《Hadoop权威指南》——4、Hadoop的I/O
第4章 Hadoop IO
HDFS完整性
客户端在读取数据块时会验证校验和:校验和----不可靠传输----校验和
客户端(数据+校验和)------管线(dataNode组成)------>最后一个dataNode负责验证校验和。checksumException异常。
数据压缩
可切分的压缩格式更适合于MapReduce
FileOutputFormat.setCompressOutput(job, true);
FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);
//Map输出压缩
conf.setCompressMapOutput(true);
conf.setMapOutputCompressorClass(GzipCodec.class);- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
序列化
序列化:
将结构化对象转化为字节流以便在网络上传输或写到磁盘进行永久存储的过程。
反序列化:
将字节流转回结构化对象。
序列化出现:
进程间通信,永久存储
RPC远程过程调用:系统中多个节点上进程间的通信。
RPC序列化格式:紧凑,快速,可扩展,支持互操作。
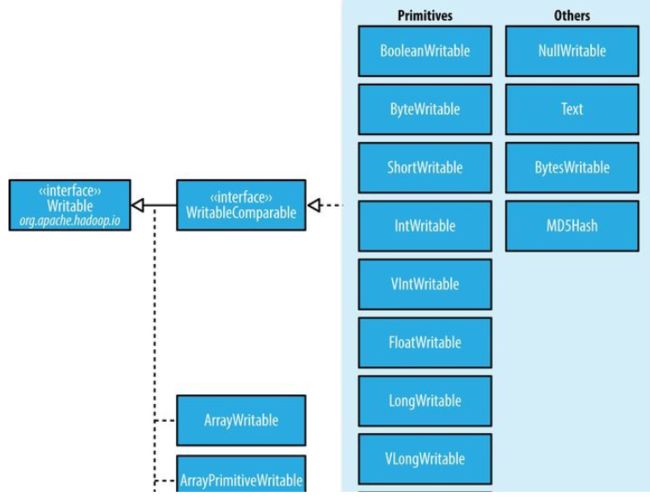
Writable接口
(writable是hadoop自己的序列化格式。)
Writable接口定义了两个方法:一个将其状态写到DataOutput二进制流,另一个从DataInput二进制流读取状态:
writable类对java基本类型提供封装。
package org.apache.hadoop.io;
import java.io.DataOutput;
import java.io.DataInput;
import java.io.IOException;
public interface Writable {
void write(DataOutput out) throws IOException;
void readFields(DataInput in) throws IOException;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
Text类型
5 ObjectWritable和GenericWritable
ObjectWritable是对Java基本类型(String,enum,Writable,null)的一个通用封装。
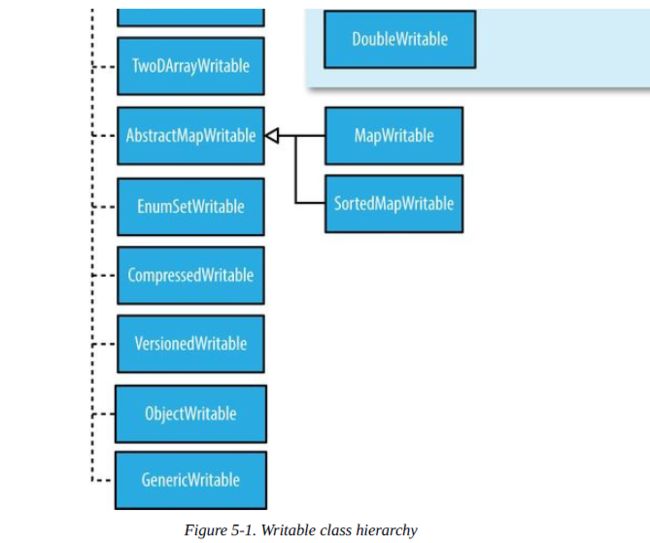
6 Writable集合类
ArrayWritable, ArrayPrimitiveWritable, TwoDArrayWritable, MapWritable,
SortedMapWritable, 和 EnumSetWritable.
