大数据的相关认识
大数据的相关认识

Created by Monny He ( @hemin )
目录
- 大数据的本质及相关案例
- 大数据技术
- 一个例子
大数据的本质及相关案例
- 大数据是一项专门的技术吗?
- 大数据是Hadoop吗?
- 大数据是Spark吗?
2003~2006年,谷歌公布的关于GFS、MapReduce、BigTable的技术论文奠定了大数据发展的基石,Hadoop也是参考这几篇论文而实现,而Hadoop的发展极大的推动了大数据技术的发展。
大数据是一门市场语言,代表的一种理念、一种解决问题的思路、一系列技术的集合(硬件、数据库、操作系统、Hadoop、Spark …)。
通常可以理解为具有体量巨大(Volume)处理速度较快(Velocity)、数据类型多样(Variety)以及商业价值较高(Value)等4V特点的数据。
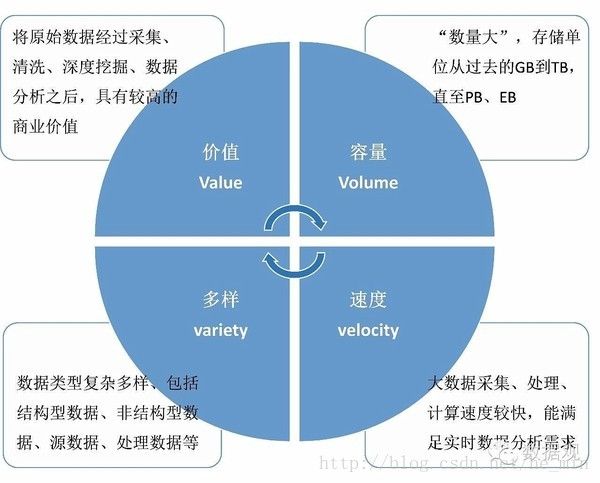
大数据与BI
BI:商业智能(Business Intelligence)
相同之处,都是从数据中挖掘出价值,促进商业成功。不同之处,分布式技术的发展,处理能力的提升,因此在对数据处理理念上也有了扩展:
- 不限于传统BI从数据中抽样建模,在回到数据仓库中。大数据可以直接从全部数据中找出规律,通过数据样本的多元化而弥补模型的准确性。
- 不限于传统BI简单的通过汇总、统计分析找出规律并输出报表,大数据可直接通过足够多的数据对个体进行刻画。
大数据的挑战
虽然大数据发展到现在有了一定的技术和商业的积累,但是仍有很多的问题,最典型的就是:
- 成本挑战:数据处理与存储需要巨大的投入,对大数据平台提出了很高的性能和成本要求。
- 实时性挑战:从广义的角度讲,随着时间的推移,数据的价值逐渐降低,时间越久,价值越低。
- 安全性挑战:从技术上讲,从在数据传输和管理的安全因素,从道德来讲,有些用户的数据是不可使用。
运营商的大数据平台架构案例
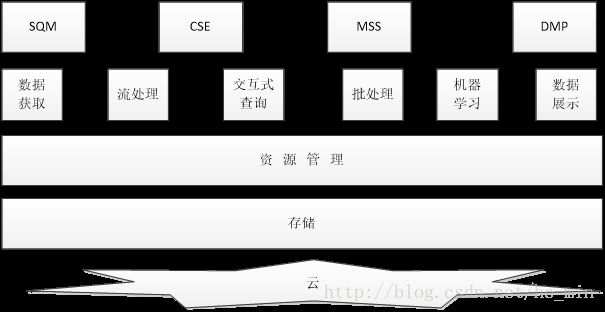
运营商常见的大数据业务:
- SQM(运维质量管理)
通过大数据技术,不仅可以收集全网的各台设备数据,而且可以收集设备原始数据。通过计算一些指标得出各个业务的质量。 - CSE(客户体验提升)
通过大数据技术,可以通过针对用户进行全方位的分析,主要是针对用户维度的业务和质量分析 - MSS(市场运维支撑)
通过数据挖掘技术,通过建模,了解到用户离网的主要原因,以便指导后期决策。 - DMP(数据管理平台)
利用大数据技术实现数据的管理与存储。
从架构图中,可以看出:
- 最上层是应用层,大数据平台最终还是要解决实际的问题。运营商案例中解决的是SQM,CSE,MSS,DMP等问题
- 第二层是各个组件、技术支撑,包括数据的产生获取、处理(流处理、批处理)、分析(机器学习,交互查询)、展现(可视化)。
- 支持数据的存储处理,需要统一的资源管理及分配。
- 上层框架和处理都建立在存储的基础上,所以存储是基础的基础
- 大数据平台的部署,有云化部署,物理机部署等多种形式。
由业务场景驱动的架构才是真正可用的架构。未来大数据分析平台的发展趋势可以总结为如下几点:
1.云优先:服务端利用云的部署和扩展能力,保证数据访问高并发,高可用,高可靠。
2.流优先:数据源更多的是流数据,要求实时分析,进行秒级或者分级运算。
大数据技术
大数据云化
云计算的定义:
- 云计算是一种按使用量付费的模式,这种模式提供可用的、便捷的、按需的网络访问,进入可配置的计算资源共享池(资源包括网络,服务器,存储,应用软件,服务),这些资源能够被快速提供,只需投入很少的管理工作,或与服务供应商进行很少的交互。
云计算包含如下几个层面的服务
- IaaS
消费者通过Internet 可以从完善的计算机基础设施获得服务。这类服务称为基础设施即服务。如存储和数据库是IaaS的一部分。 - PaaS
平台即服务。 把服务器平台作为一种服务提供的商业模式。通过网络进行程序提供的服务称之为SaaS(Software as a Service). - SaaS
它是一种通过Internet提供软件的模式,用户无需购买软件,而是向服务商租用web软件。(数加)
大数据上云
