解读RefineDet:Single-Shot Refinement Neural Network for Object Detection
RefineDet:Single-Shot Refinement Neural Network for Object Detection
文章目录
- 背景知识:
- Faster R-CNN:https://blog.csdn.net/hancoder/article/details/89922964
- FPN:https://blog.csdn.net/hancoder/article/details/89048870
- SSD:https://blog.csdn.net/hancoder/article/details/89387236
- RefineDet 由3个模块组成:ARM、TCB和ODM
- 锚点提取模块anchor refinement module ARM:类似于faster rcnn中的RPN
- **转换链接模块transfer connection module TCB**:类似于FPN特征融合
- 目标检测模块object detection module ODM:类似于SSD多尺度分类
- RefineDet的框架:
- (1) Transfer Connection Block (TCB)
- (2) Two-Step Cascaded Regression
- (3) Negative Anchor Filtering
- 训练和测试
- 数据增强
- Backbone网络:VGG或resnet加了2层
- anchors设计和匹配:4个特征层
- 负样本挖掘:挑loss大的负anchor
- loss函数:没什么不同
- 优化
- 测试:top400-NMS-top200
- 结果:小物体好
背景知识:
Faster R-CNN:https://blog.csdn.net/hancoder/article/details/89922964
FPN:https://blog.csdn.net/hancoder/article/details/89048870
SSD:https://blog.csdn.net/hancoder/article/details/89387236
现存问题:单阶段预测快但不准的主要原因:类别不平衡
RefineDet 由3个模块组成:ARM、TCB和ODM
锚点提取模块anchor refinement module ARM:类似于faster rcnn中的RPN
作用:
(1) filter out negative anchors to reduce search space for the classifier, and过滤负锚点,减少分类的搜索空间
(2) coarsely adjust the locations and sizes of anchors to provide better initialization for the subsequent regressor.粗略地调整位置和大小,给后续回归提供更好的初始化
ARM的结构是在预训练后的VGG16或resnet101基础上添加了一些辅助结构。
转换链接模块transfer connection module TCB:类似于FPN特征融合
用来转换特征。连接ARM和ODM,引进TCB把ARM的不同层的特征转换到ODM模块需要的形式。跟在TCB模块后面的3×3产生了目标分类的得分和调整后的锚框位置的位置偏移。用来在目标检测模块可以预测位置,大小,和物体类标。
目标检测模块object detection module ODM:类似于SSD多尺度分类
拿上一步TCB输出的refined anchors框作为输入,融合不同层的特征,进一步改善回归和多类别预测,回归准确的位置
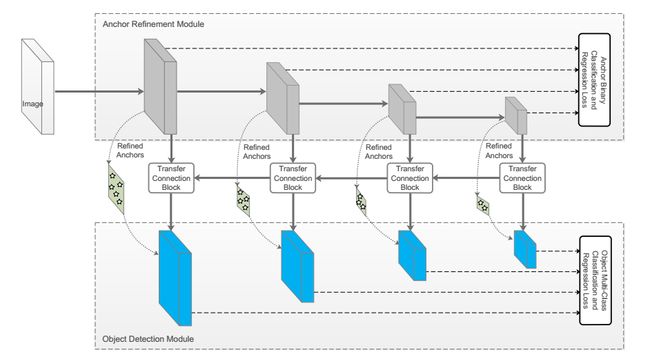
分别对应P3456,P6是在原有网络上另加的,通过3×3卷积C5网络得到
内联模块模拟两阶段结构
RefineDet的框架:
(1) transfer connection block (TCB), converting the features from the ARM to the ODM for detection;
(2) two-step cascaded regression,accurately regressing the locations and sizes of objects;
(3) negative anchor filtering, early rejecting well-classified negative anchors and mitigate the imbalance issue
(1) Transfer Connection Block (TCB)
显然,在ARM上,仅仅使用与锚点有关的特征图的TCB模块。TCB的另外一个功能是通过添加高层特征到转换特征,去integrate大尺度context,来提高准确率。为了匹配他们的维度,使用反卷积操作去扩大高层特征图,然后对应元素相加。相加之后添加一个卷积层来确保discriminability of features for detection. 如图2

