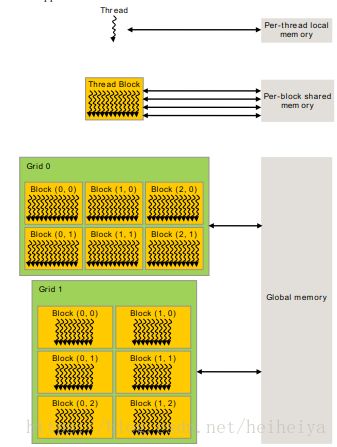
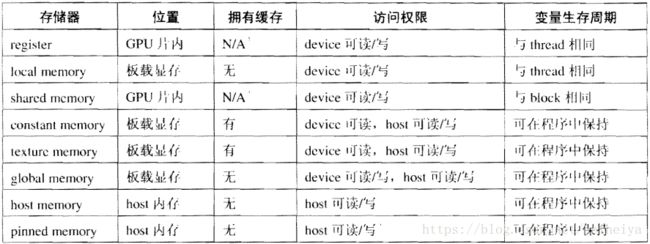
- 【pytorch(cuda)】基于DQN算法的无人机三维城市空间航线规划(Python代码实现)
wlz249
pythonpytorch算法
欢迎来到本博客❤️❤️博主优势:博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。⛳️座右铭:行百里者,半于九十。本文目录如下:目录⛳️赠与读者1概述一、研究背景与意义二、DQN算法概述三、基于DQN的无人机三维航线规划方法1.环境建模2.状态与动作定义3.奖励函数设计4.深度神经网络训练5.航线规划四、研究挑战与展望2运行结果3参考文献4Python代码实现⛳️赠与读者做科研,涉及到一个深在的
- 【保姆级视频教程(一)】YOLOv12环境配置:从零到一,手把手保姆级教程!| 小白也能轻松玩转目标检测!
一只云卷云舒
YOLOv12保姆级通关教程YOLOYOLOv12flashattentionGPU计算能力算力
【2025全站首发】YOLOv12环境配置:从零到一,手把手保姆级教程!|小白也能轻松玩转目标检测!文章目录1.FlashAttentionWindows端WHL包下载1.1简介1.2下载链接1.3国内镜像站1.4安装方法2.NVIDIAGPU计算能力概述2.1简介2.2计算能力版本与GPU型号对照表2.2.1CUDA-EnabledDatacenterProducts2.2.2CUDA-Enab
- LLaMA-Factory 微调训练
zsh_abc
llamadocker深度学习人工智能pythonlinux
LLaMA-Factory微调训练该框架功能,标注-微调-导出-合并-部署,一整条流程都有,而且训练时消耗的gpu算力也会小一些一,安装(推荐在linux中训练,win可以用wsl+docker)gitclonehttps://github.com/hiyouga/LLaMA-Factory.gitcdLLaMA-Factory#根据cuda版本选择安装pytoch版本pip3installtor
- llama-factory微调
AI Echoes
深度学习人工智能机器学习deepseek
大模型微调实操--llama-factoryllama-factory环境安装前置准备英伟达显卡驱动更新地址下载NVIDIA官方驱动|NVIDIAcuda下载安装地址CUDAToolkit12.2Downloads|NVIDIADeveloperpytorch下载安装地址PreviousPyTorchVersions|PyTorchllama-factory项目和文档地址https://githu
- PyTorch 生态概览:为什么选择动态计算图框架?