大数据在云上是一种PasS应用,提供大数据服务的公司有很多(亚马逊,阿里,腾讯,百度…)。大数据和云相结合,一般有两种模式。
1.集群模式
核心是通过云的能力简化了集群的创建、运维等。
2.服务模式
进一步简化了大数据的使用,用户不必担心集群资源这些事,只需将大数据任务提交给大数据云。
集群模式 AWSEMR
Amazon EMR是一种Web服务,让用户轻松、快速的处理大量的数据。
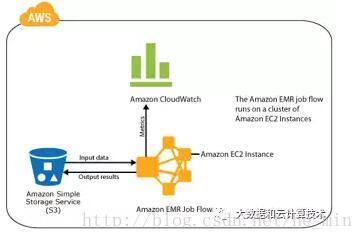
在Amazon EMR上运行的Hadoop集群使用EC2实例作为虚拟Linux服务器用于主节点和从属节点,将Amazon S3用于输入和输出数据的批量存储,并将Cloud Watch用于监控集群性能和发出警报。
AWS EMR采用存储和计算分离的架构,数据存储在S3上,计算资源来自EC2实例。集群创建之后,MapReduce通过HDFS代理调用S3接口,从S3上读取和写入数据。
Amazon EMR为集群中的服务器定义了三种角色:
1.主节点(管理集群):协调将MapReduce可执行文件和原始数据子集分配到核心实例组和任务实例组。此外,它还会跟踪每个任务的执行状态,监控实例组的运行状况。一个集群中只有一个主节点。这与Hadoop主节点映射。
2.核心节点:使用Hadoop分布式文件系统(HDFS)运行任务和存储数据。这与Hadoop从属节点映射。
3.任务节点(可选)——运行任务:这与Hadoop从属节点映射。
集群是一组执行工作的服务器。在Amazon EMR中,集群是一组以EC2实例形式运行的虚拟服务器。
通过控制台和命令行与EMR进行交互。
存储和计算分离架构,最大的好处是集群按需创建,需要时创建集群,不需要时可以释放,从而节省成本。该架构非常适合云上按需获取资源的模式。
服务模式 Data Lake
集群模式解决了大数据组件安装、运维的事情,极大的降低了大数据的使用和运维难度,但是,对于用户来说,还需要解决大数据组件知识,才能规划好集群的大小,写好代码。
服务模式就是将资源规划、扩容、缩容这些事情都省略,可以给用户提供各种API,交互界面,程序,用户只需直接提交代码或者直接使用定制的界面。
这种模式典型的例子是Data Lake,用户不必要担心各个独立的组件,Data Lake提供了所需的功能,使开发人员可以更轻松的存储任何大小、形状的数据,同时可与批量、流式、交互式分析一起运行。
这种模式是构建在集群模式的基础上,把各个服务组装在一起,提供统一的访问。服务本省提供自动弹性伸缩能力,数据自动搬迁能力。
Data Lake主要包括 Data Lake Store 和 Data Lake Analytics
Data Lake Store

Data Lake Store是一个专门的文件存储,对外提供HDFS兼容的API。Hadoop的分析工具(MapReduce/Hive)可以直接访问Data Lake Store的数据。所有数据都可以以原始数据格式存储,支持结构化和非结构化的数据存储。通过Data Lake Store提供的工具可对数据直接进行操作。
Data Lake Analytics

- 提供了SQL语句的查询,简化了查询语句
- 支持批处理、流处理
- 构建在YARN之上,自动弹性伸缩
- 集成了必要的编程工具
大数据技术
大数据存储
存储是所有大数据组件的基础,对于大数据来说,调优很大情况下等价于调存储。
存储有如下关键指标:
- 容量:决定因子是硬盘的个数和单盘的容量
- 吞吐量:决定因子是阵列架构,光纤通道和硬盘个数
- IOPS:决定因子是磁盘个数、Cache命中率和整列算法
- I/O相应时间: R=T(1−U) , T 是控制一个块所用的时间, U 是硬盘利用率
存储硬件的发展:
- 机械硬盘
- SSD
- NVDIMM
- 3D XPoint
存储接口
从接口来看,存储主要分为:
- 文件接口
- 裸设备
- 块接口
- 对象接口
块存储
HDFS是Hadoop领域纯软件实现的块接口的存储软件,是Hadoop系列的基础软件。
- HDFS原理
HDFS(Hadoop Distributed File System)是一个分布式文件系统,它具有高容错性,同时提供高吞吐量的数据访问。适合在大型数据集上使用。
