TensorFlow:卷积神经网络手势识别项目的调参感悟
调参感悟
对于网络的选择,我采用通用的由简入繁的做法(在吴恩达的课程中,他也多次表达了这类思想)。
-
首先,尝试了简单网络LeNet-5,由于网络的设计原因,对于5分类测试集上的表现非常糟糕(过拟合)。
-
其次,尝试复杂一些的AlexNet。经过调参和优化环节,最终取得了不错的成绩。
调参的过程无非是解决两个问题,欠拟合和过拟合。因为这个五分类问题的复杂度低,因此自始至终,我们面临的都是过拟合。
解决过拟合
第一次尝试:LeNet-5
一开始每种手势动作只拍摄了500张,用的是LeNet-5结构,训练集的accuracy很高,loss也很高,测试集的效果很明显差到爆炸。
-
这是明显的过拟合,考虑到LeNet-5中无Dropout,使用tanh非ReLu,也是可以理解的
-
此外,数据量也是可以再增加以便缓解过拟合
第二次尝试:AlexNet + SAME Pooling
出于上述原因,因此决定试试经典的AlexNet结构(卷积层数和池化层数为AlexNet结构,池化方式选择SAME),在两个全连接层加入droupout = 0.5,防止过拟合。Batch size设置为256以加快训练速度,这样可以更快看到结果。
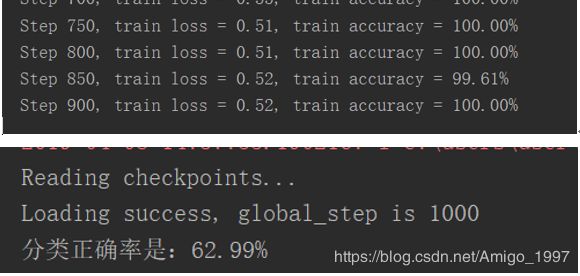
虽然测试集的accuracy已经比LeNet-5提升很多,接近63%,但很明显依然过拟合。后发现Pooling的方式对过拟合亦有影响。
第三次尝试:AlexNet + VALID Pooling
相对于SAME池化方式,VALID方式会输入周围更少的特征,对减少过拟合肯定是有帮助的,于是尝试VALID。
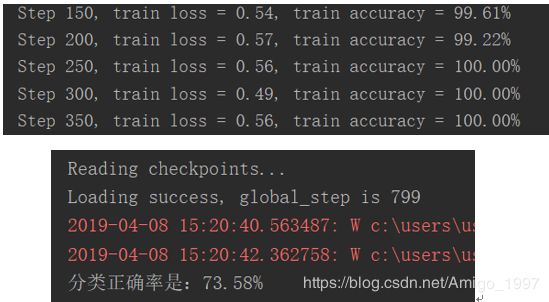
预测集的正确率提高了10%,但是肯定还有很大的提高空间,而且很明显还是过拟合。
解决过拟合的最直接的方式是增加数据集和减小模型参数,例如之前猫狗分类问题是各12500张。
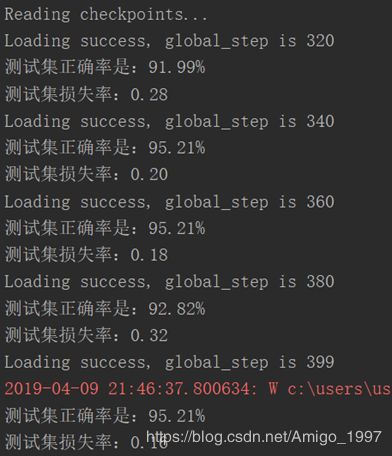
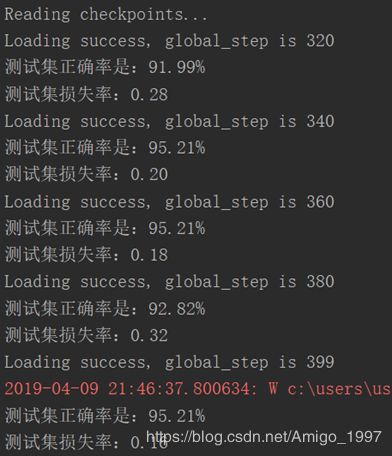
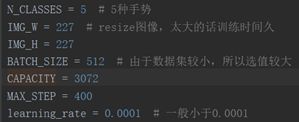
第四次尝试:AlexNet + VALID Pooling + 调整Batch Size
再加数据之前,我先再调大了batch size = 512,看看batch size对结果的影响:
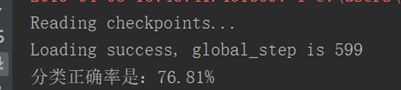
如图,作用并不是很明显,而且无法再加大batch size,会爆显存。于是按此前计划开始增加数据集。
第五次尝试:AlexNet + VALID Pooling + 增加数据集
增加数据集(每个手势+100)
