《Two-Stream Convolutional Networks for Action Recognition in Videos》论文笔记
这篇论文是2015年发表在NIPS上的一篇文章,利用双流卷积神经网为视频中的行为识别提供类一种新的思路。
下面是个人做的总结和部分翻译。
论文贡献
- 提出了一个结合时间和空间网络的双流卷及网络构架。
- 证明了利用多帧密集的光流场的卷及网络即使在数据较少时也能表现优异的性能。
- 展示了应用于两个不同的行为分类的数据集的多任务学习能够用来增加训练数据量并且能够提高在两个数据集上的性能。
介绍
- 李飞飞提出通过堆叠视频帧作为网络的输入,结果比几种代表性效果最好的人工提取特征的方法还要差。
- 该论文研究了一种基于两个独立的识别流(时间域和空间域)的不同的网络结构,最后将其融合起来
- 空间流基于静态视频帧执行行为识别
- 时间流基于动作的稠密光流来进行识别
相关工作
基于局部时空特征的浅层高维编码
检测稀疏的时空兴趣点,然后使用局部时空特征描述:定向梯度直方图(HOG)[7]和光流直方图(HOF)。 这些特征然后被编码成袋状特征(BoF)表示,其被汇集在多个时空网格(类似于空间金字塔池)并且与SVM分类器组合。 (后续工作证明稠密兴趣点效果更好)
其他的写的有点杂,没有细看。
用于视频识别的双流体系构架
视频自然可以分解为空间和时间分量。 空间部分以单个框架外观的形式携带有关视频中描绘的场景和对象的信息。 时间部分以帧的运动形式传达观察者(相机)和物体的运动。作者根据视频的特性,设计了一个双流卷积网络构架,每个流都使用深度ConvNet实现,softmax评分通过后期融合进行组合。 我们考虑两种融合方法:平均和训练多级线性支持向量机[6],将堆积的L2归一化的softmax分数作为特征。
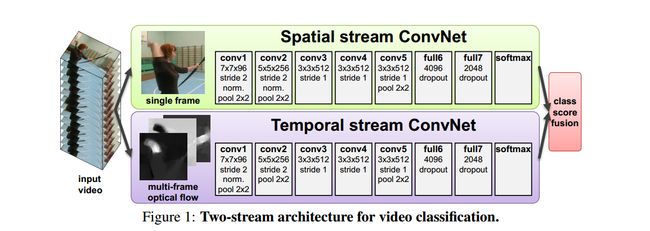
空间流卷积网络在单个视频帧上运行,有效地从静止图像执行动作识别。 静态外观本身是一个有用的线索,因为某些动作与特定对象强烈关联。 事实上,正如将在第四节中所显示的那样。 如图6所示,来自静止帧(空间识别流)的动作分类本身具有相当的竞争力。 由于空间ConvNet本质上是一种图像分类体系结构,因此我们可以基于大规模图像识别方法的最新进展[15],并在大型图像分类数据集(如ImageNet挑战数据集)上对网络进行预训练。 详细信息请参见Sect。 接下来,我们描述时间流卷及网络,它利用运动并显着提高准确性。
光流卷积网络
光流卷积网络的输入是通过在几个连续帧之间堆叠光流位移场而形成的。光流特征使识别更加简单,因为不用隐式评估动作。

(a)(b)是连续视频帧,并且用青色矩形画出了手的部分。(c)画出了区域里面的稠密光流(d)位移矢量的水平分量,(强度较高的表示的为正值,强度较低的表示为负值)(e)表示的是垂直分量
卷积网络的输入配置
光流堆叠
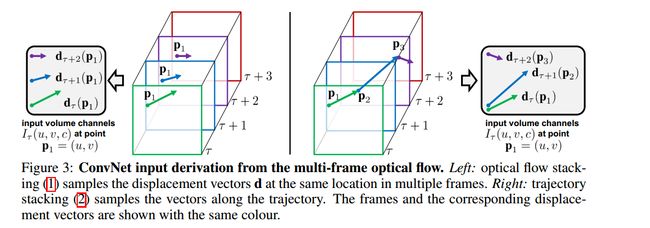
密集的光流可以看作是一组位移矢量场 dx d x 在连续帧t和t+1之间, dt(u,v) d t ( u , v ) 表示在t帧的矢量点(u,v),然后将点移到t+1帧的对应位置。为了在一系列帧数上表示运动,我们将L个连续帧的流动通道 dtx,y d t x , y 叠加起来,总共形成2L个通道。令w和h为视频的宽度和高度,对于任意帧t的卷积网络的输入量 It∈Rw∗h∗2L I t ∈ R w ∗ h ∗ 2 L 构造如下:

