python机器学习库scikit-learn简明教程之:随机森林
1.scikit-learn中的随机森林
sklearn.ensemble模块中包含两种基于随机决策树的平均算法:随机森林算法和ExtraTrees的方法。这两种算法都是专为决策树设计的包含混合扰动技术的算法。这意味着分类器依赖着引入随机性来进行建模。整体的预测结果,来自各个独立分类器的综合平均预测结果。
原理:随机森林,顾名思义,就是用随机的方式建立一个森林,森林里面有很多的决策树组成,随机森林的每一棵决策树之间是独立没有关联的。在得到森林之后,当有一个新的输入样本进入的时候,就让森林中的每一棵决策树分别进行一下判断,看看这个样本应该属于哪一类,然后看看哪一类被选择最多,就预测这个样本为那一类。
2.随机森林算法quick-start代码
#gnu
>>> from sklearn.ensemble import RandomForestClassifier
>>> X = [[0, 0], [1, 1]]
>>> Y = [0, 1]
>>> clf = RandomForestClassifier(n_estimators=10)
>>> clf = clf.fit(X, Y)
#gnu在这里,我们建立了一个极其简单的classifer(分类器);如决策树问题一样,随机森林的决策树也可以扩展到多输出问题(如果Y是[ n_samples,n_outputs ]形态规模的数组)。
3.进阶:极端随机树:Extremely randomized trees
ET或Extra-Trees(Extremely randomized trees,极端随机树)是由PierreGeurts等人于2006年提出。该算法与随机森林算法十分相似,都是由许多决策树构成。但该算法与随机森林有两点主要的区别:
1、随机森林应用的是Bagging模型,而ET是使用所有的训练样本得到每棵决策树,也就是每棵决策树应用的是相同的全部训练样本;
2、随机森林是在一个随机子集内得到最佳分叉属性,而ET是完全随机的得到分叉值,从而实现对决策树进行分叉的。
>>> from sklearn.model_selection import cross_val_score
>>> from sklearn.datasets import make_blobs
>>> from sklearn.ensemble import RandomForestClassifier
>>> from sklearn.ensemble import ExtraTreesClassifier
>>> from sklearn.tree import DecisionTreeClassifier
>>> X, y = make_blobs(n_samples=10000, n_features=10, centers=100,
... random_state=0)
#在这里我们先引入一些训练数据集
>>> clf = DecisionTreeClassifier(max_depth=None, min_samples_split=2,
... random_state=0)
#定义一个决策树分类器
>>> scores = cross_val_score(clf, X, y)
>>> scores.mean()
0.97...
#这里是决策树的模型精准度得分
>>> clf = RandomForestClassifier(n_estimators=10, max_depth=None,
... min_samples_split=2, random_state=0)
#定义一个随机森林分类器
>>> scores = cross_val_score(clf, X, y)
>>> scores.mean()
0.999...
#这里是随机森林训练器的模型精确度得分
>>> clf = ExtraTreesClassifier(n_estimators=10, max_depth=None,
... min_samples_split=2, random_state=0)
#定义一个极端森林分类器
>>> scores = cross_val_score(clf, X, y)
>>> scores.mean() > 0.999
True
#这里是极端森林训练器的模型精确度得分,效果优于随机森林
算法结果比较(新增AdaBoost算法)
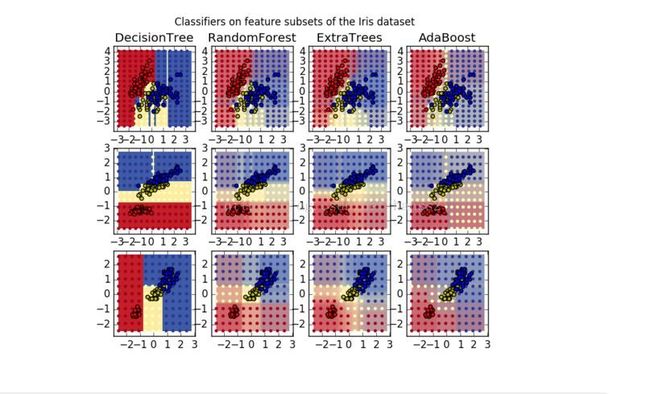
相较于神经网络(更加复杂更加精准,但是速度更慢,计算量很大,不容易构建),随机森林算法还很年轻,有的场合使用,更加快速高效;(我们的训练数据集数据及其规整干净理想,所以才能达到如此高的精确度,现实中是会打折扣的);