Python数据预处理
1.导入数据文件(excel,csv,数据库文件等)
df=read_table(file,names=[列名1,列名2,,,],sep="",encoding)
#file是文件路径,names默认为文件的第一行为列名,sep为分隔符,默认为空,表示默认导入为一列
#encoding设置文件编码,导入中文时,需设置utf-82.导出数据文件
to_csv(filepath,sep="",index=TRUE,header=TRUE)
#index是否导出行序号,默认为导出,header是否导出列名,默认为导出
data.loc[:,["城市","公司全名"]] #输出特定列,行可类比
data.iloc[3,1] #输出第三行,第一位
data.iloc[3:5,1:3] #3-5行,1-2列交集
data.ix[:3,["A","C"]] #0-3行
data.A>8 #输出A列大于8的所有行
print(df[data.A>8])3.重复值处理(只保留一个)
df.drop_duplicates()#直接调用函数即可(保留一行)4.缺失值处理
产生原因:信息无法获取,信息被遗漏或错误处理
处理方式:补齐,删除缺失行,不处理
df.dropna()#去除数据结构中值为空的数据
df.dropna(axis=0,how="any") #注释:axis=0代表"行","any"代表任何空值行,如何是"all"则代表所有值都为空时,才删除该行
df.fillna(value=0) #填充空值为0 适合数据庞大不易观察的情况下
print(df.isnull()) #判断空值
print(np.any(df.isnull())==True) #至少包含一个空值,则返回true
5.空格值处理
n=df["name"].str.strip() #清除字符型数据左右的空格
df["name"]=n6.字段抽取与字段拆分
根据已知列数据的开始和结束,抽出新的列
slice(start,stop) #开始位置,结束位置
如:号码138 1337 5758
df["tel"]=df["tel"].astype(str)
df["tel"].str.slice(0,3) #抽取手机号码的前三位数(运营商)
#字段拆分
split(sep,n,expand=False)
#sep指用于分割的字符串,n指分割为多少列,expand是否展开为数据框(默认为False返回series,True返回dataframe)
news=df["name"].str.split("",1,True) #1代表拆分为两列,从0开始计数
news.columns=["band","names"] #命名7.记录抽取
#DataFrame[condition]
#比较
df[df.comments>10000]
#范围
between(left,right)
df[df.comments.between(1000,10000)]
#空值匹配
pandas.isnull(column) #判断是否有空值
df[pandas.isnull(df.title)
#字符匹配
str.contains(patten,na=False) #空值的处理方式,空值不匹配(False)
如:df[df.title.str.contains("台电",na=False)]
#逻辑运算(与&,或|,取反not)
如:df[(df.comments>=1000)&(df.comments<=10000)]
等价于df[df.comments.between(1000,10000)]
8.随机抽样(按照一定的行数或比例抽取)
import numpy as np
np.random.randint(start,end,num) #在start和end之间随机抽取num个样本数,返回行所在的索引值
如:r=np.random.randint(0,10,3)
df.loc(r,:) #将所在行输出9.记录合并
将两个结构相同的数据框合并为一个数据框
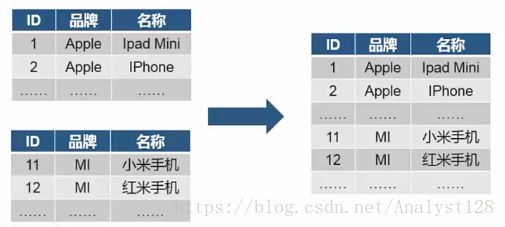
concat([df1,df2,,],axis=0,ignore_index=True)
#axis=0代表竖向排列,ignore_index代表忽视索引,重新排序,参数join默认为outer,反之inner代表相同部分合并
df1.append([df2,df3],ignore_index=True) #拼接
10.字段合并
字段拆分的逆向操作
字符合并方法:
x=x1+x2+,,,(序列长度一直,并且为字符型数据)
df.astype(str) #转换为字符型数据
tel=df["band"]+df["area"]+["num"] #合并且赋值于新变量
11.字段匹配
merge函数
left=pd.DataFrame({})
res=pd.merge(left,right,on="key") #多个关键词,on="key1","key2"
#默认的合并方式是how="inner":合并同类项,outer为合并所有的,没有的以空值NAN填充
#或者(left,right,left_index=True,right_index=True,how="outer")
#合并多个dataframe
contat([df1,df2,df3],axis=0) #axis=0代表竖向排列
#append() 对dataframe进行拼接
12.简单计算
res=df.price*df.num
df["total"]=a
13.数据标准化(0-1)
x*=(x-min)/(max-min)
scale=(df.score-df.score.min())/(df.score.max()-df.score.min())