实现定制的Writable集合
import java.io.*;
import org.apache.hadoop.io.*;
public class TextPair implements WritableComparable {
private Text first;
private Text second;
public TextPair() {
set(new Text(), new Text());
}
public TextPair(String first, String second) {
set(new Text(first), new Text(second));
}
public TextPair(Text first, Text second) {
set(first, second);
}
public void set(Text first, Text second) {
this.first = first;
this.second = second;
}
public Text getFirst() {
return first;
}
public Text getSecond() {
return second;
}
@Override
public void write(DataOutput out) throws IOException {
first.write(out);
second.write(out);
}
@Override
public void readFields(DataInput in) throws IOException {
first.readFields(in);
second.readFields(in);
}
@Override
public int hashCode() {
return first.hashCode() * 163 + second.hashCode();
}
@Override
public boolean equals(Object o) {
if (o instanceof TextPair) {
TextPair tp = (TextPair) o;
return first.equals(tp.first) && second.equals(tp.second);
}
return false;
}
public String toString() {
return first + "\t" + second;
}
@Override
public int compareTo(TextPair tp) {
int cmp = first.compareTo(tp.first);
if (cmp != 0) {
return cmp;
}
return second.compareTo(tp.second);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
SequenceFile
SequenceFile为二进制键/值对提供了一个持久数据结构。它也可以作为小文件的容器。
SequenceFile的写操作:
写一个SequenceFile:
public class SequenceFileWriteDemo {
private static final String[] DATA = {
"One, two, buckle my shoe",
"Three, four, shut the door",
"Five, six, pick up sticks",
"Seven, eight, lay them straight",
"Nine, ten, a big fat hen"
};
public static void main(String[] args) throws IOException {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path path = new Path(uri);
IntWritable key = new IntWritable();
Text value = new Text();
SequenceFile.Writer writer = null;
try {
writer = SequenceFile.createWriter(fs, conf, path,
key.getClass(), value.getClass());
for (int i = 0; i < 100; i++) {
key.set(100 - i);
value.set(DATA[i % DATA.length]);
System.out.printf("[%s]\t%s\t%s\n", writer.getLength(), key, value);
writer.append(key, value);
}
} finally {
IOUtils.closeStream(writer);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
SequenceFile的读操作:
public class SequenceFileReadDemo {
public static void main(String[] args) throws IOException {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path path = new Path(uri);
SequenceFile.Reader reader = null;
try {
reader = new SequenceFile.Reader(fs, path, conf);
Writable key = (Writable)
ReflectionUtils.newInstance(reader.getKeyClass(), conf);
Writable value = (Writable)
ReflectionUtils.newInstance(reader.getValueClass(), conf);
long position = reader.getPosition();