小诸葛IT课堂
pytorch人工智能python
一、PyTorch的核心价值PyTorch作为深度学习框架的后起之秀,通过动态计算图技术革新了传统的静态图模式。其核心优势体现在:动态灵活性:代码即模型,支持即时调试Python原生支持:无缝衔接Python生态高效的GPU加速:通过CUDA实现透明的硬件加速活跃的社区生态:GitHub贡献者超1.8万人,日均更新100+次二、动态计算图VS静态计算图对比#动态计算图示例(PyTorch)impo
- unitree
Matrixart
ubuntu
Unitreeubuntu18.04首先要安装好ubuntu18.04系统,然后开始安装显卡驱动和cuda以及cudnn,这里要注意版本对应,我是3090的显卡,安装的显卡版本是520,然后cuda的版本是11.7,cudnn的版本是8.5.0(要对应cuda版本)。具体流程可以按照1里面的走,最后记得在环境中写一下#写入环境sudogedit~/.bashrcexportPATH=/usr/lo
- LVI-SAM、VINS-Mono、LIO-SAM算法的阅读参考和m2dgr数据集上的复现(留作学习使用)
再坚持一下!!!
学习
ROS一键安装参考:ROS的最简单安装——鱼香一键安装_鱼香ros一键安装-CSDN博客opencv官网下载4.2.0参考:https://opencv.org/releases/page/3/nvidia驱动安装:ubuntu18.04安装显卡驱动-开始战斗-博客园cuda搭配使用1+2cuda安装1:Ubuntu18.04下安装CUDA_ubuntu18.04安装cuda-CSDN博客cuda
- 如何使用MATLAB进行高效的GPU加速深度学习模型训练?
百态老人
matlab深度学习开发语言
要使用MATLAB进行高效的GPU加速深度学习模型训练,可以遵循以下步骤和策略:选择合适的GPU硬件:首先,确保您的计算机配备有支持CUDA的NVIDIAGPU,并且其计算能力至少为3.0或以上。可以通过gpuDevice命令检查GPU是否具备加速功能。安装必要的工具箱:确保安装了MATLAB的DeepLearningToolbox和ParallelComputingToolbox,这些工具箱提供
- Matlab GPU加速技术
算法工程师y
matlab开发语言
1.GPU加速简介(1)为什么使用GPU加速?CPU擅长处理逻辑复杂的串行任务,而GPU拥有数千个流处理器,专为并行计算设计。对于大规模矩阵运算、深度学习训练或科学计算等任务,GPU加速可将计算速度提升数十至数百倍。(2)Matlab的GPU支持功能依赖:需安装ParallelComputingToolbox(并行计算工具箱)。硬件要求:支持CUDA的NVIDIAGPU(如Tesla、GeForc
- pytorch 天花板级别的知识点 你可以不会用 但是不能不知道
小赖同学啊
人工智能pytorch人工智能python
PyTorch的高级知识涵盖了从模型优化到分布式训练的广泛内容,适合已经掌握基础知识的开发者进一步提升技能。以下是PyTorch的高级知识点,详细且全面:1.模型优化与加速1.1混合精度训练定义:使用半精度(FP16)和单精度(FP32)混合训练,减少内存占用并加速计算。实现:使用torch.cuda.amp模块。示例:fromtorch.cuda.ampimportautocast,GradSc
- vllm部署说明和注意事项
ai一小生
python人工智能持续部署
1、vllm所在docker镜像可去vllm官网提供的镜像地址拉取地址:UsingDocker—vLLMVllm镜像运行需要不同的cuda版本依赖,如上vllm/vllm-openai:v0.7.2需要cuda12.1方可运行。DeepSeek-R1-Distill-Qwen-32B可去modelscope下载:整体大小约为60GB部署DeepSeek-R1-Distill-Qwen-32B模型,
- CUDA内核调优工具ncu的详细使用教程
东北豆子哥
CUDA数值计算/数值优化linux高性能计算
NVIDIANsightCompute(ncu)是一款用于CUDA内核性能分析的工具,帮助开发者优化CUDA程序。以下是详细的使用教程和示例说明。1.安装NVIDIANsightCompute确保已安装CUDAToolkit和NVIDIA驱动,然后从NVIDIA官网下载并安装NsightCompute。2.基本使用2.1启动ncu通过命令行启动ncu,基本语法如下:ncu[options][app
- 麒麟银河桌面版,成功安装cuda12.6,mysql
hitsz_syl
mysql银河麒麟cuda
一、要卸载并禁用nouveau驱动程序,可以按照以下步骤进行:1.确认nouveau驱动的当前状态:首先,你可以使用以下命令查看nouveau驱动是否正在运行:lsmod|grepnouveau如果有输出,说明nouveau驱动正在加载。2.临时禁用nouveau驱动:可以使用modprobe命令来临时禁用nouveau驱动(重启后会恢复加载):sudomodprobe-rnouveau3.永久禁
