基于Tensorflow的Imagenet数据集的完整处理过程(包括物体标识框BBOX的处理)
最近比较忙,好久没更新博客了。
上一篇博客是关于对Imagenet数据集进行预处理的,虽然能给Tensorflow的后续训练提供数据,但是我觉得还是有改进的空间,主要包括了两点:
- 数据集中还提供了很多图片的bounding box,这个bounding box是人工进行的标注,准确的标注了图片中对应类别的物体的具体位置。在之前的数据集预处理中没有包括这一部分。即使我们现在做的模型是做类别判断,不涉及到物体定位,我觉得这个Bouding Box的信息还是很有价值的。因为从数据集的图片可以看到,很多图片里面是包括了多个物体的,如果我们直接把这个图片标识为1个类别,那么误差其实是比较大的,例如在很多和动物相关的图片中都有人像,因此我们在训练时最好能把和这个类别相关的Bounding Box包括的图像抠出来进行训练,这样会更加准确。
- 在之前的处理中,直接把训练集的数据划分为3部分,即训练数据,验证数据和测试数据。但是其实Imagenet 2012竞赛中是单独提供了验证集的数据的(这部分数据有50000张图片,也是对应这1000个类别)。很多对Imagenent进行研究的论文都是以这个验证集的测试结果作为评测指标的。为了保持一致,我们也应该以所有训练集的数据进行训练,而以验证集的50000张图片进行测试。
以下是具体的处理过程。
Imagenet数据集的下载
首先,下载Imagenent train和validation的数据集并进行解压,下载地址为:
http://www.image-net.org/challenges/LSVRC/2012/nnoupb/ILSVRC2012_img_train.tar
http://www.image-net.org/challenges/LSVRC/2012/nnoupb/ILSVRC2012_img_val.tar
下载后的train数据集是一个146G的Tar文件,里面又包括了1000个Tar文件,每个文件对应一个类别的图片。我写了一个Python的小程序来做解压:
import os
filelist = os.popen("tar -tf ILSVRC2012_img_train.tar").readlines()
num = 0
for item in filelist:
tarfile = item.strip()
folder = tarfile[:-4]
os.popen("mkdir data/"+folder+"/")
os.popen("tar xf ILSVRC2012_img_train.tar "+tarfile)
os.popen("tar xf "+tarfile+" -C data/"+folder+"/")
os.popen("rm -f "+tarfile)
num += 1
print "processing %i/1000\r" %num,解压之后包括了1000个文件夹,每个文件夹存放一个类别的图片,每个类别大约都有1300张图片。
下载后的validation数据集解压后有6.7G,包括了50000张图片。
Bounding Box数据的下载与处理
下一步就是下载bounding box的文件,地址是http://www.image-net.org/challenges/LSVRC/2012/nnoupb/ILSVRC2012_bbox_train_v2.tar
下载后的文件解压之后,可以看到每个类别对应一个文件夹,里面存放了各个图片对应的XML文件,文件里面定义了bounding box的具体位置。以下的Python程序对这些XML文件进行处理,把结果写入到一个CSV文件:
import xml.etree.ElementTree as ET
import os
xmlRootDir = 'bbox/'
dirs = os.listdir(xmlRootDir)
files = os.listdir('bbox/'+dirs[0]+'/')
def parseXML(filename):
bbox = [[],[],[],[]]
tree = ET.parse(filename)
root = tree.getroot()
size = root.find('size')
width = float(size.find('width').text)
height = float(size.find('height').text)
for node in root.iter("object"):
bndbox = node.find('bndbox')
xmin = max(float(bndbox.find('xmin').text)/width, 0.0)
ymin = max(float(bndbox.find('ymin').text)/height, 0.0)
xmax = min(float(bndbox.find('xmax').text)/width, 1.0)
ymax = min(float(bndbox.find('ymax').text)/height, 1.0)
bbox[0].append(xmin)
bbox[1].append(ymin)
bbox[2].append(xmax)
bbox[3].append(ymax)
return bbox
bboxfile = open('bbox_train.csv', 'w')
content = ''
i = 0
for folder in dirs:
i+=1
folderpath = xmlRootDir + folder + '/'
files = os.listdir(folderpath)
for xmlfile in files:
bbox = parseXML(folderpath+xmlfile)
content += xmlfile
for j in range(4):
content += ','+';'.join([str(x) for x in bbox[j]])
content += '\n'
print("processing %i/1000\r"%i, end="")
bboxfile.writelines(content)
bboxfile.close()
Imagenet数据集转换为TFRECORD
之后就可以对解压后的数据进行读取和处理,把数据转换为TFRECORD的数据格式。在上一篇博客中已经提到,把多个图片放在一个TFRECORD中可以有效提升后续的训练的效率。对于TFRECORD里面每一条记录的字段,除了需要包括图片的JPEG编码后的数据以及标签之外,还需要包括这个图片对应的Bounding Box的数据,图片的长和宽,和标签的文字描述。具体的代码如下:
#-*- encoding: utf-8 -*-
import tensorflow as tf
import cv2
import numpy as np
import os
from multiprocessing import Process, Queue
import sys
import time
import random
import math
max_num = 1000 #max record number in one file
train_path = 'Imagenet/Imagenet/data/' #the folder stroes the train images
