使用Keras处理和识别医学图像
最近在做医学图像的处理,简单的记录一下。
预处理
已知的数据集是通过labelimg工具打好标签的图片(如下图所示),总共区分三种病例。但标签框的大小不一致,必须要统一大小,以满足后期制作统一格式的数据集(*.npz、*.tfrecord等)。
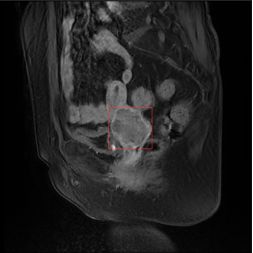
但如果只是简单的将图片取出来再统一大小,图片的分辨率可能会受影响,所以这里先将所有的标签框统一大小(取最大值)再把图片取出来(如下图)。

通过分析,发现样本数据不平衡,其中常见的病例占了近90%,不利于模型的训练。
查阅了资料找到了两种方法:
一.可以采用数据少的数据集里面数据增广的方式:
1.图像crop
2.图像旋转
3.图像平移
二.可以采用修改损失函数的方式,在数据量小的样本上增大权重
样本数量差别很大,会导致少样本的类别基本不被预测到,就像传统机器学习一样。
参数调节个人感觉主要在损失函数的计算上。http://www.caffecn.cn/?/question/20&tdsourcetag=s_pcqq_aiomsg
这里我使用了第一种方法(第二种后面再试试)。Keras内置的ImageDataGenerator用来生成数据非常方便,而且这个生成器还提供很多增强识别效果的特征提取方法,如:去中心化、均值化、ZCA白化等。
制作npz格式数据集
数据处理完就可以制作成数据集了(不仅限于npz格式,tfrecord等格式都可以)。
https://blog.csdn.net/u014038273/article/details/78320897
训练网络
用Keras简单构建了卷积神经网络,代码如下:
#! /usr/bin/env python
# -*- coding:utf-8 -*-
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Convolution2D, MaxPool2D
from keras.utils import np_utils
import numpy as np
# 全局变量
batch_size = 128 # 每批次多少样本
nb_classes = 3 # 类别总数
epochs = 50 # 遍历次数
img_rows, img_cols = 100, 100
nb_filters = 32 # 卷积个数
pool_size = (2, 2) # 池化面积大小
kernel_size = (3, 3) # 卷积核大小
'''
第一步,载入数据
'''
# 自定义数据
(x_train, y_train), (x_test, y_test) = np.load('train_data_1.npy', 'test_data_1.npy')
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
# 将标签数据转换为二维
y_train = np_utils.to_categorical(y_train, nb_classes)
y_test = np_utils.to_categorical(y_test, nb_classes)
'''
第二步,构建网络层
'''
# 卷积神经网络
model = Sequential()
model.add(Convolution2D(nb_filters, (kernel_size[0], kernel_size[1]),
padding='same',
input_shape=(100, 100, 1))) # 卷积层1
model.add(Activation('relu'))
model.add(Convolution2D(nb_filters, (kernel_size[0], kernel_size[1]))) # 卷积层2
model.add(Activation('relu'))
model.add(MaxPool2D(pool_size=pool_size)) # 池化层
model.add(Convolution2D(nb_filters, (kernel_size[0], kernel_size[1]))) # 卷积层3
model.add(Activation('relu'))
model.add(MaxPool2D(pool_size=pool_size)) # 池化层
model.add(Convolution2D(nb_filters, (kernel_size[0], kernel_size[1]))) # 卷积层4
model.add(Activation('relu'))
model.add(MaxPool2D(pool_size=pool_size)) # 池化层
model.add(Flatten()) # 拉成一维数据
model.add(Dense(128)) # 全连接层
model.add(Activation('relu'))
model.add(Dense(nb_classes))
model.add(Activation('softmax'))
'''
第三步,编译训练
'''
model.compile(loss='categorical_crossentropy', optimizer='adadelta', metrics=['accuracy'])
'''
第四步,训练
'''
print('开始训练')
model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test))
'''
第五步,输出
'''
print('开始评估')
scores = model.evaluate(x_test, y_test, verbose=1)
print('Test score:', scores[0])
print('Test accuracy:', scores[1])
# 保存模型
# model.save('model.h5')
评估后的准确率为96%,通过调整损失函数和参数优化等,准确率还能提高点(ps:刚开始直接用的Keras的神经网络例子,准确率只有50%,卷积神经网络还是强大)。

结论
对于医学图像的分类识别,最主要的就是图像特征的提取,如果直接把原图放进去训练效果很差。
使用神经网络来识别不常见的图像信息,这种方法越来越受到关注,后面试试用机器学习的方法来分类看看效果如何。