- mysql创建新表,同步数据
hitsz_syl
mysql数据库
importosimportargparseimportglobimportcv2importnumpyasnpimportonnxruntimeimporttqdmimportpymysqlimporttimeimportjsonfromdatetimeimportdatetimeos.environ[“CUDA_VISIBLE_DEVICES”]=“0”#使用GPU0defget_connec
- 如何测试模型的推理速度
想要躺平的一枚
AI图像算法计算机视觉
前言模型的推理速度测试有两种方式:一种是使用python的时间戳time函数来记录,另一种是使用Pytorch里的Event。同时,在进行GPU测试时,为减少冷启动的状态影响,可以先进行预热。代码如下(示例):if__name__=="__main__":model=BiSeNet(backbone='STDCNet813',n_classes=2,export=True)model.cuda()
- NVIDIA下载老版本驱动/CUDA/Video Codec SDK的链接,以及一些解码参数说明
landihao
linux
NVIDIA下载老版本驱动/CUDA/VideoCodecSDK的链接从别的网站抄过来的CUDA:https://developer.nvidia.com/cuda-toolkit-archive老驱动:https://www.nvidia.cn/geforce/drivers/VideoCodecSDKhttps://developer.nvidia.com/video-codec-sdk-ar
- PyTorch 环境搭建全攻略:CUDA/cuDNN 配置与多版本管理技巧
小诸葛IT课堂
pytorch人工智能python
一、环境搭建前的准备工作1.硬件兼容性检测#检查NVIDIAGPU型号nvidia-smi#验证CUDA支持的ComputeCapabilitylspci|grep-invidia#查看CUDA版本兼容性矩阵https://developer.nvidia.com/cuda-gpus2.系统环境要求组件推荐配置最低要求操作系统Ubuntu20.04LTSWindows10/11显卡驱动NVIDIA
- CMake Error at myplugins_generated_yololayer.cu.o.Debug,tensorrtx编译失败解决
雪可问春风
BUG人工智能
system:ubuntu1804gpu:3060cuda:cuda11.4tensorrt:8.4使用项目tensorrtx进行yolov5的engine生成,之前在编译成功的配置为system:ubuntu1804gpu:2060cuda:cuda10.2tensorrt:7.2.3.4换到3060后,make失败,报错错误:/home/yfzx/work/vs-work/tensorrt-y
- 大模型的webui
Zain Lau
人工智能python昇腾Ascend天数
exportXXX_LLM_C=~/xcore-llm/build/ReleaseexportCUDA_VISIBLE_DEVICES=2,3exportCUDACXX=/usr/local/cuda-12.3/bin/nvccnohup/usr/bin/python3/home/src/api_server/api_server.py--modelLLama2:7b-chat-hf_A800--
- linux(ubuntu)中Conda、CUDA安装Xinference报错ERROR: Failed to build (llama-cpp-python)
小胡说技书
杂谈/设计模式/报错Data/Python/大模型linuxubuntuconda大模型pythonXinference
文章目录一、常规办法二、继续三、继续四、缺少libgomp库(最终解决)在Conda环境中安装libgomp如果符合标题情况执行的:pipinstall"xinference[all]"大概率是最终解决的情况。一、常规办法llama-cpp-python依赖CMake、Make和g++来编译,所以可能是缺少依赖或者环境配置不对。按照以下步骤排查问题并解决:1.确保Python版本符合要求llama
- c++调用python代码,使用gpu
AI改变视界
c++python开发语言
c++调用python,使用gpu加速1、首先要配置cuda和cudnn的环境1、cmd窗口下nvidia-smi,查看电脑可以支持的最高cuda版本。如果nvidia-smi报错,那么需要去配置一下环境,网上有类似案例。或者通过NVIDIA控制面板/系统信息/组件里查看cuda_xxxx.dll,上面有版本号。2、保证安装的cuda版本要小于电脑支持的版本号。我电脑最大支持cuda11,但是安装
- 一文讲清楚CUDA与PyTorch、GPU之间的关系
平凡而伟大.
