安装IK分词器及自定义扩展分词
1.为什么用ik分词器?
因为Elasticsearch中默认的标准分词器分词器对中文分词不是很友好,会将中文词语拆分成一个一个中文的汉子。因此引入中文分词器-es-ik插件。
传统分词器:可以看到把奥迪当做两个词进行搜索了,注意analyzer为"standard"


2. Linux安装ik分词器
① 下载es的IK插件,命名改为ik插件,把解压好的ik包上传到服务器
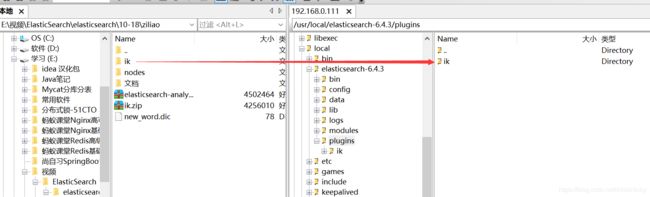
② 重启elasticsearch即可生效(就这么两步)
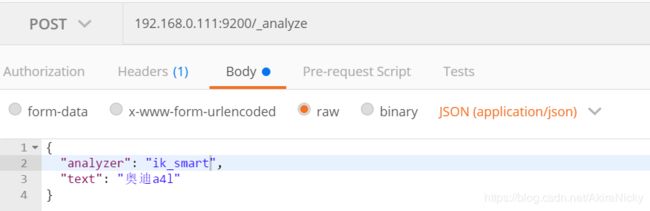
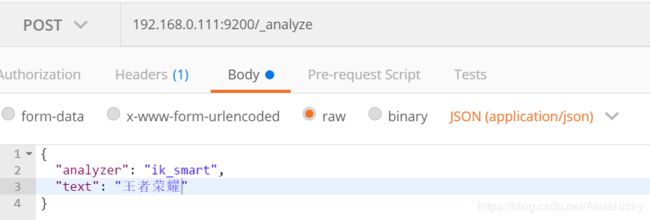
③ 验证ik分词器,可以看到奥迪为一个词,注意analyzer为ik_smart

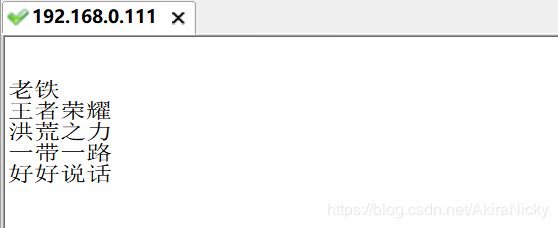
④ 不足:像王者荣耀这种最近比较火的热词,默认ik分词器是没有的
可以看到"王者荣耀"被分成了王者和荣耀两个词
解决办法:自定义扩展字典


3. 自定义分词
① 首先关闭elasticsearch,并进入ik下的config目录

在config下新建一个custom目录,新建new_word.dic
![]()
加入我们想加的词,wq:
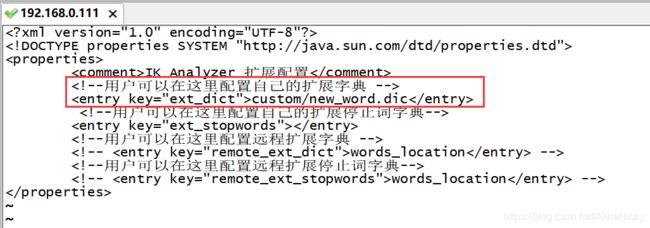
② 把上面新建的文件配置到/config下的IKAnalyzer.cfg.xml文件
![]()
③ 验证,启动elasticsearch:
此时再输入王者荣耀,则不会被分开

4. 文档映射
① 定义
已经把ElasticSearch的核心概念和关系数据库做了一个对比,索引(index)相当于数据库,类型(type)相当于数据表,映射(Mapping)相当于数据表的表结构。ElasticSearch中的映射(Mapping)用来定义一个文档,可以定义所包含的字段以及字段的类型、分词器及属性等等。
文档映射就是给文档中的字段指定字段类型、分词器。
使用GET myes/user/_mapping
② 映射的分类
动态映射
我们知道,在关系数据库中,需要事先创建数据库,然后在该数据库实例下创建数据表,然后才能在该数据表中插入数据。而ElasticSearch中不需要事先定义映射(Mapping),文档写入ElasticSearch时,会根据文档字段自动识别类型,这种机制称之为动态映射。
静态映射
在ElasticSearch中也可以事先定义好映射,包含文档的各个字段及其类型等,这种方式称之为静态映射。
③ 基本类型
字符串:string,string类型包含 text 和 keyword
text:该类型被用来索引长文本,在创建索引前会将这些文本进行分词,转化为词的组合,建立索引;允许es来检索这些词,text类型不能用来排序和聚合。
keyword:该类型不需要进行分词,可以被用来检索过滤、排序和聚合,keyword类型自读那只能用本身来进行检索(不可用text分词后的模糊检索)
注意: keyword类型不能分词,Text类型可以分词查询
数值型:long、integer、short、byte、double、float
日期型:date
布尔型:boolean
二进制型:binary
数组类型:(Array datatype)
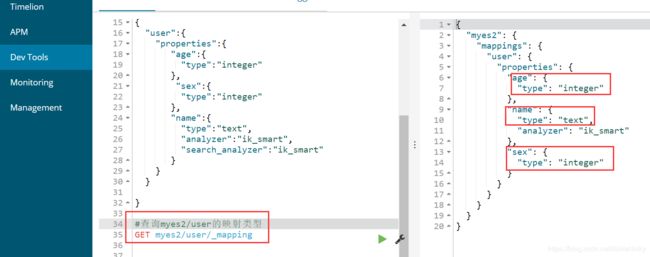
④ 之前的方式,查询出来的name是text类型,age和sex均为long类型(即动态映射)
put myes/user/1
{
"name":"zhangsan",
"age":20,
"sex":0
}
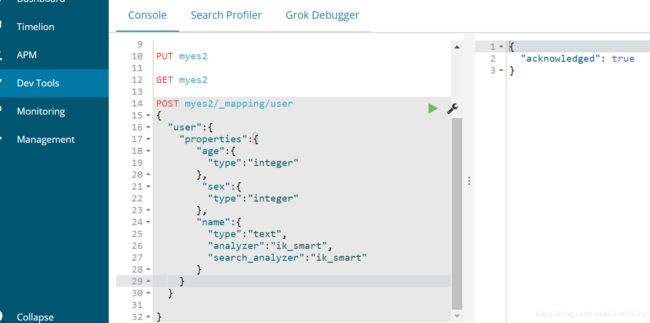
⑤ 如果想静态映射,即创建文档类型并且指定类型,可以这样:
1> 新建一个索引myes2,并指定类型
2> 查询myes2/user的映射类型
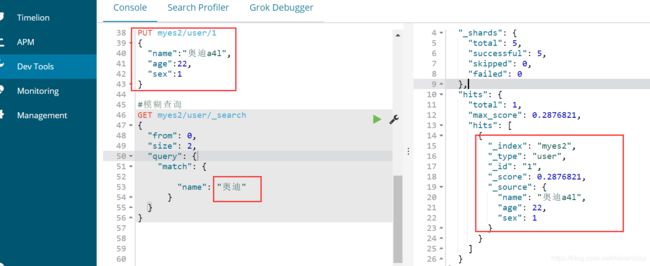
③ 由于上面的name为text类型,所以可以模糊查询(text类型可以分词查询)
如果上面的name为keyword类型,则不可以模糊查询,即查奥迪查不出来,必须是精确查询( keyword类型不能分词)