- 高吞吐量
- 高容错
线性扩展
- HDFS 架构
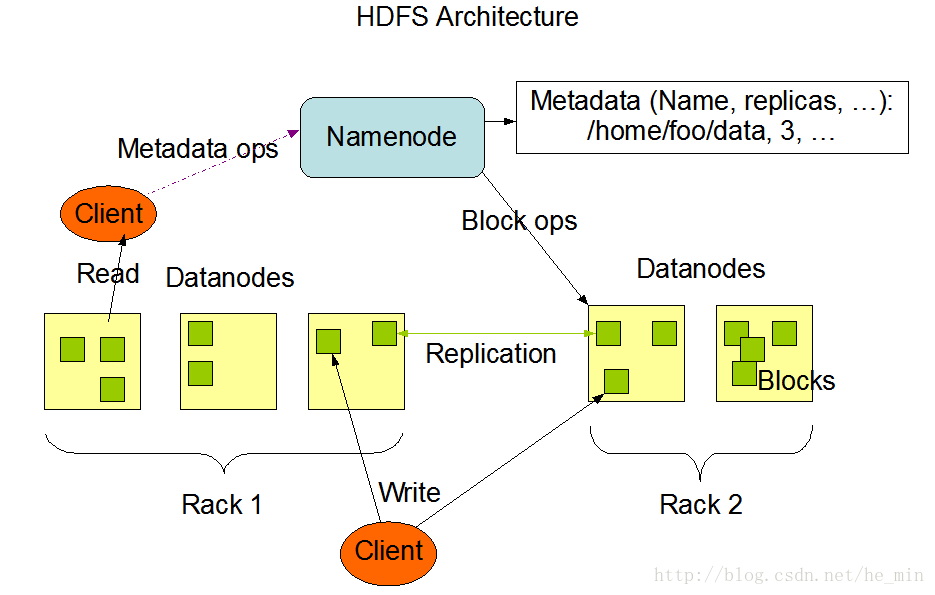
- HDFS 架构
HDFS是Maste-Slave结构,分为NameNode、SecondaryNameNode和DataNode三种角色。
- NameNode:在Hadoop1.x中只有一个Maste节点,管理HDFS的命名空间和数据映射信息和处理客户端请求。
- SecondaryNameNode:辅助NameNode,分担NameNode的工作紧急情况下辅助恢复NameNode。
- DataNode:Slave节点,实际存储数据,执行数据的读写,并汇报信息给NameNode。
HDFS的读/写操作
- 读操作
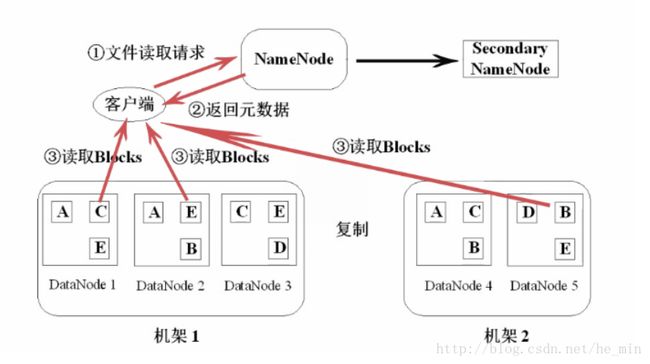
客户端发起读文件请求,向NameNode发送请求,由于NameNode存放着DataNode的信息,所以NameNode会向客户端返回元数据,这些元数据包含了数据块的信息等。客户端得到元数据后直接去读取数据块,实现了文件的读取。
- 写操作

客户端得到文件后将文件进行分块,这些分块的数据信息会写入NameNode,然NameNode会告诉客户端DataNode的情况。客户端得到这些信息后就向DataNode开始写数据,然后DataNode会以流水线方式复制,因为要保证数据有3份,这些操作完成之后会把DataNode的最新信息反馈到NameNode。
## HDFS常用的命令 1. 创建文件夹:hadoop fs -mkdir /tmp/input 2. 上传文件:hadoop fs -put input1.txt /tmp/input 3. 下载文件:hadoop fs -get input1.txt /tmp.input1.txt 4. 查看文件列表:hadoop fs -ls /tmp/input 5. 查看文件内容:hadoop fs -cat /tmp/input/input1.txt [more…](http://hadoop.apache.org/docs/r1.2.1/webhdfs.html) —
对象存储
应用场景
对象存储主要是解决数据归档和云服务两大需求:- 存储资源池(空间租赁)
向企业提供按需扩展的弹性存储资源,可以通过web来访问和使用数据,多租户模型可将不同企业的数据分离,确保安全。 - 网盘应用
- 集中备份
- 归档和分级存储
- 存储资源池(空间租赁)
2.关键特性
对象存储是一种基于对象的存储设备,具备智能、自我管理能力,通过web服务协议实现对象的读写和存储资源的访问。
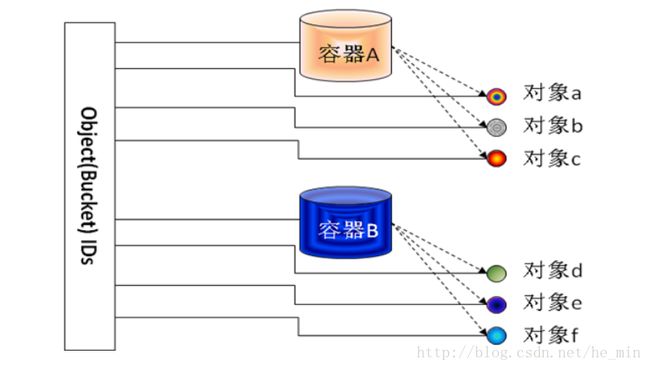
对象存储包含两种数据描述:容器、对象。容器和对象都有一个全局唯一的ID。对象存储采用扁平化结构管理所有数据,用户/应用通过接入码认证后,只需要根据ID就可以访问容器/对象及相关的数据、元数据和对象属性。
- 超强的扩展性
- 基于策略的自动化管理
- 多租户
多租户特性可以使用同一种架构,同一套系统为不同用户和应用提供存储服务,并分别为这些用户和应用设置数据保护、数据存储策略,并确保这些数据之间相互隔离。
- 数据完整性和安全性
大数据技术
资源管理
资源管理的本质是集群、数据中心级别的资源的统一管理和分配,以提高使用效率,其中,多租户、弹性伸缩、动态分配是资源管理需要解决的核心问题。
资源管理的基本概念
资源调度的目标和意义
1.子系统的高效调用
任务之间资源隔离,减少争抢。任务分配调度时结合资源分配,各个任务分配合理的资源,充分利用系统资源,减少资源利用不充分问题。资源调度结合优先级,优先级越高的可以分配越多的资源。
2.提高全系统的资源利用率
各个子系统不同时期对资源的需求不同,可以平滑系统资源的利用
3.支持动态调整切片资源,增强系统的扩展性
子系统对资源的规划很难一次性确定,通过资源调度管理系统支持动态扩展,增强系统扩展性。
