机器学习之关联分析与频繁项集(Apriori和FP-Growth算法)
机器学习之关联分析与频繁项集(Apriori和FP-Growth算法)
- 1、关联分析与频繁项集介绍
- 2、Apriori和FP-Growth算法数学原理
- 3、Apriori和FP-Growth算法及Python实现
- 4、小结
1、关联分析和频繁项集介绍
关联分析:从大规模数据集中寻找物品间的隐含关系被称作关联分析(association analysis)或者关联规则学习,典型的例子有“尿布和啤酒”。

频繁项集:频繁项集是指那些经常出现在一起的物品集合。例如上图中的集合{葡萄酒,尿布,豆奶}就是一个频繁项集。
2、Apriori和FP-Growth算法数学原理
首先需要说明的是这两种算法都是为了寻找频繁项集,Apriori算法能够帮助快速进行关联分析,减少计算量,而FP-Growth算法主要用来寻找频繁项集,速度优于Apriori算法。
支持度:数据集中包含该项集的记录所占的比例,例如上图中{豆奶}的支持度为4/5。
可信度:是针对一条诸如{尿布} → {\rightarrow} →{葡萄酒}的关联规则来定义的,这条规则的可信度被定义为“支持度({尿布,葡萄酒})/支持度({尿布})”。根据上图可以得到“尿布 → {\rightarrow} →葡萄酒”这个规则的可信度为(3/5)/(4/5)=0.75。这意味着对于包含尿布的所有记录中,我们的规则对其中75%的记录都适用。
Apriori原理:通过对所有物品进行所有可能的组合,通过遍历每条交易记录,检查包含该集合的记录条数,计算支持度。下图是集合{0,1,2,3}中所有可能的项集组合。

由图可以发现随着商品数目的增加,组合数目会呈爆炸式增长,为了降低所需的计算时间,研究发现一种所谓的Apriori原理,即如果某个项集是频繁的,那么它的所有子集也是频繁的,反过来也成立,即如果说一个项集是非频繁集,那么它的所有超集也是非频繁的。
假如已知阴影项集{2,3}是非频繁的,则可以进行一些剪枝

关联规则:关联规则首先从一个频繁项集开始,我们可以为每个频繁项集产生许多规则,以频繁项集{0,1,2,3}为例,所有的关联规则如下图所示

同样为了对树进行剪枝,我们有如下规则:如果某条规则不满足最小可信度要求,那么该规则的所有子集也不会满足最小可信度要求,已上图为例,假设0,1,2 → \rightarrow → 3并不满足最小可信度,则任何左部分为{0,1,2}子集的规则也不会满足最小可信度的要求(图中阴影部分即是不满足最小可信度的项集)
FP树:FP-Growth算法将数据存储在一种称为FP树的紧凑数据结构中,FP代表频繁模式(Frequent Pattern),下图是一个FP树的例子