valid_path = 'Imagenet/Imagenet/validation/' #the folder stroes the validation images
cores = 4 #number of CPU cores to process
#Imagenet图片都保存在/data目录下,里面有1000个子目录,获取这些子目录的名字
classes = os.listdir(train_path)
#构建一个字典,Key是目录名,value是类名0-999
labels_dict = {}
for i in range(len(classes)):
labels_dict[classes[i]]=i
#构建训练集文件列表,里面的每个元素是路径名+图片文件名+类名
images_labels_list = []
for i in range(len(classes)):
path = train_path+classes[i]+'/'
images_files = os.listdir(path)
label = str(labels_dict[classes[i]])
for image_file in images_files:
images_labels_list.append(path+','+image_file+','+classes[i])
random.shuffle(images_labels_list)
#读取验证集的图片对应的类名标签文件
valid_classes = []
with open('imagenet_2012_validation_synset_labels.txt', 'r') as f:
valid_classes = [line.strip() for line in f.readlines()]
#构建验证集文件列表,里面的每个元素是路径名+图片文件名+类名
valid_images_labels_list = []
valid_images_files = os.listdir(valid_path)
for file_item in valid_images_files:
number = int(file_item[15:23])-1
valid_images_labels_list.append(valid_path+','+file_item+','+valid_classes[number])
#把图像数据和标签转换为TRRECORD的格式
def make_example(image, height, width, label, bbox, text):
colorspace = b'RGB'
channels = 3
img_format = b'JPEG'
return tf.train.Example(features=tf.train.Features(feature={
'image' : tf.train.Feature(bytes_list=tf.train.BytesList(value=[image])),
'height' : tf.train.Feature(int64_list=tf.train.Int64List(value=[height])),
'width' : tf.train.Feature(int64_list=tf.train.Int64List(value=[width])),
'channels' : tf.train.Feature(int64_list=tf.train.Int64List(value=[channels])),
'colorspace' : tf.train.Feature(bytes_list=tf.train.BytesList(value=[colorspace])),
'img_format' : tf.train.Feature(bytes_list=tf.train.BytesList(value=[img_format])),
'label' : tf.train.Feature(int64_list=tf.train.Int64List(value=[label])),
'bbox_xmin' : tf.train.Feature(float_list=tf.train.FloatList(value=bbox[0])),
'bbox_xmax' : tf.train.Feature(float_list=tf.train.FloatList(value=bbox[2])),
'bbox_ymin' : tf.train.Feature(float_list=tf.train.FloatList(value=bbox[1])),
'bbox_ymax' : tf.train.Feature(float_list=tf.train.FloatList(value=bbox[3])),
'text' : tf.train.Feature(bytes_list=tf.train.BytesList(value=[text]))
}))
#读取bbox文件
bbox_list = {}
with open('bbox_train.csv', 'r') as bboxfile:
records = bboxfile.readlines()
for record in records:
fields = record.strip().split(',')
filename = fields[0][:-4]
xmin = [float(x) for x in fields[1].split(';')]
ymin = [float(x) for x in fields[2].split(';')]
xmax = [float(x) for x in fields[3].split(';')]
ymax = [float(x) for x in fields[4].split(';')]
bbox_list[filename] = [xmin, ymin, xmax, ymax]
#读取Labels的描述
labels_text = {}
with open('imagenet_metadata.txt', 'r') as metafile:
records = metafile.readlines()
for record in records:
fields = record.strip().split('\t')
label = fields[0]
text = fields[1]
labels_text[label] = text
#这个函数用来生成TFRECORD文件,第一个参数是列表,每个元素是图片文件名加类名,第二个参数是写入的目录名
#第三个参数是文件名的起始序号,第四个参数是队列名称,用于和父进程发送消息
def gen_tfrecord(trainrecords, targetfolder, startnum, queue):
tfrecords_file_num = startnum
file_num = 0
total_num = len(trainrecords)
pid = os.getpid()
queue.put((pid, file_num))
writer = tf.python_io.TFRecordWriter(targetfolder+"train_"+str(tfrecords_file_num)+".tfrecord")
