海量数据相似查找系列2 -- Annoy算法
范涛
发表于2017-04-19
上面一章说了下高维稀疏数据如何通过learning to hash的方法来进行相似查找,这种主要想说下另外一种情况,稠密向量如何进行快速相似查找呢?还是以文本为例吧。之前提到过文本的paragraph2vector的向量表示,以及词word2vector向量表示形式。一旦文档变成这种稠密向量形式,那如何从海量文本中快速查找出相似的Top N 文本呢?
所以这里重点想说下Annoy(
Approximate Nearest Neighbors
Oh Yeah
)这个快速算法,这个在实际应用中发现无论计算速度和准确性都非常不错。
一 算法原理
以2D数据为例来介绍Annoy算法,下面一个2D数据分布图:

1 建立索引过程
Annoy的目标是建立一个数据结构,使得查询一个点的最近邻点的时间复杂度是次线性。Annoy 通过建立一个二叉树来使得每个点查找时间复杂度是O(log n)。 看下面这个图,
随机选择两个点,以这两个节点为初始中心节点,执行聚类数为2的kmeans过程,最终产生收敛后两个聚类中心点。这两个聚类中心点之间连一条线段(灰色短线),建立一条垂直于这条灰线,并且通过灰线中心点的线(黑色粗线)。这条黑色粗线把数据空间分成两部分。在多维空间的话,这条黑色粗线可以看成等距垂直超平面。


在划分的子空间内进行不停的递归迭代继续划分,知道每个子空间最多只剩下K个数据节点。

通过多次递归迭代划分的话,最终原始数据会形成类似下面这样一个二叉树结构。二叉树底层是叶子节点记录原始数据节点,其他中间节点记录的是分割超平面的信息。Annoy建立这样的二叉树结构是希望满足这样的一个假设: 相似的数据节点应该在二叉树上位置更接近,一个分割超平面不应该把相似的数据节点分割二叉树的不同分支上。

2 查询过程
上面已完成节点索引建立过程。如何进行对一个数据点进行查找相似节点集合呢?比如下。这个图的红色节点。 查找的过程就是不断看他在分割超平面的哪一边。从二叉树索引结构来看,就是从根节点不停的往叶子节点遍历的过程。通过对二叉树每个中间节点(分割超平面相关信息)和查询数据节点进行相关计算来确定二叉树遍历过程是往这个中间节点左孩子节点走还是右孩子节点走。通过以上方式完成查询过程。


但是上述描述存在两个问题:
(1)查询过程最终落到叶子节点的数据节点数小于 我们需要的Top N相似邻居节点数目怎么办?
(2)两个相近的数据节点划分到二叉树不同分支上怎么办?
针对这个问题可以通过两个方法来解决:
(1)如果分割超平面的两边都很相似,那可以两边都遍历;下面是是个示意图:

(2) 建立多棵二叉树树,构成一个森林,每个树建立机制都如上面所述那样。多棵树示意图如下所示:

(3) 采用优先队列机制:采用一个优先队列来遍历二叉树,从根节点往下的路径,根据查询节点与当前分割超平面距离(margin)进行排序。
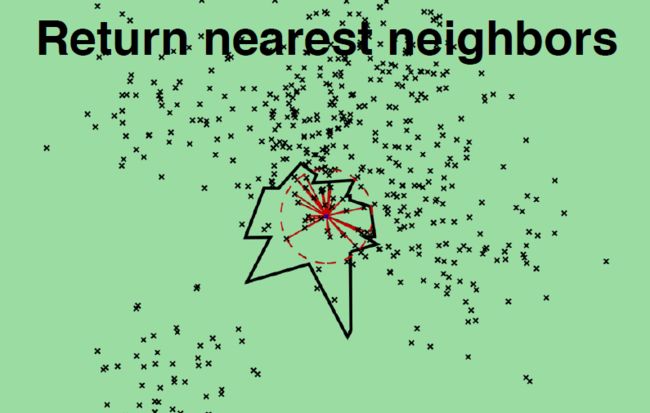
3 返回最终近邻节点
每棵树都返回一堆近邻点后,如何得到最终的Top N相似集合呢?
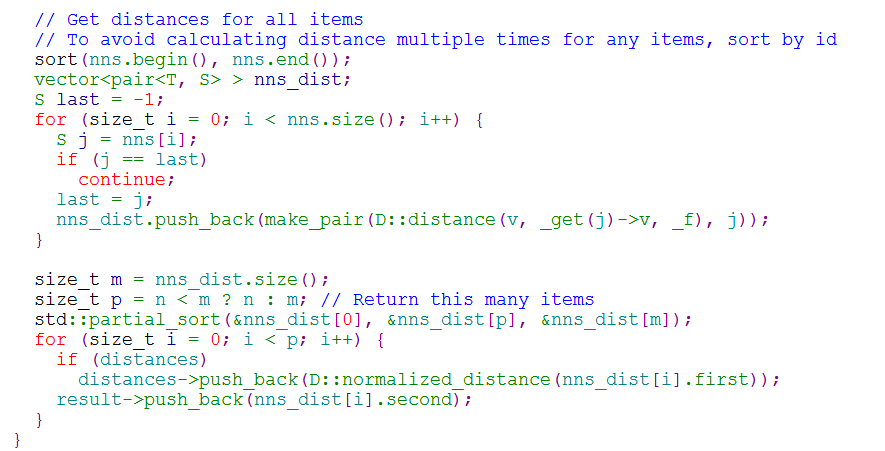
首先所有树返回近邻点都插入到优先队列中,求并集去重, 然后计算和查询点距离, 最终根据距离值从近距离到远距离排序, 返回Top N近邻节点集合。