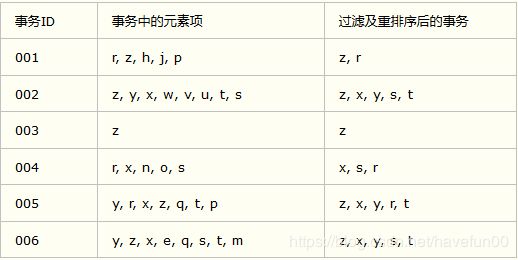
根据上述事务数据样例生成的FP树(数字代表出现次数),如下图所示

构建FP树:这里需要遍历两次数据集,第一次遍历数据集会获得每个元素的出现频率,接下来,去掉不满足最小支持度的元素项,再下一步构建FP树,在构建时,读入每个项集并将其添加到一条已经存在的路径中,如果该路径不存在则创建一条路径(从树根节点到下方节点即为一条路径)
下图是根据每个元素项的出现频率由高到低进行重排后的结果(这里频繁项集的最小支持度为3,这里移除了非频繁项)
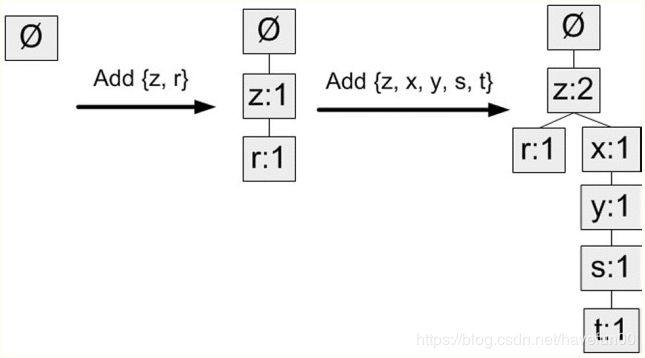
在对事物记录过滤和排序之后,就可以构建FP树了,从空集开始,向其中不断添加频繁项集。过滤排序后的事物一次添加到树中,如果树中已存在现有元素,则增加现有元素值,如果现有元素不存在,则向树中添加一个分支。
3、Apriori和FP-Growth算法及Python实现
Apriori算法
当集合中项的个数大于0时
构建一个K个项组成的候选项集的列表
检查数据以确认每个项集都是频繁的
保留频繁项集并构建K+1项组成的候选项集的列表
FP-Growth
从FP树中抽取频繁项集的三个基本步骤如下:
(1)从FP树中获得条件模式集;
(2)利用条件模式基,构建一个条件FP树;
(3)迭代重复步骤(1)步骤(2),直到树包含一个元素项为止
Apriori算法Python实现
def loadDataSet(dataDir=""):
fopen = open(dataDir)
mushDataSet = [line.split() for line in fopen.readlines()]
return mushDataSet
# return [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]
def createC1(dataSet):
C1 = []
for transaction in dataSet:
for item in transaction:
if not [item] in C1:
C1.append([item])
C1.sort()
return list(map(frozenset,C1))
def scanD(D,Ck,minSupport):
ssCnt = {}
for data in D:
for can in Ck:
if can.issubset(data):
if not can in ssCnt:
ssCnt[can] = 1
else:
ssCnt[can] += 1
numItems = float(len(D))
retList = []
supportData = {}
for key in ssCnt:
support = ssCnt[key]/numItems
if support >= minSupport:
retList.insert(0,key)
supportData[key] = support
return retList, supportData
def aprioriGen(Lk,k): #creates Ck
retList = []
lenLk = len(Lk)
for i in range(lenLk):
for j in range(i+1,lenLk):
L1 = list(Lk[i])[:k-2]
L2 = list(Lk[j])[:k-2]
L1.sort();L2.sort()
if L1==L2:
retList.append(Lk[i] | Lk[j])
return retList
def apriori(dataSet,minSupport=0.5):
C1 = createC1(dataSet)
D = list(map(set,dataSet))
L1,supportData = scanD(D,C1,minSupport)
L = [L1]
k = 2
while (len(L[k-2]) > 0): #判断当前最后生成的L是否为空
Ck = aprioriGen(L[k-2],k)
Lk,supK = scanD(D,Ck,minSupport)
supportData.update(supK) #将新生成的集合的支持度字典更新到总字典中去
L.append(Lk) #将新生成的频繁项集添加到总频繁项集中去
k += 1
return L,supportData
def generateRules(L,supportData,minConf=0.7):
bigRuleList = []
for i in range(1,len(L)): #只从含有两个以上元素的频繁项集
for freqSet in L[i]:
H1 = [frozenset([item]) for item in freqSet]
if(i > 1):
rulesFromConseq(freqSet,H1,supportData,bigRuleList,minConf)
else:
calcConf(freqSet,H1,supportData,bigRuleList,minConf)
return bigRuleList
def calcConf(freqSet,H,supportData,brl,minConf=0.7):
prunedH = []
for conseq in H:
if supportData[freqSet-conseq]==0:
continue
conf = supportData[freqSet]/supportData[freqSet-conseq]
if conf >= minConf:
print(freqSet-conseq,"-->",conseq,"conf:",conf)
brl.append((freqSet-conseq,conseq,conf))
prunedH.append(conseq)
return prunedH
def rulesFromConseq(freqSet,H,supportData,brl,minConf=0.7):
m = len(H[0])
if(len(freqSet)>(m+1)):
Hmp1 = aprioriGen(H,m+1)
Hmp1 = calcConf(freqSet,Hmp1,supportData,brl,minConf)
if(len(Hmp1)>1): #至少需要两个集合才能合并
rulesFromConseq(freqSet,Hmp1,supportData,brl,minConf)
使用下面代码调用程序,数据集在这里mushroomLite.txt
dataSet = loadDataSet(dataDir="./mushroomLite.txt")
L,supportData = apriori(dataSet,minSupport=0.95)
rules = generateRules(L,supportData,minConf=0.95)
print(rules)
输出的结果如下