### [资源调度的使用限制及难点](https://item.jd.com/12052744.html) - 实时业务受限 资源调度时为了提供资源利用率,分配本身存在一定的资源消耗,对实时性要求特别高的应用不适合 - 应用资源规划难 资源框架通过算法分配资源,但是每个细粒度的具体任务对资源的需求很难估计,规划偏大则造成浪费。 - 内存使用分配难 JVM虚拟机存在内存回收问题,上层应用程序无法控制,内存很难分配准确,内存过少则任务失败,过多则浪费。 —
Hadoop开源领域的资源调度框架
Hadoop开源领域比较有名的资源调度框架有:
- YARN
- Mesos
- Borg
- Omega
YARN
1.产生背景
(1)直接源于MapReduce1.x的缺陷:
- 扩展性受限
- 单点故障
- 难以支持MR之外的计算
(2)多计算框架之间数据共享困难
- MR:离线计算框架
- Storm:实时计算框架
- Spark:内存计算框架
2.架构
ResourceManager(RM)、NodeManager(NM)、ApplicationMaster(AM)。其中,ResourceManager负责所有资源的监控、分配和管理;ApplicationMaster负责每一个具体应用程序的调度和协调;NodeManager负责每一个节点的维护。对于所有的applications,RM拥有绝对的控制权和对资源的分配权。而每个AM则会和RM协商资源,同时和NodeManager通信来执行和监控task。


- client向RM提交应用程序,其中包括启动该应用的ApplicationMaster的必须信息,例如ApplicationMaster程序、启动ApplicationMaster的命令、用户程序等。
- ResourceManager启动一个container用于运行ApplicationMaster。
- 启动中的ApplicationMaster向ResourceManager注册自己,启动成功后与RM保持心跳。
- ApplicationMaster向ResourceManager发送请求,申请相应数目的container。
- ResourceManager返回ApplicationMaster的申请的containers信息。申请成功的container,由ApplicationMaster进行初始化。container的启动信息初始化后,AM与对应的NodeManager通信,要求NM启动container。AM与NM保持心跳,从而对NM上运行的任务进行监控和管理。
- container运行期间,ApplicationMaster对container进行监控。container通过RPC协议向对应的AM汇报自己的进度和状态等信息。
- 应用运行期间,client直接与AM通信获取应用的状态、进度更新等信息。
- 应用运行结束后,ApplicationMaster向ResourceManager注销自己,并允许属于它的container被收回。
多租户技术
多租户(Multi Tenancy/Tenant)是一种软件架构,其定义是:在一台服务器上运行单个应用实例,它为多个租户提供服务。在SaaS实施过程中,有一个显著的考量点,就是如何对应用数据进行设计,以支持多租户,而这种设计的思路,是要在数据的共享、安全隔离和性能间取得平衡。主流的方案是:
- 独立数据库
- 共享数据库、独立 Schema
- 共享数据库、共享 Schema、共享数据表
大数据技术
数据获取
数据通常情况下分为结构数据和非结构数据两种。
结构数据如DW数据,结构固定,每个字段有固定的语义和长度。
非结构化数据有文本数据,图像数据,自然语言数据等,计算机程序无法直接处理,需要进行格式转化或信息提取。
获取数据常用的方法
- 接入数据库
- 网页采集
- 日志收集
- 数据分发中间件
网页采集
如果要分析互联网上的数据,首先的把数据从网络上获取下来,这就需要网络爬虫技术。
网络爬虫是搜索引擎抓取系统的重要组成部分。主要任务是将互联网上的网页下载到本地,形成网络内容的镜像备份。

- 首先在互联网中选出一部分网页,以这些网页的链接地址作为种子URL
- 将这些种子URL放入待抓取的URL队列中,爬虫从待抓取的URL队列依次读取
- 将URL通过DNS解析
- 把链接地址转换为网站服务器对应的IP地址
- 网页下载器通过网站服务器对网页进行下载
- 下载的网页为网页文档形式