4 效果
(1)下面是Annoy算法给的他的效果对比图:

(2)利用Annoy + Paragraph2vector进行query相似查找结果demo效果:

二 源码重点摘要
(1) build 函数是建立多棵树的入口,q表示树的数目。_roots 存的每棵树的根节点。_make_tree函数是一个递归函数,递归迭代创建二叉树。

(2)_make_tree 函数是一个递归函数,递归迭代创建二叉树。里面涉及如何计算分割超平面,然后判断数据节点在超平面哪一边。


(3)create_split 函数作用:如何计算分割超平面。超平面表示形式是通过n->v, n->a。其中n->v是向量表示形式(超平面法线向量),n->a是表示一种偏移值(offset)。“f”表示我们数据节点向量的维度。
补充下分割超平面的计算原理。那3维平面来说。假定平面定义为: Ax + By +Cz +D =0; 平面的法线向量n=(A, B, C), 截距 为D。因为分割超平面是垂直两个聚类中心点(best_iv, best_jv)的,那这两个聚类中心点连线向量就是表示超平面的法线向量。 假设best_iv, best_jv 是三维的话,那这通过这两个点的向量表示为k=(best_iv[0] - best_jv[0], best_iv[1] - best_jv[1], best_iv[2] - best_jv[2])。因为k=n,则:
A=best_iv[0] - best_jv[0], B=best_iv[1] - best_jv[1], C=best_iv[2] - best_jv[2]。因为分割超平面通过两个聚类中心节点连线中心点,这连线中心点定义为m=((best_iv[0] + best_jv[0])/2, (best_iv[1] + best_jv[1])/2, (best_iv[2] +best_jv[2])/2),则A * m[0] + B * m[1] + C * m[2] + D =0 => D= -(A * m[0] + B * m[1] + C * m[2])。
代码中n->v 存放的就是(A, B, C)这样的信息, n->a存放的就是D这样的信息。

(4) two_means函数作用:其实一种聚类数为2的kmeans过程。先随机选取两个数据节点为初始中心点,然后执行kmeans过程,达到迭代次数上限时候,输出两个聚类中心点。这两个中心点将作为分割超平面需要的两个节点。这个函数作用的是尽量让建立的二叉树结构足够平衡。

(5) side函数利用计算数据节点到底属于分割超平面哪一边(二叉树哪一个分支)
点到超平面的距离可参考下面公式:


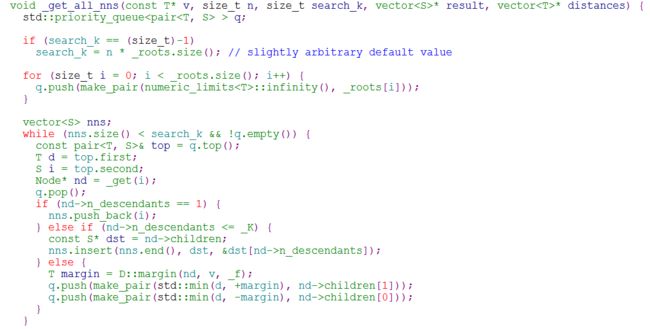
(6) _get_all_nns: 查询过程,给定一个数据节点向量,返回Top n近邻节点。采用优先队列完成节点并集计算,距离计算,返回Top n近邻。
参考文献
【1】 https://www.slideshare.net/erikbern/approximate-nearest-neighbor-methods-and-vector-models-nyc-ml-meetup
【2】 https://github.com/spotify/annoy
【3】 https://erikbern.com/2015/09/24/nearest-neighbor-methods-vector-models-part-1.html
【4】 https://erikbern.com/2015/10/01/nearest-neighbors-and-vector-models-part-2-how-to-search-in-high-dimensional-spaces.html