论文阅读笔记之——《Deep Multi-scale Convolutional Neural Network for Dynamic Scene Deblurring》
论文:https://arxiv.org/pdf/1612.02177.pdf
代码:https://github.com/SeungjunNah/DeepDeblur_release
代码解读https://blog.csdn.net/wm6274/article/details/71194225
数据集下载链接在上面的github里面
we propose a multi-scale convolutional neural network that restores sharp images in an end-to-end manner where blur is caused by various sources.(网络结构)
we present multi-scale loss function that mimics(模拟) conventional coarse-to-fine approaches.(loss改进)
propose a new large-scale dataset that provides pairs of realistic blurry image and the corresponding ground truth sharp image that are obtained by a high-speed camera(数据集)
Thus, some approaches tried to parametrize blur models with simple assumptions on the sources of blurs.(传统的方法中,通过估算blur kernel或者类似之前做过的,估算blur level map(SRMD操作)可是经过实验后,个人觉得这种方式不靠谱)However, these blur kernel approximations are still inaccurate, especially in the cases of abrupt motion discontinuities and occlusions. Note that such erroneous (错误的) kernel estimation directly affects the quality of the latent image, resulting in undesired ringing artifacts.
Unlike other approaches, our method does not estimate explicit blur kernels. Accordingly, our method is free from artifacts that arise from kernel estimation errors.(不去估计level map就可以减少artifacts的引入)
Since no pairs of real blurry image and ground truth sharp image are available for supervised learning, they commonly used blurry images generated by convolving synthetic blur kernels.Thus, CNN-based models are still suited only to some specific types of blurs, and there are restrictions on more common spatially varying blurs.(这里就阐述了CNN method实际上是对特定退化模型的拟合,泛化能力差)
These are mainly due to the use of simple and unrealistic blur kernel models. Thus, to solve those problems, in this work, we propose a novel end-to-end deep learning approach for dynamic scene deblurring.
1、we propose a multi-scale CNN that directly restores latent (潜伏的) images without assuming any restricted blur kernel model.Especially, the multi-scale architecture is designed to mimic (模拟) conventional coarse-to-fine optimization methods.
2、we train the proposed model with a multi-scale loss that is appropriate for coarse-to-fine architecture that enhances convergence greatly. In addition, we further improve the results by employing adversarial loss
3、new realistic blurry image dataset
好下面来看看这篇论文的method部分
首先作者改进了residual block(这样的一个改进好像跟超分的EDSR还是RRDB一模一样?所以不能叫改进?)
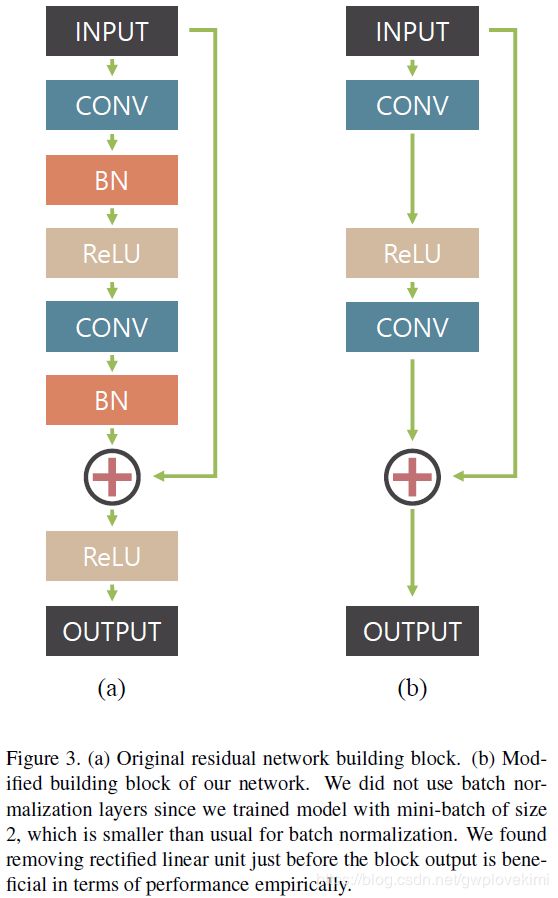

网络结构如下图所示
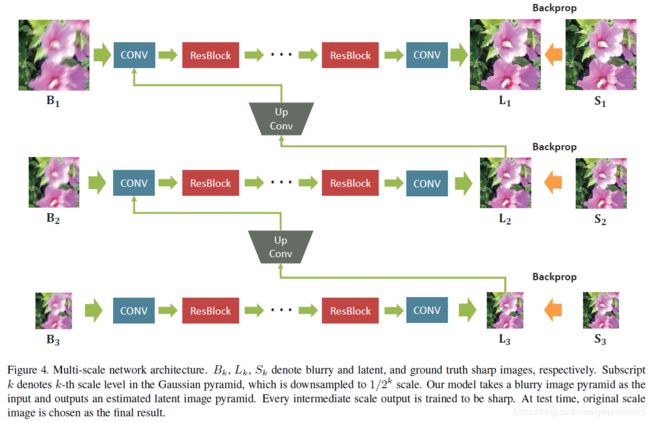
Coarsest level network(最粗层网络)
The first convolution layer transforms 1/4 resolution, 64 × 64 size image into 64 feature maps. Then, 19 ResBlocks are stacked followed by last convolution layer that transforms the featuremap into input dimension.
At the end of the stage, the coarsest level latent sharp image is generated. Moreover, information from the coarsest level output is delivered to the next stage where finer scale network is.
Since the sharp and blurry patches share low-frequency information, learning suitable feature with upconvolution helps to remove redundancy. the upconvolution feature is concatenated with the finer scale blurry patch as an input.
Finer level network
Finer level networks basically have the same structure as in the coarsest level network. However, the first convolution layer takes the sharp feature from the previous stage as well as its own blurry input image, in a concatenated form.
虽然论文的结果视觉效果没有《 论文阅读笔记之——《Deep Stacked Hierarchical Multi-patch Network for Image Deblurring》》这篇博客里面的好,但是显然后者的multi-scale是直接用了前者的