- 对网页文档中的URL进行抽取
- 过滤掉已经抓取的URL
- 对未进行抓取的URL继续循环抓取,直至待抓取URL队列为空。
其中,下载的网页文档一部分存储到页面库中,等待建立索引等后续处理,另一方面将网页中的URL存入已抓取URL库中,提供给步骤8进行过滤。
设计爬虫的时候需要掌握一些策略
- 深度优先遍历
- 广度优先遍历
- 反向连接数遍历
- PageRank策略
- 大站优先策略
一个自顶向下设计的爬虫例子

## 日志收集 Flume Flume是一个分布式、可靠、和高可用的海量日志聚合的系统,支持在系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方的能力。 —
Flume 特点:
- 可靠性
当节点出现故障时,日志能够被传送到其他节点上而不会丢失。Flume提供了三种级别的可靠性保障,从强到弱依次分别为:end-to-end(收到数据agent首先将event写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送。),Store on failure(这也是scribe采用的策略,当数据接收方crash时,将数据写到本地,待恢复后,继续发送),Best effort(数据发送到接收方后,不会进行确认)。
- 可扩展性
Flume采用了三层架构,分别为agent,collector和storage,每一层均可以水平扩展。其中,所有agent和collector由master统一管理,这使得系统容易监控和维护,且master允许有多个,这就避免了单点故障问题。
- 可管理性
所有agent和colletor由master统一管理,这使得系统便于维护。多master情况,Flume利用ZooKeeper,保证动态配置数据的一致性。用户可以在master上查看各个数据源或者数据流执行情况,且可以对各个数据源配置和动态加载。Flume提供了web 和shell script command两种形式对数据流进行管理。
- 功能可扩展性
用户可以根据需要添加自己的agent,collector或者storage。此外,Flume自带了很多组件,包括各种agent(file, syslog等),collector和storage(file,HDFS等)。
Flume的架构图:
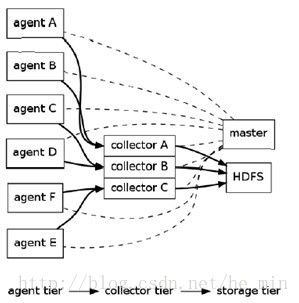
Flume采用了分层架构:分别为agent,collector和storage。其中,agent和collector均由两部分组成:source和sink,source是数据来源,sink是数据去向。

Flume使用两个组件:Master和Node,Node根据在Master shell或web中动态配置,决定其是作为Agent还是Collector。
- Agent: 使用JVM 运行Flume。每台机器运行一个agent,主要将数据源发送给Collector
- Collector:将多个agent的数据汇总后加载到Storage
- Source:从Client收集数据,传递给Channel
- Sink:从Channel收集数据,运行在一个独立线程。
- Channel:连接 sources 和 sinks ,这个有点像一个队列。
- Events:可以是日志记录等。
more…
Flume 部署流程
$wget http://cloud.github.com/downloads/
cloudera/flume/flume-distribution-0.9.4-bin.tar.gz
$tar -xzvf flume-distribution-0.9.4-bin.tar.gz
$cp -rf flume-distribution-0.9.4-bin /usr/local/flume
$vi /etc/profile #添加环境配置
export FLUME_HOME=/usr/local/flume
export PATH=.:$PATH::$FLUME_HOME/bin
$source /etc/profile
$flume #验证安装数据分发中间件 kafka
为什么需要数据分发中间件?
