Hadoop的I/O操作——数据压缩
Hadoop的I/O操作——数据压缩
在处理大量数据的时候,文件压缩有两大好处:
(1)减少存储文件所需要的磁盘空间;
(2)加速数据在网络和磁盘上的传输。
因此,对于任何大容量的分布式存储系统而言,文件压缩是必须的。
比较常见压缩格式及其特点如下。其中,gzip对时间/空间的平衡做的最好;bzip2的压缩效率比gzip高,但比gzip慢;LZO的速度最快,但压缩效果比较差。
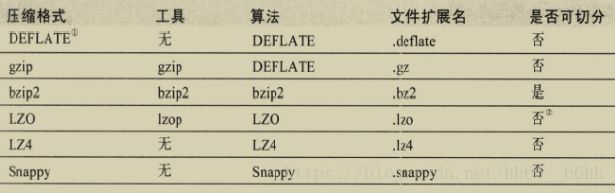
1. Hadoop的数据压缩概述
在Hadoop中,codec是压缩-解压缩算法的一种实现,一个对CompressionCodec接口的实现代表一个codec,例如GzipCodec包装了gzip的压缩和解压缩算法。Hadoop实现的codec如下:
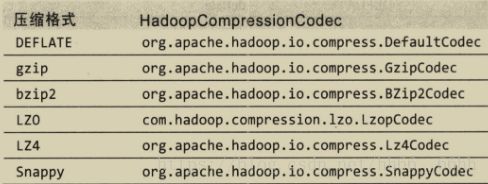
2. CompressionCodec创建
首先,可以通过类名得到Class的信息:
String codecClassName = "org.apache.hadoop.io.compress.GzipCodec";
Class<?>codecClass = Class.forName(codecClassName);
然后,CompressionCodec可以使用Hadoop的反射工具类ReflectionUtils来实例化,它需要的参数是codec类信息和configuration:
Configuration conf = new Configuration();
CompressionCodec codec = ReflectionUtils.newInstance(codecClass, conf);
2. 利用CompressionCodec压缩流
2.1 介绍
要压缩将被写到底层输出流的数据,可以使用createOutputStream(OutputStream)来创建一个CompressionOutputStream对象,这个对象会将数据进行压缩后再写入底层输出流。例如:
String codecClassName = "org.apache.hadoop.io.compress.GzipCodec";
Class<?>codecClass = Class.forName(codecClassName);
Configuration conf = new Configuration();
CompressionCodec codec = ReflectionUtils.newInstance(codecClass, conf);
CompressionOutputStream out = codec.createOutputStream(System.out);
IOUtils.copyBytes(System.in, out, 4096, false);
此处,System.in会将数据流写入out,out读取了数据流后,会利用Gzip算法对数据流进行压缩,然后再写入System.out。
2.2 实例1
实现目标:
将System.in的数据流进行压缩,然后写入System.out,并利用gunzip对System.out的数据进行解压。
实现过程:
- 编写StreamCompress.java:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.CompressionOutputStream;
import org.apache.hadoop.util.ReflectionUtils;
public class StreamCompress {
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
String codecClassname = args[0];
Class<?>codecClass = Class.forName(codecClassname);
CompressionCodec codec = (CompressionCodec)ReflectionUtils.newInstance(codecClass, conf);
CompressionOutputStream out = codec.createOutputStream(System.out);
IOUtils.copyBytes(System.in, out, 4096, false);
out.finish();
}
}
- 编译StreamCompress.java:
root@6b08ff31fc7f:/hadoop/hadoop-2.9.1/test/hadoop-io# javac StreamCompress.java
- 利用Hadoop运行StreamCompress类:
root@6b08ff31fc7f:/hadoop/hadoop-2.9.1/test/hadoop-io# echo "hello" | hadoop StreamCompress org.apache.hadoop.io.compress.GzipCodec | gunzip
18/10/13 09:22:02 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
hello
2.3 实例2
实现目标:
将System.in的数据流进行压缩,然后写入Hdfs的一个gz文件中。
实现过程:
- 编写FileCompressWriter.java:
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.*;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.CompressionOutputStream;
import org.apache.hadoop.util.ReflectionUtils;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class FileCompressWriter {
public static void main(String args[]) throws Exception{
String uri = args[0];
String codecClassName = args[1];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
OutputStream out = fs.create(new Path(uri));
Class<?> codecClass = Class.forName(codecClassName);
CompressionCodec codec = (CompressionCodec)ReflectionUtils.newInstance(codecClass, conf);
CompressionOutputStream output = codec.createOutputStream(out);
IOUtils.copyBytes(System.in, output, 4096, true);
}
}
- 编译FileCompressWriter.java:
root@6b08ff31fc7f:/hadoop/hadoop-2.9.1/test/hadoop-io# javac FileCompressWriter.java
- 查看HDFS里的/test/目录:
root@6b08ff31fc7f:/hadoop/hadoop-2.9.1/test/hadoop-io# hadoop fs -ls /test
18/10/13 09:28:43 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
- 利用Hadoop运行FileCompressWriter类:
root@6b08ff31fc7f:/hadoop/hadoop-2.9.1/test/hadoop-io# echo "heheheh hahaha" | hadoop FileCompressWriter /test/1.gz org.apache.hadoop.io.compress.GzipCodec
18/10/13 09:29:31 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
- 查看HDFS里的/test/目录:
root@6b08ff31fc7f:/hadoop/hadoop-2.9.1/test/hadoop-io# hadoop fs -ls /test18/10/13 09:30:03 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 1 items
-rw-r--r-- 1 root supergroup 30 2018-10-13 09:29 /test/1.gz
3. 利用CompressionCodecFactory推断压缩算法
3.1 介绍
在读取一个压缩文件的时候,通常可以通过文件扩展名来推断要使用哪个codec。例如,如果文件以.gz结尾,那么就可以用GzipCodec来读取它。org.apache.hadoop.io.compress.CompressionCodecFactory就提供了一种可以将文件扩展名映射成一个CompressionCodec的方法,该方法读取文件的Path对象,然后返回一个CompressionCodec对象。
public CompressionCodec getCodec(Path file)
3.2 实例1
实现目标:
给定HDFS里的压缩文件路径,输出该压缩文件的后缀。
实现过程
- 编写CodecNameGet.java:
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.*;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.CompressionInputStream;
import org.apache.hadoop.io.compress.CompressionCodecFactory;
import org.apache.hadoop.util.ReflectionUtils;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class CodecNameGet {
public static void main(String args[]) throws Exception{
String uri = args[0];
Configuration conf = new Configuration();
CompressionCodecFactory factory = new CompressionCodecFactory(conf);
CompressionCodec codec = factory.getCodec(new Path(uri));
if(codec == null) {
System.err.println("No codec found for " + uri);
System.exit(1);
}
System.out.println("The codecClass is " + codec.getDefaultExtension());
}
}
- 编译CodecNameGet.java:
root@6b08ff31fc7f:/hadoop/hadoop-2.9.1/test/hadoop-io# javac CodecNameGet.java
- 利用Hadoop运行CodecNameGet类:
root@6b08ff31fc7f:/hadoop/hadoop-2.9.1/test/hadoop-io# hadoop CodecNameGet /test/1.gz
18/10/13 10:44:45 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
The codecClass is .gz
可以看到,codec.getDefaultExtension()返回了压缩文件的后缀,即.gz。
4. 利用CompressionCodec解压流
4.1 介绍
要将来自底层输入流的数据进行解压,可以使用createIntputStream(IutputStream)来创建一个CompressionIutputStream对象,这个对象会将来自底层的数据进行解压。例如:
String codecClassName = "org.apache.hadoop.io.compress.GzipCodec";
Class<?>codecClass = Class.forName(codecClassName);
Configuration conf = new Configuration();
String uri = "/test/1.gz";
CompressionCodec codec = ReflectionUtils.newInstance(codecClass, conf);
FileSystem fs = FileSystem.get(URI.create(uri), conf);
CompressionInputStream in = codec.createInputStream(fs.open(new Path(uri)));
IOUtils.copyBytes(in, System.out, 4096, false);
此处,in会读取HDFS里的压缩文件1.gz,并对其进行解压,然后再写入System.out里。
4.2 实例1
实现目标
读取HDFS里的压缩文件1.gz,利用System.out来输出该文件的解压内容。
实现过程
- 编写FileDecompressor_1.java:
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.*;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.CompressionInputStream;
import org.apache.hadoop.io.compress.CompressionCodecFactory;
import org.apache.hadoop.util.ReflectionUtils;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class FileDecompressor_1 {