编程语言人工智能架构设计pytorch人工智能python
CUDA(ComputeUnifiedDeviceArchitecture)是由NVIDIA开发的一个并行计算平台和编程模型。它允许软件开发人员和研究人员利用NVIDIA的GPU(图形处理单元)进行高性能计算。CUDA提供了一系列API和工具,使得开发者能够编写和优化在GPU上运行的计算密集型任务。CUDA与PyTorch、GPU之间的关系可以这样理解:1.CUDA与GPU:GPU:是一种专门用于
- 深度学习-服务器训练SparseDrive过程记录
weixin_40826634
深度学习服务器人工智能
1、cuda安装1.1卸载安装失败的cuda参考:https://blog.csdn.net/weixin_40826634/article/details/127493809注意:因为/usr/local/cuda-xx.x/bin/下没有卸载脚本,很可能是apt安装的,所以通过执行下面的命令删除:apt-get--purgeremove"cuda*"apt-getautoremove然后执行f
- RTX4090性能释放与优化全攻略
智能计算研究中心
其他
内容概要作为NVIDIAAdaLovelace架构的巅峰之作,RTX4090凭借24GBGDDR6X显存与16384个CUDA核心,重新定义了4K光追游戏的性能边界。本文将从硬件特性与软件优化双重视角切入,系统解析其性能释放路径:首先通过3DMarkTimeSpyExtreme压力测试数据(99.3%稳定性得分)验证基础算力;其次结合DLSS3.0帧生成技术与Reflex低延迟模式,实测《赛博朋克
- 嵌入式人工智能应用- 第七章 人脸识别
数贾电子科技
嵌入式人工智能应用人工智能
嵌入式人工智能应用`文章目录嵌入式人工智能应用1人脸识别1.1dlib介绍1.2dlib特点1.3dlib的安装与编译2人脸识别原理2.1ResNet3代码部署3.1安装[CUDAToolkit12.8](https://developer.nvidia.com/cuda-downloads?target_os=Linux&target_arch=x86_64&Distribution=Ubunt
- 英伟达的ptx是什么?ptx在接近汇编语言的层级运行?
AI-AIGC-7744423
人工智能
PTX(ParallelThreadeXecution)是英伟达CUDA架构中的一种中间表示形式(IR)语言。以下是关于它的介绍以及它与汇编语言层级关系的说明:PTX介绍•性质与作用:PTX是一种类似于汇编语言的指令集架构,但它更像是一种抽象的、面向并行计算的中间语言。它是CUDA编程模型中,主机代码与实际在GPU上执行的机器码之间的桥梁。开发者编写的CUDAC/C++等高级语言代码,在编译过程中
- 保姆级教学——本地免费部署DeepSeek-R1模型并通过Python调用
shuaige_shiwoa
python+AIpython开发语言AI编程ai
以下是如何在本地免费部署DeepSeek-R1模型并通过Python调用的详细指南:一、环境准备(Windows/Linux/Mac通用)1.硬件要求最低配置:16GB内存+20GB可用磁盘空间推荐配置:NVIDIAGPU(显存≥8GB)+CUDA11.8(CPU模式支持但速度较慢)2.软件依赖#创建虚拟环境(可选但推荐)condacreate-ndeepseekpython=3.10condaa
- Python深度学习033:Python、PyTorch、CUDA和显卡驱动之间的关系
若北辰
Python深度学习python深度学习pytorch
Python、PyTorch、CUDA和显卡驱动之间的关系相当紧密,它们共同构成了一个能够执行深度学习模型的高效计算环境。下面是它们之间关系的简要概述:PythonPython是一种编程语言,广泛用于科学计算、数据分析和机器学习。它是开发和运行PyTorch代码的基础环境。PyTorchPyTorch是一个开源的机器学习库,用于应用如自然语言处理和计算机视觉的深度学习模型。它提供了丰富的API,使
- 查看自己某个conda环境的Python版本的方法
小剧场的阿刁
condapythonwindows
首先打开conda的命令行输入:condaenvlist1查看自己有哪些环境。再输入:activateCUDA90_torch110_tf1901激活环境。再输入:python-V#注意V是大写1
- 本地部署时,如何通过硬件加速(如 CUDA、TensorRT)提升 DeepSeek 的推理性能?不同显卡型号的兼容性如何测试?