数据采集上来之后,需要传送到后端进行进一步的分析,前端的采集和后端的处理往往是多对多的关系。为了简化传送逻辑,增强灵活性,在前端的采集和后端的处理之间需要一个消息中间件负责消息转发,以保障消息的可靠性,匹配前后段的速度差。
在大数据系统中,常常会碰到一个问题,整个大数据是由各个子系统组成,数据需要在各个子系统中高性能,低延迟的不停流转。传统的企业消息系统并不是非常适合大规模的数据处理。为了已在同时搞定在线应用(消息)和离线应用(数据文件,日志)Kafka就出现了。Kafka可以起到两个作用:
- 降低系统组网复杂度。
- 降低编程复杂度,各个子系统不在是相互协商接口,各个子系统类似插口插在插座上,Kafka承担高速数据总线的作用。
kafka架构图

Kafka的整体架构非常简单,是显式分布式架构,producer、broker(kafka)和consumer都可以有多个。Producer,consumer实现Kafka注册的接口,数据从producer发送到broker,broker承担一个中间缓存和分发的作用。broker分发注册到系统中的consumer。broker的作用类似于缓存,即活跃的数据和离线处理系统之间的缓存。
- Topic:特指Kafka处理的消息源的不同分类。
- Partition:Topic物理上的分组
- Producers:消息和数据生产者
- Consumers:消息和数据消费者
- Broker:缓存代理,为Kafa集群中的一台或多台服务器统。

- Producer根据指定的partition方法(round-robin、hash等),将消息发布到指定topic的partition里面
- kafka集群接收到Producer发过来的消息后,将其持久化到硬盘,并保留消息指定时长,而不关注消息是否被消费。
Consumer从kafka集群pull数据,并控制获取消息的offset
Apache Kafka网站
- 项目设计讨论
- Github镜像
- Morten Kjetland对Apache Kafka的介绍
- Quora上与RabbitMQ的对比
- Kafka: a Distributed Messaging System for Log Processing
- Zero-copy原理
- Kafka与Hadoop
大数据技术
流处理
流是一种数据传送技术,它把客户机收到的数据变成稳定连续的流,源源不断的送出。正是由于数据传送呈持续不停的状态,因此流引擎需要持续不断地的处理数据。通常有两种方式处理流,一种是一个消息传送过来,立即处理,另一种是以较小的Batch模拟流处理。
流处理的应用场景
- 金融业
- 电信运营商
- 能源行业
- 电子商务
- 运输行业
- ….
Spark Streming
Spark Streaming 是Spark核心API的一个扩展,可以实现高吞吐量的、具备容错机制的实时流数据的处理。支持从多种数据源获取数据,包括Kafk、Flume、Twitter以及TCP sockets,从数据源获取数据之后,可以使用诸如map、reduce、join和window等高级函数进行复杂算法的处理。最后还可以将处理结果存储到文件系统,数据库和现场仪表盘。还可以使用Spark的其他子框架,如集群学习、图计算等,对流数据进行处理。
Spark Streaming处理的数据流图:

Spark Streaming在内部的处理机制是,接收实时流的数据,并根据一定的时间间隔拆分成一批批的数据,然后通过Spark Engine处理这些批数据,最终得到处理后的一批批结果数据。流数据分成一批一批后,通过一个先进先出的队列,然后 Spark Engine从该队列中依次取出一个个批数据,把批数据封装成一个RDD,然后进行处理。
实时性,会牵涉到流式处理框架的应用场景。Spark Streaming将流式计算分解成多个Spark Job,对于每一段数据的处理都会经过Spark图分解,以及Spark的任务集的调度过程。对于目前版本的Spark Streaming而言,其最小的Batch Size的选取在0.5~2秒钟之间(Storm目前最小的延迟是100ms左右),所以Spark Streaming能够满足除对实时性要求非常高之外的所有流式准实时计算场景。
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
sc = SparkContext("local[2]", "NetworkWordCount")
ssc = StreamingContext(sc, 1)
lines = ssc.socketTextStream("localhost", 9999)
words = lines.flatMap(lambda line: line.split(" "))
pairs = words.map(lambda word: (word, 1))