对于任意点(u,v),信道 It(u,v,c) I t ( u , v , c ) ; c = [1; 2L]通过一系列的L帧对该运动进行编码(如图3左侧所示)。
轨迹堆叠(Trajectory stacking)
由基于轨迹的描述符[29]启发的另一种运动表示法,将沿相同位置在多个帧上采样的光流替换为沿着运动轨迹采样的流。 在这种情况下,对应于帧t的输入量 It I t 采用以下形式:
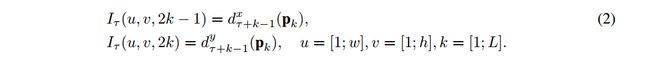
其中, pk p k 是沿着轨迹的第k个点,其起始于帧τ中的位置(u,v)并且由以下递归关系定义:
![]()
与输入体积表示(1)相比,输入体积(2)在通道 It(u,v,c) I t ( u , v , c ) 处将位移矢量存储在位置(u,v)处,轨迹(如图3右图所示)。
双向光流(Bi-directional optical flow)
光流表示(1)和(2)处理前向光流,即第t帧的位移场 dt d t 指定其像素的位置在下面帧t + 1。考虑扩展到双向光流是很自然的,这可以是通过在相反方向上计算另外一组位移场而获得。 然后,我们通过在帧τ与τ+ L /22之间堆叠L /2个正向流并且在帧τ-L /2与τ之间堆叠L/2个反向流来构建输入体积 It I t 。 输入 It I t 因此具有与之前相同的信道数量(2L)。这两种方法都可以用来表示流量。
平均流量减法(Mean flow subtraction)
执行网络的零中心输入通常是有益的,因为它允许模型更好地利用整流非线性。在我们的例子中,位移矢量场分量既可以取正值也可以取负值,并且自然是居中的,因为在各种各样的运动中,一个方向上的运动与另一个运动中的运动可能相反。 然而,给定一对框架,它们之间的光流可以由特定的位移来控制,例如, 由相机移动引起的。 摄像机运动补偿的重要性先前在[10,26]中被强调过,其中全局运动分量被估计并从密集流中减去。 在我们的例子中,我们考虑一个更简单的方法:从每个位移场d我们减去它的平均向量。
构架(Architecture)
以上我们已经描述了将多个光流位移场组合成单个体积 It∈Rw∗h∗2L I t ∈ R w ∗ h ∗ 2 L 的不同方式。 考虑到卷积网络需要固定尺寸的输入,我们从 It I t 采样一个224×224×2L的子量,并将其作为输入传送给网络。 隐藏层的配置与空间网络中的配置基本保持一致,如图1所示。测试与空间卷积网络相似。
多任务学习(Multi-task learning)
由于视频分类数据集的规模很小,所以论文将两个数据集合并成一个数据集进行训练。
具体细节
ConvNets配置:它对应着CNN-M-2048结构,所有的隐含权重层使用ReLu激活函数;max-pooling采用3×3空间大小,步长为2;时域和空域的ConvNet唯一的差别在于我们移除了从最后的第二个归一化层以减少内存需求。
训练:训练步骤由AlexNet调整而来,对于时域和空域是同样的。网络权重通过动量为0.9的批处理随机梯度下降算法学习得到。每一次迭代,小尺寸的256个样本通过256个训练视频(从不同类中均匀抽样)抽样,每一个视频中一个单帧视频被随机获取。
- 在空域训练中,224×224子图像从选择的帧中随机裁剪;然后采用随机的水平翻转和RGB颜色抖动。视频预先调整大小,所以帧的最小尺寸等于256。
- 在时域训练中,我们计算一个光流输入流I,固定尺寸224×224×2L的输入随机裁剪和翻转。学习速率初始化设置为10−2,之后根据固定的步骤下降,所有训练集保持相同。
测试:给定一个视频,抽样得到固定数目(本实验25)的帧,对于每一个视频帧,我们可以通过裁剪、翻转视频帧四个角和中心区域获得10个ConvNets。整个视频的类别得分可以通过平均抽样视频的得分得到。
实验评估
只截了一张和其他方法的对比结果,其实论文还做了其他实验进行对比

结论
我们提出了一个具有竞争性表现的深度视频分类模型,该模型包含基于卷积网络的独立空间和时间识别流。 并且利用光流特征训练时间流比例用原始帧堆叠的效果更好。正如我们已经表明的那样,额外的数据训练对于我们的时间卷积网络是有利的,因此我们计划在大型视频数据集上训练它,例如最近发布的[14]集合。 目前最先进的浅层表示[ 26 ]仍然存在一些重要的成分,这在我们目前的体系结构中是缺失的。最突出的一个是局部特征汇集在时空管,在轨迹中心。即使输入(2)捕获沿着轨迹的光流,我们的网络中的空间汇聚并不考虑轨迹。另一个潜在的改进领域是摄像机运动的明确处理,在我们的例子中,这是通过平均位移相减来补偿的。