(2) Two-Step Cascaded Regression
使用ARM首先调整anchors的大小和位置,为ODM的回归提供一个好的初始化。每个grid是n个anchors框。每个anchors框的初始位置是固定的。在每个特征图单元,拿refined anchor框预测4个offset,和两个置信度分数(前背景)。在每个特征图单元上可以产生n个anchors
得到refined anchor框后,输入到ODM进行下一步分类和位置大小回归。在ARM和ODM的相关特征图上有相同的维度。每个refined anchors产生c个分类和4个位置信息。这与SSD中的默认框相似。而与SSD不同的是,SSD直接使用默认框预测,而refineDet使用双阶段策略:ARM产生refined anchors,ODM把refined anchors作为输入进行下一步检测。,所以更准,尤其是小物体
(3) Negative Anchor Filtering
为了尽早reject易分类的负anchor,也为了减轻不平衡问题,设计了负anchor过滤机制。尤其是,在训练阶段,如果负样本的负置信度大于一个阈值θ,在训练ODM时将被抛弃。也就是说,值通过refined难负anchor和refined正anchor去训练ODM。同时,在测试阶段,也是由θ存在并起作用的。
训练和测试
数据增强
用光学扭曲photometric distortion和镜像flip,去随机expand和crop原始图像
Backbone网络:VGG或resnet加了2层
VGG-16和Resnet-101,用ILSVRC CLS-LOC 预训练。与DeepLab-LargeFOV 类似,把VGG16的FC6,FC7转为conv6和conv7。与其他层比较,conv4_3和conv5_3有不同的大小,使用L2正则化去scale the feature norms,Since conv4 3 and conv5 3 have different feature scales compared to other layers, we use L2 normalization [31] to scale the feature norms in conv4 3 and conv5 3 to 10 and 8 ,。然后通过反向传播学习scales。为了学习高级信息在多尺度上检测,在VGG16末尾添加了连个额外的卷积层conv6_1和conv6_2,类似地在resnet末尾也添加了一个额外的residual block。
anchors设计和匹配:4个特征层
选了4个特征层,步长为8,16,32,64。每个特征图的尺度不一样,而且也是由3个ratio比率0.5,1,2。用IoU评估预测框和gt框。匹配规则跟大众规则一样,先选最高的赋gt,然后阈值为0.5。
负样本挖掘:挑loss大的负anchor
选取负样本的top_n大的loss,负正比例3:1,这里注意不是随机选的,是挑loss大的。
loss函数:没什么不同
跟常规loss没什么特别的地方。loss=前背景二分类ARMloss+多分类ODMloss
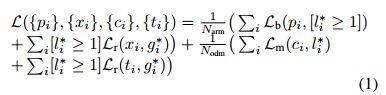
i是一个mini batch里anchor的索引, l i ∗ l_i^* li∗是第i个anchor的gt类标。 g i ∗ g_i^* gi∗是对应的gt框位置大小信息。p_i和x_i分别是在ARM中的第i个anchor为前景的可能性和位置大小信息。c_i和t_i分别是ODM中的类别和位置信息。 N a r m N_{arm} Narm和 N o d m N_{odm} Nodm是在ARM和ODM中的正的anchor的数目。 L b L_b Lb是二分类交叉熵, L m L_m Lm是多分类softmax置信度。与fast rcnn相似,用smooth L1作为回归loss Lr, [ l i ∗ > = 1 ] [l_i^*>=1] [li∗>=1]是anchor不为负时候输出1,否则是0。就是说负anchor不回归位置loss。
优化
使用xavier 方法随机初始化新加的额外两层的参数,用[0,0.01]高斯分布初始化。设置默认框带下为32。动量为0.9,权重衰减为0.005的SGD。初始学习率0.001。default batch size 32 。不同数据集会有些许不同。
测试:top400-NMS-top200
ODM输入refined anchors后,每张图片输出top 400高置信度anchor。然后每个类用IoU阈值为0.45的非极大值抑制NMS,每张保留top 200产生最后的预测结果。
结果:小物体好
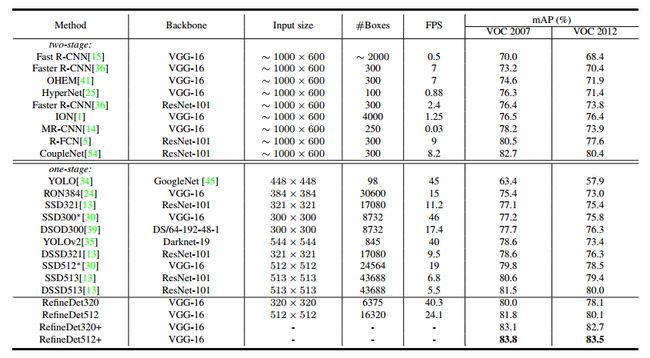
在VOC2007和2012上,获得了85.8%,86.8%
在COCO获得41.8% AP 用了resnet101
输入大小和320×320和512×512的速度分别是40.2FPS和24.1FPS
输入大小影响结果,效果原因是高分辨率输入使得检测看到了小物体。