wordCounts = pairs.reduceByKey(lambda x, y: x + y)
wordCounts.pprint()
ssc.start()
ssc.awaitTermination() 大数据技术
批处理
批处理技术,发展最早,应用也最广泛,定义为:
工作在面对复杂的业务以及海量的数据处理时,无需人工干预,仅需要定期读入批量数据,然后完成相应业务处理并进行归档操作。
一个典型的批处理场景:
系统A从数据库获取数据,进过业务处理后,导出系统B所需要的数据到文件中,系统B读取文件数据,进过业务处理后,最后存放在数据库中,通常情况下该批处理动作在每天晚上12点至2点执行。
## [features](http://blog.csdn.net/u011659172/article/details/50730554) 批处理的工作特点: 1.自动执行–根据系统设定的工作步骤自动完成 2.数据量大–少则百万,多则千万甚至上亿 3.定时执行–每天/每周每月执行 批处理流程: 1.读数据–数据可能来自文件、数据库或消息队列等; 2.处理数据–处理读取的数据并形成输出的结果; 3.写数据–将输出结果写入文件、数据库、消息队列等。 — ## MapReduce编程框架 MapReduce 是现今一个非常流行的分布式计算框架,它被设计用于并行计算海量数据。MapReduce 框架的核心步骤主要分两部分:Map 和Reduce。当你向MapReduce框架提交一个计算作业时,它会首先把计算作业拆分成若干个Map 任务,然后分配到不同的节点上去执行,每一个Map 任务处理输入数据中的一部分,当Map 任务完成后,它会生成一些中间文件,这些中间文件将会作为Reduce 任务的输入数据。Reduce 任务的主要目标就是把前面若干个Map 的输出汇总到一起并输出。 —  —  — ## Map 1. 每个输入分片会让一个map任务来处理,默认情况下,以HDFS的一个块的大小为一个分片。map输出的结果会暂且放在一个环形内存缓冲区中,当该缓冲区快要溢出时,会在本地文件系统中创建一个溢出文件,将该缓冲区中的数据写入这个文件; 2. 在写入磁盘之前,线程首先根据reduce任务的数目将数据划分为相同数目的分区,也就是一个reduce任务对应一个分区的数据。其实分区就是对数据进行hash的过程。然后对每个分区中的数据进行排序。 3. 当map任务输出最后一个记录时,可能会有很多的溢出文件,这时需要将这些文件合并。 4. 将分区中的数据拷贝给相对应的reduce任务。JobTracker中保存了整个集群中的宏观信息。只要reduce任务向JobTracker获取对应的map输出位置就可以了。 —
Reduce
Reduce会接收到不同map任务传来的数据,并且每个map传来的数据都是有序的。如果reduce端接受的数据量相当小,则直接存储在内存中,如果数据量超过了该缓冲区大小的一定比例,则对数据合并后溢写到磁盘中;
随着溢写文件的增多,后台线程会将它们合并成一个更大的有序的文件,这样做是为了给后面的合并节省时间。
MapReduce会让写入磁盘的数据尽可能地少,并且最后一次合并的结果并没有写入磁盘,而是直接输入到reduce函数。

在集群中的任意一个节点提交MapReduce程序;
JobClient收到作业后,JobClient向JobTracker请求一个Job ID;
将运行作业所需要的资源文件复制到HDFS上文件夹名为该作业的Job ID;
获得作业ID后,提交作业
JobTracker接收到作业后,将其放在一个作业队列里,等待作业调度器对其进行调度
将程序JAR包复制到该TaskTracker上来运行,这叫移动计算
TaskTracker每隔一段时间会给JobTracker发送一个心跳
运行的TaskTracker从HDFS中获取运行所需要的资源
TaskTracker获取资源后启动新的JVM虚拟机;
Hadoop部署级实战
缺点:
- Map阶段产生的中间结果需要写到磁盘上,以保障系统的可靠性,代价是降低了系统性能。
- Shuffle阶段采用了HTTP协议将各个MapTask上复制结果,导致系统性能下降。
Spark
Hadoop由于频繁的读写磁盘而导致了性能的下降,Spark则利用内存的容量一直在增加,价格一直在下降的优势提出基于内存的分布式处理软件。
其愿景是做一款全能软件,可以统一批处理,交互式处理,流处理等场景,降低开发和运维的难度。
Spark和Hadoop的对比:
- spark将数据放在内存中,对于迭代计算而言,效率更高
- spark更适合迭代计算比较多的机器学习算法
- spark比Hadoop更加通用
- spark的数据操作类型更多
- spark提供跟多的接口与交互方式
Spark运行流程

- 构建Spark Application的运行环境,SparkContext向资源管理器注册并申请运行Executor资源;