百态老人
人工智能科技算法vscode
本地部署DeepSeek模型的硬件加速优化与显卡兼容性测试指南一、硬件加速技术实现路径CUDA基础环境搭建版本匹配原则:根据显卡架构选择CUDA版本(如NVIDIARTX50系列需CUDA12+,V100需CUDA11.x),并通过nvcc--version验证安装。GPU加速验证:运行以下代码检查硬件加速状态:importtensorflowastfprint("可用GPU数量:",len(tf
- 对于规范和实现,你会混淆吗?
yangshangchuan
HotSpot
昨晚和朋友聊天,喝了点咖啡,由于我经常喝茶,很长时间没喝咖啡了,所以失眠了,于是起床读JVM规范,读完后在朋友圈发了一条信息:
JVM Run-Time Data Areas:The Java Virtual Machine defines various run-time data areas that are used during execution of a program. So
- android 网络
百合不是茶
网络
android的网络编程和java的一样没什么好分析的都是一些死的照着写就可以了,所以记录下来 方便查找 , 服务器使用的是TomCat
服务器代码; servlet的使用需要在xml中注册
package servlet;
import java.io.IOException;
import java.util.Arr
- [读书笔记]读法拉第传
comsci
读书笔记
1831年的时候,一年可以赚到1000英镑的人..应该很少的...
要成为一个科学家,没有足够的资金支持,很多实验都无法完成
但是当钱赚够了以后....就不能够一直在商业和市场中徘徊......
- 随机数的产生
沐刃青蛟
随机数
c++中阐述随机数的方法有两种:
一是产生假随机数(不管操作多少次,所产生的数都不会改变)
这类随机数是使用了默认的种子值产生的,所以每次都是一样的。
//默认种子
for (int i = 0; i < 5; i++)
{
cout<<
- PHP检测函数所在的文件名
IT独行者
PHP函数
很简单的功能,用到PHP中的反射机制,具体使用的是ReflectionFunction类,可以获取指定函数所在PHP脚本中的具体位置。 创建引用脚本。
代码:
[php]
view plain
copy
// Filename: functions.php
<?php&nbs
- 银行各系统功能简介
文强chu
金融
银行各系统功能简介 业务系统 核心业务系统 业务功能包括:总账管理、卡系统管理、客户信息管理、额度控管、存款、贷款、资金业务、国际结算、支付结算、对外接口等 清分清算系统 以清算日期为准,将账务类交易、非账务类交易的手续费、代理费、网络服务费等相关费用,按费用类型计算应收、应付金额,经过清算人员确认后上送核心系统完成结算的过程 国际结算系
- Python学习1(pip django 安装以及第一个project)
小桔子
pythondjangopip
最近开始学习python,要安装个pip的工具。听说这个工具很强大,安装了它,在安装第三方工具的话so easy!然后也下载了,按照别人给的教程开始安装,奶奶的怎么也安装不上!
第一步:官方下载pip-1.5.6.tar.gz, https://pypi.python.org/pypi/pip easy!