while (reader.next(key, value)) {
String syncSeen = reader.syncSeen() ? "*" : "";
System.out.printf("[%s%s]\t%s\t%s\n", position, syncSeen, key, value);
position = reader.getPosition(); // beginning of next record
}
} finally {
IOUtils.closeStream(reader);
}
}
}
下面介绍几个常用的Writable类:
(1)Text类:
Text类是针对UTF-8序列(UTF-8是UNICODE的一种变长字节字符编码,又称万国码)的Writable类,一般认为他等价与java.lang.String的Writable类。但是他和String还是有一些差异的。Text的索引是按编码后字节序列中的位置来实现的,String是按其所包含的char编码单元来索引的。看下面的例子:
String s=String("\u0041\u00df\uu6671\ud801\uDc00");
Text t=Text("\u0041\u00df\uu6671\ud801\uDc00");
s.indexof("\u0041")==0 t.find("\u0041")==0
s.indexof("\u00df")==1 t.find("\u00df")==1
s.indexof("\u6671")==2 t.find("\u6671")==3
s.indexof("\ud801\uDc00")==3 t.find(\ud801\uDc00")==6
s.length()==5 s.getBytes("UTF-8").length()==10
t.getLength()==10(1+2+3+4)
通过字节偏移量来进行位置索引,实现对Text类的Unicode字符迭代是非常复杂的,因为不能简单的通过增加位置的索引值来实现。所以必先将Text对象转化为java.nio.BytesBuffer对象,然后利用缓冲区对Text对象反复调用bytesToCodePoint()静态方法,该方法能获取下一代码的位置。
由于Text类不像java.lang.String类那样有丰富的字符串操作API,所以在一些情况下为了方便处理,需要将Text类转化为String类,这一过程通过toString来实现。
(2)ByteWritable类,二进制数据数组的封装,它的序列化格式为一个用于指定后面数据字节数的整数域(4字节),后跟字节本身。
(3)NullWritabe,是Writable的一个特殊类型,它的序列化长度为0,类似于null。
(4)ObjectWritable类,是对java基本类型(String,enum,Writable,null或这些类型组成的数组)的一个通用封装。
(5)Writable集合类,共有4个集合类,其中ArrayWritable是对Writable的数组的实现,TwoDArrayWritable是对Writable的二维数组的实现,MapWritable是对Map的实现,SortedMapWritable是对SortedMap的实现。
(6)定制的Writable类,我们可以根据自己的需求构造自己的Writable类,可以根据需要控制二进制表示和排序顺序,由于Writable是MapReduce数据路径的核心,所以调整二进制表示能对性能残生显著效果。
3 Hadoop的序列化框架——Avro
Avro(读音类似于[ævrə])是Hadoop的一个子项目,由Hadoop的创始人Doug Cutting(也是Lucene,Nutch等项目的创始人,膜拜)牵头开发,当前最新版本1.3.3。Avro是一个数据序列化系统,设计用于支持大批量数据交换的应用。它的主要特点有:支持二进制序列化方式,可以便捷,快速地处理大量数据;动态语言友好,Avro提供的机制使动态语言可以方便地处理Avro数据。
当前市场上有很多类似的序列化系统,如Google的Protocol Buffers, Facebook的Thrift。这些系统反响良好,完全可以满足普通应用的需求。针对重复开发的疑惑,Doug Cutting撰文解释道:Hadoop现存的RPC系统遇到一些问题,如性能瓶颈(当前采用IPC系统,它使用Java自带的DataOutputStream和DataInputStream);需要服务器端和客户端必须运行相同版本的Hadoop;只能使用Java开发等。但现存的这些序列化系统自身也有毛病,以Protocol Buffers为例,它需要用户先定义数据结构,然后根据这个数据结构生成代码,再组装数据。如果需要操作多个数据源的数据集,那么需要定义多套数据结构并重复执行多次上面的流程,这样就不能对任意数据集做统一处理。其次,对于Hadoop中Hive和Pig这样的脚本系统来说,使用代码生成是不合理的。并且Protocol Buffers在序列化时考虑到数据定义与数据可能不完全匹配,在数据中添加注解,这会让数据变得庞大并拖慢处理速度。其它序列化系统有如Protocol Buffers类似的问题。所以为了Hadoop的前途考虑,Doug Cutting主导开发一套全新的序列化系统,这就是Avro,于09年加入Hadoop项目族中。
Avro是Hadoop中的一个重要的项目,不是三言两语能说清楚的,这片文章是专门介绍Avro的,感觉写的不错,我前面写的这段来自于这篇文章,地址:[http://langyu.iteye.com/blog/708568]
4 SequenceFile和MapFile
Hadoop的HDFS和MapReduce子框架主要是针对大数据文件来设计的,在小文件的处理上不但效率低下,而且十分消耗内存资源(每一个小文件占用一个Block,每一个block的元数据都存储在namenode的内存里)。解决办法通常是选择一个容器,将这些小文件组织起来统一存储。HDFS提供了两种类型的容器,分别是SequenceFile和MapFile。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 2