- 资源管理器分配Executor资源并启动StandaloneExecutorBackend,Executor运行情况将随着心跳发送到资源管理器上;
- SparkContext构建成DAG图,将DAG图分解成Stage,并把Taskset发送给Task Scheduler。Executor向SparkContext申请Task,Task Scheduler将Task发放给Executor运行同时SparkContext将应用程序代码发放给Executor。
- Task在Executor上运行,运行完毕释放所有资源。
其他内容
- spark相关术语定义
- DAGScheduler
- TaskScheduler
- RDD运行原理
- Spark on YARN运行过程
大数据技术
机器学习/数据挖掘
机器学习是一门多领域交叉的学科,涉及概率论,统计学,逼近论,凸优化,算法复杂度分析等知识,主要研究计算机如何模拟人的行为以获取跟多的知识或技能,重新组织已有的知识结构,使其不断的改善自身性能。
数据挖掘需要利用除机器学习之外的很多技术来解决数据噪音,数据规模,数据仓储问题
数据挖掘是从目的出发的,机器学习则是从方法出发的,两者有很大的交叉,但不相同。
数据挖掘/机器学习流程:
- 业务的理解
- 数据的理解
- 数据预处理
- 特征提取
- 模型构建
- 模型评估
- 模型应用
机器学习概览
- 学习方式
- 算法类似性
学习方式
- 监督式学习
- 非监督式学习
- 半监督式学习
- 强化学习
- 回归算法
- 基于实例的算法
- 正则化方法
- 决策树学习
- 贝叶斯方法
- 基于核的算法
- 聚类算法
- 关联规则学习
- 人工神经网络
- 深度学习
- 降低维度算法
- 集成算法
## 机器学习应用场景
## 深度学习 [tensorflow on spark](http://www.jianshu.com/p/62b4ebb5a2f4) [caffe on spark](http://blog.csdn.net/sadonmyown/article/details/72781393) 目前的深度学习框架基本都只专注于深度学习,但深度学习需要大量的数据,上述框架能够和大数据平台结合在一起,以减少大数据/深度学习平台的系统和流程的复杂性,也减少多个集群之间不必要的数据传输带来的性能瓶颈和低效。 — ## 大数据展示 [echart](www.echart.com): 1. 开源软件,提供了非常炫酷的图形界面,特色是地图,另外还提供了柱状图、折线图、饼图、气泡图及四象限图等; 2. 使用简单,封装了js,只要会引用就会得到完美的展示效果; 3. 种类多,echarts实现简单,各类图形都有,相应的模板,还有API及文档说明,非常详细; 4. 兼容性好,基于html5,有着良好的动画渲染效果。 —
option = {
angleAxis: {
type: 'category',
data: ['周一', '周二', '周三', '周四',
'周五', '周六', '周日'],
z: 10
},
radiusAxis: {
},
polar: {
},
series: [{
type: 'bar',
data: [1, 2, 3, 4, 3, 5, 1],
coordinateSystem: 'polar',
name: 'A',
stack: 'a'
}],
legend: {
show: true,
data: ['A', 'B', 'C']
}
};D3.js
D3 的全称是(Data-Driven Documents),顾名思义可以知道是一个被数据驱动的文档。听名字有点抽象,说简单一点,其实就是一个 JavaScript 的函数库,使用它主要是用来做数据可视化的。
var rand = d3.random.normal(0,25);
var dataset = [];
for(var i=0;i<100;i++){
dataset.push( rand() );
}
var bin_num = 15;
var histogram = d3.layout.histogram()
.range([-50,50])
.bins(bin_num)
.frequency(true);
R
调用R脚本在服务端生成图片,随后嵌入前端指定的位置。
一个简单的大数据平台例子
项目简介:
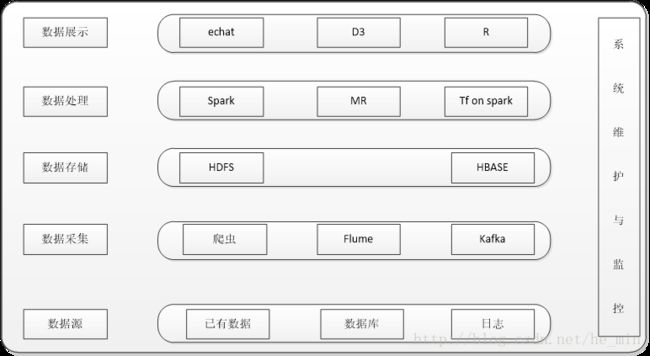
项目数据主要来源于已有的数据或者通过其他途径得到的数据,将数据保存到HDFS或者mysql中,通过Sqoop导入到mysql中,然后使用spark或者mapreduce进行处理,处理后的数据导入到Hive、Hbase,最后使用java、R、spark等工具进行展示与分析。其中的问题包括,设计,开发,调试,问题定位以及处理,版本管理等。
项目架构:
使用的技术都是开源的,如Hadoop、Hive、Spark、R、OpenStack、Mysql等总体架构如图所示:
参考