机器学习之K-Means聚类算法
机器学习之K-Means聚类模型
- 1、K-Means介绍
- 2、K-Means数学原理
- 3、算法及Python实现
4、小结
1、K-Means介绍
聚类是一种无监督学习,它将相似的对象归到同一个簇中。K-均值聚类算法可以发现k个不同的簇,且每个簇的中心采用簇中所含值的均值计算而成。下图为一个k=4的K-Means算法聚类的结果。
2、K-Means数学原理
寻找最近重心
对每个点,找到重心j使得

也就是欧氏距离最小。
计算重心
第k个团的重心计算方法如下

3、算法及Python实现
K-Means聚类算法:
创建k个点作为起始质心(经常是随机选择)
当任意一个点的簇分配结果发生改变时
对数据集中的每个数据点
对每个质心
计算质心与数据点之间的距离
将数据点分配到距其最近的簇
对每一个簇,计算簇中所有点的均值并将均值作为质心这里再介绍二分K-均值算法
二分K-均值聚类算法:
将所有点看成一个簇
当簇数目小于k时
对于每一个簇
计算总误差
在给定的簇上面进行K-均值聚类(k=2)
计算将该簇一分为二之后的总误差
选择使得误差最小的那个簇进行划分操作
Python代码实现K-Means算法和二分K-Means聚类算法(用到的数据集testSet2.txt)
from numpy import *
def loadDataSet(fileName):
dataMat = []
fr = open(fileName)
for line in fr.readlines():
curLine = line.strip().split('\t')
fltLine = list(map(float,curLine))
dataMat.append(fltLine)
return dataMat
def distEclud(vecA,vecB): #计算欧氏距离
return sqrt(sum(power(vecA-vecB,2)))
def randCent(dataSet,k): #随机生成一个聚类中心
n = shape(dataSet)[1]
centroids = mat(zeros((k,n)))
for j in range(n):
minJ = min(dataSet[:,j])
rangeJ = float(max(dataSet[:,j])-minJ)
centroids[:,j] = minJ + rangeJ * random.rand(k,1)
return centroids
#kMeans算法,主要是通过两个步骤进行迭代,1.计算损失,找距离最近的聚类中心,分配聚类中心
#2.根据每个聚类中心所属数据,计算平均值更新聚类中心值
def kMeans(dataSet,k,distMeas=distEclud,createCent=randCent):
m = shape(dataSet)[0]
clusterAssment = mat(zeros((m,2)))
centroids = createCent(dataSet,k)
clusterChanged = True
while clusterChanged:
clusterChanged = False
for i in range(m):
minDist = inf; minIndex = -1
for j in range(k):
distJI = distMeas(centroids[j,:],dataSet[i,:])
if distJI < minDist:
minDist = distJI; minIndex = j
if clusterAssment[i,0] != minIndex:
clusterChanged = True
clusterAssment[i,:] = minIndex,minDist**2
print(centroids)
for cent in range(k):
ptsInClust = dataSet[nonzero(clusterAssment[:,0].A==cent)[0]]
centroids[cent,:] = mean(ptsInClust,axis=0)
return centroids, clusterAssment
#二分K-Means算法
def biKmeans(dataSet,k,distMeas=distEclud):
m = shape(dataSet)[0]
clusterAssment = mat(zeros((m,2)))
centroid0 = mean(dataSet,axis=0).tolist()[0]
centList = [centroid0]
for j in range(m):
