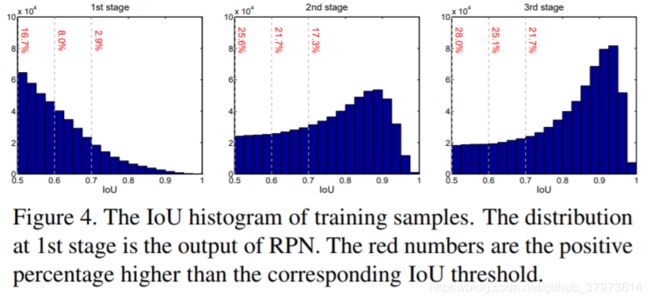
- 其次是detector会改变样本的分布,但其头部共享,对不同分布的数据处理起来不是很好。如下图:每一次回归后,样本都会更靠近gt,即质量更高,图中红色的点表示是outlier,在后续的处理中,如果不通过提高阈值来将其去掉,那么会引入大量的噪声。整个过程就体现了迭代的resample过程。
- 这里iterative BBox则使用同一个阈值,应该只是想单纯的对定位进行迭代修正,而修正的对象仍然是最初始认为的正样本(>0.5)。而Cascade R-CNN通过实验得到修正后样本分布改变的结果,恰好也与最开始分析的不同IoU阈值训练出来的detector所针对的输入有不同的擅长范围对应上了,那么改变阈值是一个很好的方案。并且,对于outlier,个人理解是,是属于refine后仍然烂泥扶不上墙的box,那就在后一次resample时就是抛弃。
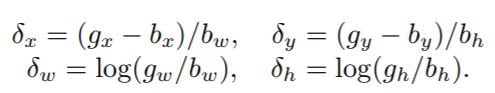
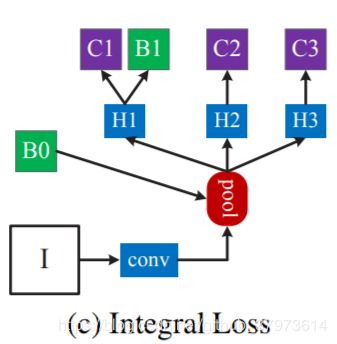
- 和Integral Loss比较
这个其实可以看出来没有级联结构。从roipooling那里接出三个不共享的分支,每个H处都对应了不同的IoU阈值。利用不同的阈值来进行分类,之后融合他们的分类结果来进行分类推理。从上面Cascade R-CNN实验分析这样的操作存在很多问题——数据分布问题。
The computational cost of a detection head is usually small when compared to the RPN, the computational overhead of the Cascade R-CNN is small, at both training and testing
Hybrid Task Cascade for Instance Segmentation(cvpr 2019)
实例分割这个问题近几年的发展很大程度上是由coco数据集以及比赛推动,而且现在也出现很多细粒度分割的问题。
在分割的问题上引入级联,就如前面说过的,需要考虑的是级联的结构设计,以及代价问题。文中也有探究,直接将Mask R-CNN和Cascade R-CNN结合起来,获得的提升很有限。
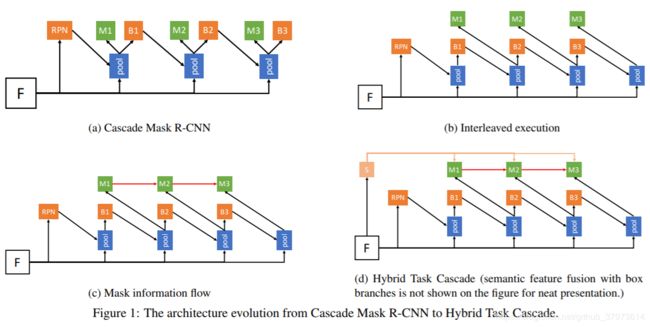
- (a) box AP提升3.5个点,但是mask提升有限,只有1.2个点的提升。
- (b) 每一个stage里的box和mask分支没有交互,这里增加了交互。其实就是将原来的同区域并行出box和mask,改成先修正box(区域)再mask。这样的做法直接用到mask R-CNN会对box和mask都带来0.5左右的AP提升。不过再Cascade Mask R-CNN提升效果倒是基本没有。

- (c) 增加了一条mask之间的关联设计。
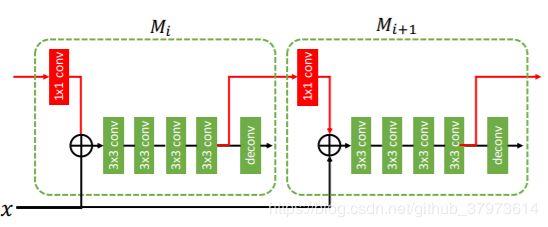

摘