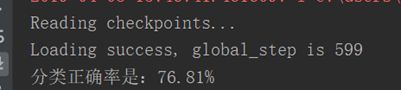
增加数据集(每个手势再+200)
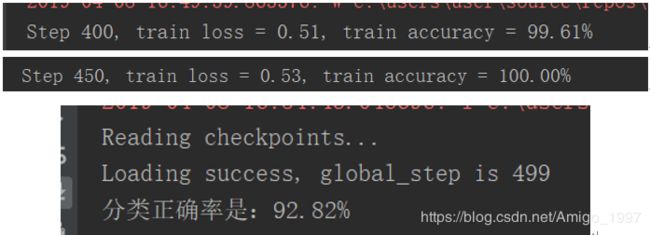
每种手势增加300张图片后,我发现测试集的正确率突然飙升上了90%。
增加数据集(每个手势再 +100)
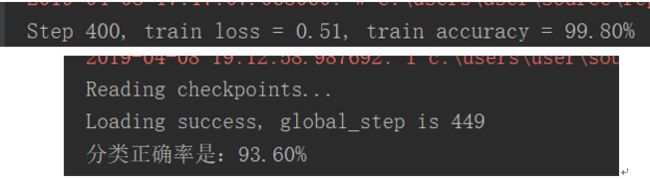
这个时候测试集的正确率算看得过去了,此时训练集是每种手势900张,一共4500张图片。
在线测试中,发现5种手势有4种识别的还可以,但是Good手势识别经常错误,于是单独给Good手势增加150张图片。
增加数据集(只给Good手势再 +150)
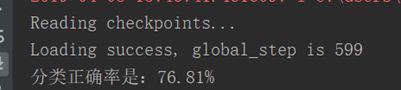
增加数据集(每个手势再 +100)
正确率有微弱提升,然后再每种手势+100照片,正确率不再提升了。
现在的正确率虽然可以接受了,但实时测试的效果并不是很理想。可能是因为测试集比实时测试的时候背景干净,噪声更小,为了更好的检验模型,我在测试集上除了输出正确率还输出损失。
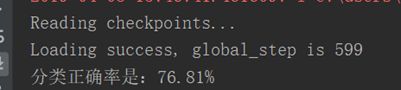
损失率达到了0.77难怪我的实时测试消息并不理想。
第六次尝试:AlexNet + VALID Pooling + 大数据集 + 数据预处理
解决思路是从数据集入手,检测自己拍的数据集,把一些拍的不好的数据删除替换,并把实时检测的图片大小由400x400 切割变化为300x300,从而突出手势动作,而忽略其他背景干扰。
同时增加数据集的300x300的手势动作图片,使训练集前4种手势各有1300张照片,Good手势有1450张照片。(切割出感兴趣区域提高识别准确率)
第七次尝试:AlexNet + VALID Pooling + 大数据集 + 数据预处理 + 小Mini-Batch
想起此前Yann LeCun(2019年获得图灵奖获得者)的一个言论:
Training with large minibatches is bad for your health. More importantly, it's bad for your test error. Friends don‘t let friends use minibatches larger than 32. Let's face it: the only people have switched to minibatch sizes larger than one since 2012 is because GPUs are inefficient for batch sizes smaller than 32. That's a terrible reason. It just means our hardware sucks.