clusterAssment[j,1]=distMeas(mat(centroid0),dataSet[j,:])**2
#循环迭代,直到聚类中心数目达到要求为止
while(len(centList)for i in range(len(centList)):
ptsInCurrCluster = dataSet[nonzero(clusterAssment[:,0].A==i)[0],:] #找属于当前聚类中心i的所有数据点
centroidMat,splitClustAss = kMeans(ptsInCurrCluster,2,distMeas) #利用K-Means算法将找到的属于当前聚类中心的数据,再进K=2的聚类
sseSplit = sum(splitClustAss[:,1]) #上面进行聚类操作数据点的所有损失
sseNotSplit = sum(clusterAssment[nonzero(clusterAssment[:,0].A!=i)[0],1]) #没进行上面聚类的所有数据点的损失
print("sseSplit, and notSplit:",sseSplit,sseNotSplit)
if(sseSplit+sseNotSplit) < lowestSSE: #如果两者相加小于当前最小损失,即上面的分类时有效果的
bestCentToSplit = i #记录下当前最好的切分类号,即这个类还可以继续划分
bestNewCents = centroidMat #记录下上面分类返回的两个聚类中心
bestClustAss = splitClustAss.copy() #记录下上面聚类返回的数据点及对应的分配的新聚类中心编号(0,1)
lowestSSE = sseSplit + sseNotSplit #更新最小损失值
#下面两行代码,将当前找到的最好的切分点(即类别号)切分出来的新类0,仍然沿用改最好的切分点,
#而新类1,则直接分配给当前最大的类别号(注意分类的类号是从0开始的,所以len(centList)这个数字还没有使用)
bestClustAss[nonzero(bestClustAss[:,0].A == 1)[0],0] = len(centList)
bestClustAss[nonzero(bestClustAss[:,0].A == 0)[0],0] = bestCentToSplit
print('the bestCentToSplit is:',bestCentToSplit)
print('the len of bestClustAss is:',len(bestClustAss))
#这里bestNewCents是matrix型,为了方便后面centList里的元素都是一维的,继而返回时转换为mat,所以转换为array型
bestNewCents = array(bestNewCents)
#下面两行代码和上面两行代码类似,将最好切分点的聚类中心修改为,新划分的0号的聚类中心,再将1号的聚类中心加入聚类中心list中
centList[bestCentToSplit] = bestNewCents[0,:]
centList.append(bestNewCents[1,:])
clusterAssment[nonzero(clusterAssment[:,0].A == bestCentToSplit)[0],:] = bestClustAss
return mat(centList),clusterAssment datMat = mat(loadDataSet('./testSet2.txt'))
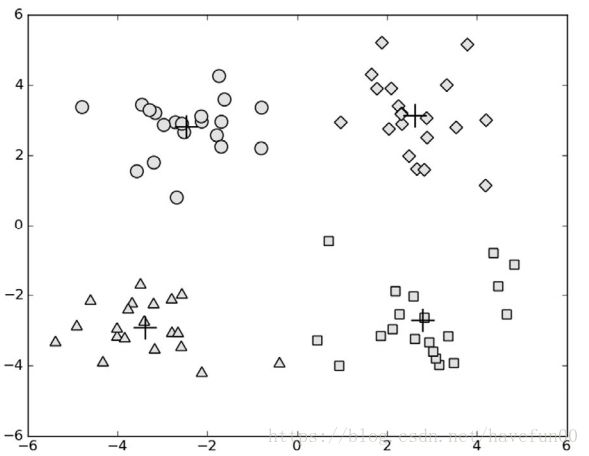
myCentroids,clusterAssing = kMeans(datMat,3)
centList,myNewAssments = biKmeans(datMat,3)输出结果如下图

4、小结
聚类是一种无监督的学习算法,所谓无监督就是指事先并不知道要寻找的内容,即没有目标变量,聚类将数据点归到多个簇中,其中相似数据点处于同一簇中,而不相似数据点处于不同簇中。K-Means算法使用非常广泛,以K个随机质心开始,算法会计算每个点到质心的距离,每个点会被分配到距其最近的簇的质心,然后紧接着基于新分配到簇的点更新簇质心,以上过程重复数次,直到簇质心不再改变。这个简单的算法非常有效,但也容易受初始质心的影响,为了获得更好的聚类效果,又介绍了二分K-Means聚类算法,二分K-Means聚类算法首先将所有的点作为一个簇,然后使用K-Means(k=2)进行划分,下一次迭代时,选择有最大误差的簇进行划分,该过程重复迭代直到K个簇创建成功为止。整体来说,二分K-Means的聚类效果要好于K-Means算法。