第二部:解压这个压缩文件,会看到一个setup.p
- php 数组
aichenglong
PHP排序数组循环多维数组
1 php中的创建数组
$product = array('tires','oil','spark');//array()实际上是语言结构而不 是函数
2 如果需要创建一个升序的排列的数字保存在一个数组中,可以使用range()函数来自动创建数组
$numbers=range(1,10)//1 2 3 4 5 6 7 8 9 10
$numbers=range(1,10,
- 安装python2.7
AILIKES
python
安装python2.7
1、下载可从 http://www.python.org/进行下载#wget https://www.python.org/ftp/python/2.7.10/Python-2.7.10.tgz
2、复制解压
#mkdir -p /opt/usr/python
#cp /opt/soft/Python-2
- java异常的处理探讨
百合不是茶
JAVA异常
//java异常
/*
1,了解java 中的异常处理机制,有三种操作
a,声明异常
b,抛出异常
c,捕获异常
2,学会使用try-catch-finally来处理异常
3,学会如何声明异常和抛出异常
4,学会创建自己的异常
*/
//2,学会使用try-catch-finally来处理异常
- getElementsByName实例
bijian1013
element
实例1:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/x
- 探索JUnit4扩展:Runner
bijian1013
java单元测试JUnit
参加敏捷培训时,教练提到Junit4的Runner和Rule,于是特上网查一下,发现很多都讲的太理论,或者是举的例子实在是太牵强。多搜索了几下,搜索到两篇我觉得写的非常好的文章。
文章地址:http://www.blogjava.net/jiangshachina/archive/20
- [MongoDB学习笔记二]MongoDB副本集
bit1129
mongodb
1. 副本集的特性
1)一台主服务器(Primary),多台从服务器(Secondary)
2)Primary挂了之后,从服务器自动完成从它们之中选举一台服务器作为主服务器,继续工作,这就解决了单点故障,因此,在这种情况下,MongoDB集群能够继续工作
3)挂了的主服务器恢复到集群中只能以Secondary服务器的角色加入进来
2
- 【Spark八十一】Hive in the spark assembly
bit1129
assembly
Spark SQL supports most commonly used features of HiveQL. However, different HiveQL statements are executed in different manners:
1. DDL statements (e.g. CREATE TABLE, DROP TABLE, etc.)
- Nginx问题定位之监控进程异常退出
ronin47
nginx在运行过程中是否稳定,是否有异常退出过?这里总结几项平时会用到的小技巧。
1. 在error.log中查看是否有signal项,如果有,看看signal是多少。
比如,这是一个异常退出的情况:
$grep signal error.log
2012/12/24 16:39:56 [alert] 13661#0: worker process 13666 exited on s
- No grammar constraints (DTD or XML schema).....两种解决方法
byalias
xml
方法一:常用方法 关闭XML验证
工具栏:windows => preferences => xml => xml files => validation => Indicate when no grammar is specified:选择Ignore即可。
方法二:(个人推荐)
添加 内容如下
<?xml version=
- Netty源码学习-DefaultChannelPipeline
bylijinnan
netty
package com.ljn.channel;
/**
* ChannelPipeline采用的是Intercepting Filter 模式
* 但由于用到两个双向链表和内部类,这个模式看起来不是那么明显,需要仔细查看调用过程才发现
*
* 下面对ChannelPipeline作一个模拟,只模拟关键代码:
*/
public class Pipeline {
- MYSQL数据库常用备份及恢复语句
chicony
mysql
备份MySQL数据库的命令,可以加选不同的参数选项来实现不同格式的要求。
mysqldump -h主机 -u用户名 -p密码 数据库名 > 文件
备份MySQL数据库为带删除表的格式,能够让该备份覆盖已有数据库而不需要手动删除原有数据库。
mysqldump -–add-drop-table -uusername -ppassword databasename > ba
- 小白谈谈云计算--基于Google三大论文
CrazyMizzz
Google云计算GFS