FP-Growth算法Python实现
class treeNode:
def __init__(self,nameValue,numOccur,parentNode):
self.name = nameValue
self.count = numOccur
self.nodeLink = None
self.parent = parentNode
self.children = {}
def inc(self,numOccur):
self.count += numOccur
def disp(self,ind=1):
print(" "*ind,self.name," ",self.count)
for child in self.children.values():
child.disp(ind+1)
def loadDataSet(dataDir=""):
fopen = open(dataDir)
mushDataSet = [line.split() for line in fopen.readlines()]
return mushDataSet
def createInitSet(dataSet):
retDict = {}
for trans in dataSet:
retDict[frozenset(trans)] = 1
return retDict
def createTree(dataSet,minSup=1):
headerTable = {}
for trans in dataSet:
for item in trans:
headerTable[item] = headerTable.get(item,0)+dataSet[trans]
for k in list(headerTable.keys()):
if headerTable[k] < minSup:
del(headerTable[k])
freqItemSet = set(headerTable.keys())
if len(freqItemSet) == 0:
return None,None
for k in headerTable:
headerTable[k] = [headerTable[k],None]
retTree = treeNode("Null Set",1,None)
for tranSet,count in dataSet.items():
localD = {}
for item in tranSet:
if item in freqItemSet:
localD[item] = headerTable[item][0]
if len(localD) > 0:
orderedItems = [v[0] for v in sorted(localD.items(),key=lambda p:p[1],reverse=True)]
updateTree(orderedItems,retTree,headerTable,count)
return retTree,headerTable
def updateTree(items, inTree, headerTable, count):
if items[0] in inTree.children:
inTree.children[items[0]].inc(count)
else:
inTree.children[items[0]] = treeNode(items[0], count, inTree)
if headerTable[items[0]][1] == None:
headerTable[items[0]][1] = inTree.children[items[0]]
else:
updateHeader(headerTable[items[0]][1], inTree.children[items[0]])
if len(items) > 1:
updateTree(items[1::], inTree.children[items[0]], headerTable, count)
def updateHeader(nodeToTest, targetNode):
while (nodeToTest.nodeLink != None):
nodeToTest = nodeToTest.nodeLink
nodeToTest.nodeLink = targetNode
def ascendTree(leafNode, prefixPath):
if leafNode.parent != None:
prefixPath.append(leafNode.name)
ascendTree(leafNode.parent, prefixPath)
def findPrefixPath(basePat, treeNode):
condPats = {}
while treeNode != None:
prefixPath = []
ascendTree(treeNode, prefixPath)
if len(prefixPath) > 1:
condPats[frozenset(prefixPath[1:])] = treeNode.count
treeNode = treeNode.nodeLink
return condPats
def mineTree(inTree, headerTable, minSup, preFix, freqItemList):
bigL = [v[0] for v in sorted(headerTable.items(), key=lambda p: p[1])]
for basePat in bigL:
newFreqSet = preFix.copy()
newFreqSet.add(basePat)
freqItemList.append(newFreqSet)
condPattBases = findPrefixPath(basePat, headerTable[basePat][1])
myCondTree, myHead = createTree(condPattBases, minSup)
if myHead != None: #3. mine cond. FP-tree
mineTree(myCondTree, myHead, minSup, newFreqSet, freqItemList)
使用下面代码调用程序,数据集在这里mushroomLite.txt
dataSet = loadDataSet(dataDir="./mushroomLite.txt")
initSet = createInitSet(dataSet)
print(initSet)
FPtree,headerTab = createTree(initSet,3)
FPtree.disp()
输出的结果如下:

4、小结
Apriori算法和FP-Growth都是用来发现频繁项集的算法,但Apriori算法在寻找频繁项集时需要不停的扫描数据集,而FP-Growth算法只需要扫描数据集两次,因此FP-Growth算法执行速度更快,频繁项集是进行关联分析的基础,因此能够快速高效的查找频繁项集十分重要。