for record in trainrecords:
file_num += 1
fields = record.split(',')
img = cv2.imread(fields[0]+fields[1])
height, width, _ = img.shape
img_jpg = cv2.imencode('.jpg', img)[1].tobytes()
label = labels_dict[fields[2]]
bbox = []
try:
bbox = bbox_list[fields[1][:-5]]
except KeyError:
bbox = [[],[],[],[]]
text = labels_text[fields[2]]
ex = make_example(img_jpg, height, width, label, bbox, text.encode())
writer.write(ex.SerializeToString())
#每写入100条记录,向父进程发送消息,报告进度
if file_num%100==0:
queue.put((pid, file_num))
if file_num%max_num==0:
writer.close()
tfrecords_file_num += 1
writer = tf.python_io.TFRecordWriter(targetfolder+"train_"+str(tfrecords_file_num)+".tfrecord")
writer.close()
queue.put((pid, file_num))
#这个函数用来多进程生成TFRECORD文件,第一个参数是要处理的图片的文件名列表,第二个参数是需要用的CPU核心数
#第三个参数写入的文件目录名
def process_in_queues(fileslist, cores, targetfolder):
total_files_num = len(fileslist)
each_process_files_num = int(total_files_num/cores)
files_for_process_list = []
for i in range(cores-1):
files_for_process_list.append(fileslist[i*each_process_files_num:(i+1)*each_process_files_num])
files_for_process_list.append(fileslist[(cores-1)*each_process_files_num:])
files_number_list = [len(l) for l in files_for_process_list]
each_process_tffiles_num = math.ceil(each_process_files_num/max_num)
queues_list = []
processes_list = []
for i in range(cores):
queues_list.append(Queue())
#queue = Queue()
processes_list.append(Process(target=gen_tfrecord,
args=(files_for_process_list[i],targetfolder,
each_process_tffiles_num*i+1,queues_list[i],)))
for p in processes_list:
Process.start(p)
#父进程循环查询队列的消息,并且每0.5秒更新一次
while(True):
try:
total = 0
progress_str=''
for i in range(cores):
msg=queues_list[i].get()
total += msg[1]
progress_str+='PID'+str(msg[0])+':'+str(msg[1])+'/'+ str(files_number_list[i])+'|'
progress_str+='\r'
print(progress_str, end='')
if total == total_files_num:
for p in processes_list:
p.terminate()
p.join()
break
time.sleep(0.5)
except:
break
return total
if __name__ == '__main__':
print('Start processing train data using %i CPU cores:'%cores)
starttime=time.time()
total_processed = process_in_queues(images_labels_list, cores, targetfolder='train_tf/')
endtime=time.time()
print('\nProcess finish, total process %i images in %i seconds'%(total_processed, int(endtime-starttime)))
print('Start processing validation data using %i CPU cores:'%cores)
starttime=time.time()
total_processed = process_in_queues(valid_images_labels_list, cores, targetfolder='valid_tf/')
endtime=time.time()
print('\nProcess finish, total process %i images, using %i seconds'%(total_processed, int(endtime-starttime)))以上代码在我的I3 CPU+16G RAM+SSD硬盘的处理下,每个核心大概不到1秒可以处理100张图片,4个核心大概花了1小时既可以处理这146G的图片,转换为TFRECORD的文件。在处理中我看到系统资源的占用情况,每个核心都基本维持在80%以上,可以看到以上代码充分利用了系统的资源来进行数据的处理。处理结果如下:
Start processing train data using 4 CPU cores:
PID10501:320291/320291|PID10503:320291/320291|PID10505:320291/320291|PID10507:320294/320294|
Process finish, total process 1281167 images in 4113 seconds
Start processing validation data using 4 CPU cores:
PID11270:12500/12500|PID11272:12500/12500|PID11274:12500/12500|PID11276:12500/12500|