之前在没有接触到云计算之前,只是对云计算有一点点模糊的概念,觉得这是一个很高大上的东西,似乎离我们大一的还很远。后来有机会上了一节云计算的普及课程吧,并且在之前的一周里拜读了谷歌三大论文。不敢说理解,至少囫囵吞枣啃下了一大堆看不明白的理论。现在就简单聊聊我对于云计算的了解。
我先说说GFS
&n
- hadoop 平衡空间设置方法
daizj
hadoopbalancer
在hdfs-site.xml中增加设置balance的带宽,默认只有1M:
<property>
<name>dfs.balance.bandwidthPerSec</name>
<value>10485760</value>
<description&g
- Eclipse程序员要掌握的常用快捷键
dcj3sjt126com
编程
判断一个人的编程水平,就看他用键盘多,还是鼠标多。用键盘一是为了输入代码(当然了,也包括注释),再有就是熟练使用快捷键。 曾有人在豆瓣评
《卓有成效的程序员》:“人有多大懒,才有多大闲”。之前我整理了一个
程序员图书列表,目的也就是通过读书,让程序员变懒。 程序员作为特殊的群体,有的人可以这么懒,懒到事情都交给机器去做,而有的人又可以那么勤奋,每天都孜孜不倦得
- Android学习之路
dcj3sjt126com
Android学习
转自:http://blog.csdn.net/ryantang03/article/details/6901459
以前有J2EE基础,接触JAVA也有两三年的时间了,上手Android并不困难,思维上稍微转变一下就可以很快适应。以前做的都是WEB项目,现今体验移动终端项目,让我越来越觉得移动互联网应用是未来的主宰。
下面说说我学习Android的感受,我学Android首先是看MARS的视
- java 遍历Map的四种方法
eksliang
javaHashMapjava 遍历Map的四种方法
转载请出自出处:
http://eksliang.iteye.com/blog/2059996
package com.ickes;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
/**
* 遍历Map的四种方式
- 【精典】数据库相关相关
gengzg
数据库
package C3P0;
import java.sql.Connection;
import java.sql.SQLException;
import java.beans.PropertyVetoException;
import com.mchange.v2.c3p0.ComboPooledDataSource;
public class DBPool{
- 自动补全
huyana_town
自动补全
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"><html xmlns="http://www.w3.org/1999/xhtml&quo
- jquery在线预览PDF文件,打开PDF文件
天梯梦
jquery
最主要的是使用到了一个jquery的插件jquery.media.js,使用这个插件就很容易实现了。
核心代码
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.
- ViewPager刷新单个页面的方法
lovelease
androidviewpagertag刷新
使用ViewPager做滑动切换图片的效果时,如果图片是从网络下载的,那么再子线程中下载完图片时我们会使用handler通知UI线程,然后UI线程就可以调用mViewPager.getAdapter().notifyDataSetChanged()进行页面的刷新,但是viewpager不同于listview,你会发现单纯的调用notifyDataSetChanged()并不能刷新页面
- 利用按位取反(~)从复合枚举值里清除枚举值
草料场
enum
以 C# 中的 System.Drawing.FontStyle 为例。
如果需要同时有多种效果,
如:“粗体”和“下划线”的效果,可以用按位或(|)
FontStyle style = FontStyle.Bold | FontStyle.Underline;
如果需要去除 style 里的某一种效果,
- Linux系统新手学习的11点建议
刘星宇
编程工作linux脚本
随着Linux应用的扩展许多朋友开始接触Linux,根据学习Windwos的经验往往有一些茫然的感觉:不知从何处开始学起。这里介绍学习Linux的一些建议。
一、从基础开始:常常有些朋友在Linux论坛问一些问题,不过,其中大多数的问题都是很基础的。例如:为什么我使用一个命令的时候,系统告诉我找不到该目录,我要如何限制使用者的权限等问题,这些问题其实都不是很难的,只要了解了 Linu
- hibernate dao层应用之HibernateDaoSupport二次封装
wangzhezichuan
DAOHibernate
/**
* <p>方法描述:sql语句查询 返回List<Class> </p>
* <p>方法备注: Class 只能是自定义类 </p>
* @param calzz
* @param sql
* @return
* <p>创建人:王川</p>
* <p>创建时间:Jul