他认为大于32的batch-size都是深恶痛绝的。
The best performance has been consistently obtained for mini-batch sizes between m=2 and m=32, which contrasts with recent work advocating the use of mini-batch sizes in the thousands.
也就是最好的实验表现都是在batch size处于 2 ~ 32 之间得到的,这和最近深度学习界论文中习惯的动辄上千的batch size选取有很大的出入。
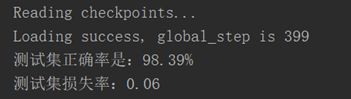
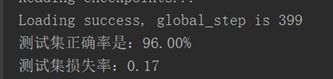
尝试于是调小Batch Size为32。测试集准确率已接近96%。对于实时测试,手势基本都能识别对了,达到了应用的目标!
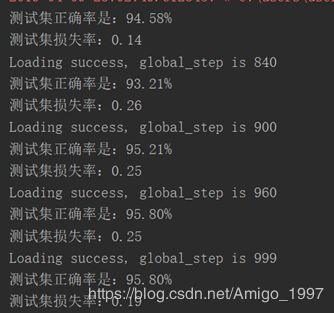
一些调参过程的图
 (极端情形)
(极端情形)
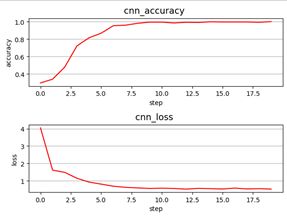 Step=step*20
Step=step*20
只改动:把Batch-size =32
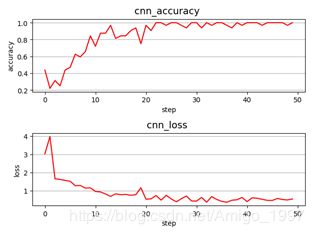
一些Batch选择观点
下属观点来源知乎。
回想我们使用mini-batch技术的原因,无外乎是因为mini-batch有这几个好处 :
-
提高了运行效率,相比batch-GD的每个epoch只更新一次参数,使用mini-batch可以在一个epoch中多次更新参数,加速收敛。
-
解决了某些任务中,训练集过大,无法一次性读入内存的问题。
-
虽然第一点是mini-batch提出的最初始的原因,但是后来人们发现,使用mini-batch还有个好处,即每次更新时由于没有使用全量数据而仅仅使用batch内数据,从而人为给训练带来了噪声,而这个操作却往往能够带领算法走出局部最优(鞍点)。理论证明参见COLT的这篇论文Escaping From Saddle Points-Online Stochastic Gradient for Tensor Decomposition。也就是说,曾经我们使用mini-batch主要是为了加快收敛和节省内存,同时也带来每次更新有些“不准”的副作用,但是现在的观点来看,这些“副作用”反而对我们的训练有着更多的增益,也变成mini-batch技术最主要的优点。
但是,Batch size的选择需要考虑如下的trade-off:
-
小Batch训练的稳定性较差。小batch确实有这个缺点,而且对设置学习速率有更高的要求,否则可能引起恶性的震荡无法收敛。但是小batch的优点仍然是显著的。
-
Batch size 可能也不是越大越好,ICLR 2017 On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima 比较了一直用small batch(实验设置的256,貌似也不小了...)和一直用large batch(整个数据集十分之一...)训练,最后发现同样训练到最终收敛,在多个数据集上large batch比small batch泛化能力差。
-
前期用小batch引入噪声,有利于跳出sharp minima,后期用大batch避免震荡,同样目的也可以通过调小lrate做到,同比例地增大batch size和同比例地减小lrate能得到极相近的loss-epoch曲线,不过前者update次数会少很多~(Don't Decay the Learning Rate, Increase the Batch Size)