Process finish, total process 50000 images, using 161 seconds有意思的是,之前我的电脑配置的是机械硬盘,同样的代码,在刚处理前大约6000张图片时,4个核心的占用率都是基本在100%,但是之后就下降的很快了,每个核心大概占用率都不到10%,处理文件的速度也大大降低,每个核心大概要10几秒才能处理100张图片,因此我猜测是因为机械硬盘在读取大量的小文件时遇到了瓶颈,在缓存满了之后读取速度就大大下降了。趁着现在SSD硬盘便宜,为此我还特意买了一个SSD硬盘来验证我的猜想,果然是在换了SSD之后处理效率大大提升,看来SSD在处理大量小文件上是比机械硬盘强很多了,这个对于机器学习的频繁大量的数据预处理的工作来说还是很有用的。
TFRECORD数据的读取
TFRECORD文件处理完之后,我们可以通过以下的代码来读取这些数据并显示图片,检验一下数据是否生成正确:
import tensorflow as tf
import cv2
import numpy as np
import os
def _parse_function(example_proto):
features = {"image": tf.FixedLenFeature([], tf.string, default_value=""),
"height": tf.FixedLenFeature([1], tf.int64, default_value=[0]),
"width": tf.FixedLenFeature([1], tf.int64, default_value=[0]),
"channels": tf.FixedLenFeature([1], tf.int64, default_value=[3]),
"colorspace": tf.FixedLenFeature([], tf.string, default_value=""),
"img_format": tf.FixedLenFeature([], tf.string, default_value=""),
"label": tf.FixedLenFeature([1], tf.int64, default_value=[0]),
"bbox_xmin": tf.VarLenFeature(tf.float32),
"bbox_xmax": tf.VarLenFeature(tf.float32),
"bbox_ymin": tf.VarLenFeature(tf.float32),
"bbox_ymax": tf.VarLenFeature(tf.float32),
"text": tf.FixedLenFeature([], tf.string, default_value=""),
"filename": tf.FixedLenFeature([], tf.string, default_value="")
}
parsed_features = tf.parse_single_example(example_proto, features)
xmin = tf.expand_dims(parsed_features["bbox_xmin"].values, 0)
xmax = tf.expand_dims(parsed_features["bbox_xmax"].values, 0)
ymin = tf.expand_dims(parsed_features["bbox_ymin"].values, 0)
ymax = tf.expand_dims(parsed_features["bbox_ymax"].values, 0)
bbox = tf.concat(axis=0, values=[ymin, xmin, ymax, xmax])
bbox = tf.expand_dims(bbox, 0)
bbox = tf.transpose(bbox, [0, 2, 1])
height = parsed_features["height"]
width = parsed_features["width"]
channels = parsed_features["channels"]
image_decoded = tf.cast(tf.image.decode_jpeg(parsed_features["image"], channels=3), tf.float32)
begin, size, bbox_for_draw = tf.image.sample_distorted_bounding_box(tf.shape(image_decoded),
bounding_boxes=bbox,
min_object_covered=0.2,
seed=123,
use_image_if_no_bounding_boxes=True)
images = tf.expand_dims(image_decoded, 0)
new_bbox = tf.concat([bbox, bbox_for_draw],axis=1)
image_bbox = tf.cast(tf.image.draw_bounding_boxes(images, new_bbox), tf.uint8)
return image_bbox
with tf.device('/cpu:0'):
dataset_train = tf.data.TFRecordDataset('train_1.tfrecord')
dataset_train = dataset_train.map(_parse_function)
iterator = tf.data.Iterator.from_structure(dataset_train.output_types, dataset_train.output_shapes)
#img, height, width, channels, colorspace, img_format, label, xmin, ymin, xmax, ymax, text = iterator.get_next()
image_bbox = iterator.get_next()
train_init_op = iterator.make_initializer(dataset_train)
sess = tf.Session()
sess.run(train_init_op)
image_bbox_run = sess.run(image_bbox)
img=cv2.cvtColor(image_bbox_run[0],cv2.COLOR_RGB2BGR)
cv2.imshow("image", img)
if cv2.waitKey(5000):
cv2.destroyAllWindows()
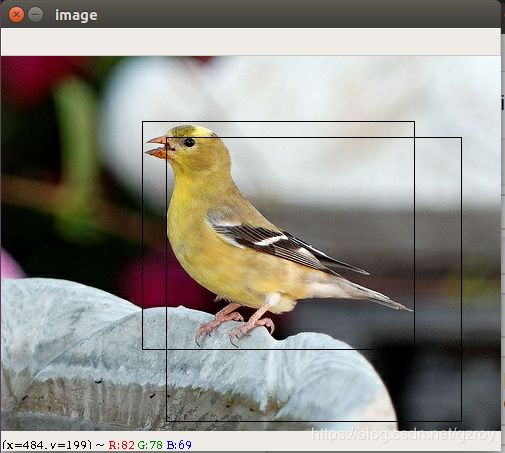
cv2.destroyAllWindows()以上代码读取并显示TFRECORD里面的一张图片,同时也把图片的BBOX画在了图片上。另外代码中还通过sample_distorted_bounding_box函数,随机生成了一个新的BBOX,该BBOX至少覆盖了目标对象的20%以上的区域,这个新的BBOX对应的图像内容可以作为训练集输入的图像增强,提高训练效果。
输出的图片结果如下所示,其中小的BOX是人工标注的,大的BOX是随机生成的。
至此我们对于Imagenet的数据集的处理就全部完成了。在下一篇博客,我将开始基于这些数据集来进行训练和测试了。稍后再和各位分享。:)