public static void main(String args[]) throws Exception{
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
CompressionCodecFactory factory = new CompressionCodecFactory(conf);
CompressionCodec codec = factory.getCodec(new Path(uri));
if(codec == null) {
System.err.println("No codec found for " + uri);
System.exit(1);
}
CompressionInputStream in = null;
try {
in = codec.createInputStream(fs.open(new Path(uri)));
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
}
- 编译FileDecompressor_1.java:
root@6b08ff31fc7f:/hadoop/hadoop-2.9.1/test/hadoop-io# javac FileDecompressor_1.java
- 利用Hadoop运行FileDecompressor_1类:
root@6b08ff31fc7f:/hadoop/hadoop-2.9.1/test/hadoop-io# hadoop FileDecompressor_1 /test/1.gz
18/10/13 11:29:44 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
18/10/13 11:29:45 INFO compress.CodecPool: Got brand-new decompressor [.gz]
heheheh hahaha
4.3 实例2
实现目标
读取HDFS里的压缩文件1.gz,将其解压到1.gz所在的目录下。
实现过程
- 编写FileDecompressor_2.java:
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.*;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.CompressionInputStream;
import org.apache.hadoop.io.compress.CompressionCodecFactory;
import org.apache.hadoop.util.ReflectionUtils;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class FileDecompressor_2 {
public static void main(String args[]) throws Exception{
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
//创建CompressionCodecFactory对象
CompressionCodecFactory factory = new CompressionCodecFactory(conf);
//根据文件的后缀推断出Codec对象
CompressionCodec codec = factory.getCodec(new Path(uri));
if(codec == null) {
System.err.println("No codec found for " + uri);
System.exit(1);
}
String outputuri = CompressionCodecFactory.removeSuffix(uri, codec.getDefaultExtension()); //解压文件的写入路径
CompressionInputStream in = null;
OutputStream out = null;
try {
in = codec.createInputStream(fs.open(new Path(uri)));
out = fs.create(new Path(outputuri));
IOUtils.copyBytes(in, out, conf);
} finally {
IOUtils.closeStream(in);
IOUtils.closeStream(out);
}
}
}
- 编译FileDecompressor_2.java:
root@6b08ff31fc7f:/hadoop/hadoop-2.9.1/test/hadoop-io# javac FileDecompressor_2.java
- 查看HDFS的/test/目录:
root@6b08ff31fc7f:/hadoop/hadoop-2.9.1/test/hadoop-io# hadoop fs -ls /test/
18/10/13 11:34:05 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 1 items
-rw-r--r-- 1 root supergroup 30 2018-10-13 09:29 /test/1.gz
- 利用Hadoop运行FileDecompressor_2类:
root@6b08ff31fc7f:/hadoop/hadoop-2.9.1/test/hadoop-io# hadoop FileDecompressor_2 /test/1.gz
18/10/13 11:36:01 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
18/10/13 11:36:02 INFO compress.CodecPool: Got brand-new decompressor [.gz]
- 查看HDFS的/test/目录:
root@6b08ff31fc7f:/hadoop/hadoop-2.9.1/test/hadoop-io# hadoop fs -ls /test/18/10/13 11:37:11 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 2 items
-rw-r--r-- 1 root supergroup 15 2018-10-13 11:36 /test/1
-rw-r--r-- 1 root supergroup 30 2018-10-13 09:29 /test/1.gz
可以看到,目录下生成了解压出来的文件1,利用cat命令查看其内容:
root@6b08ff31fc7f:/hadoop/hadoop-2.9.1/test/hadoop-io# hadoop fs -cat /test/1
18/10/13 11:38:25 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
heheheh hahaha