Spark Streaming运行架构和运行原理总结
原文地址:https://blog.csdn.net/zhanglh046/article/details/78505053
一 运行架构
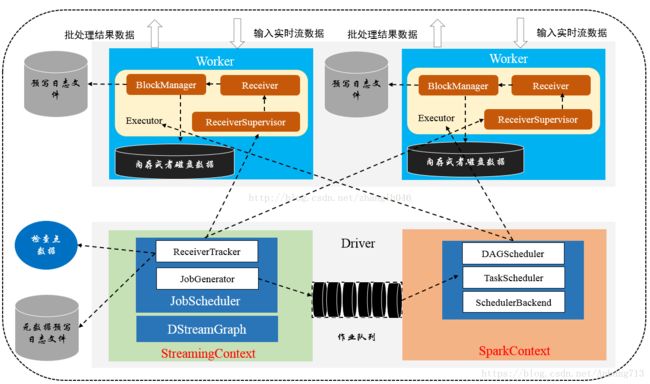
Spark Streaming相对其他流处理系统最大的优势在于流处理引擎和数据处理在同一软件栈,其中Spark Streaming功能主要包括流处理引擎的流数据接收与存储以及批处理作业的生成与管理,而Spark Core负责处理Spark Streaming发送过来的作业。Spark Streaming分为Driver端和Client端,运行在Driver端为StreamingContext实例,该实例包括DStreamGraph和JobScheduler(包括ReceiverTracker和JobGenerator)等,而Client包括ReceiverSupervisor和Receiver等。
Spark Streaming进行流数据处理大致可以分为:启动流数据引擎、接收及存储流数据、处理流数据和输出处理结果等4个步骤。
二 Spark Streaming各个组件
- StreamingContext: Spark Streaming 中Driver端的上下文对象,初始化的时候会构造Spark Streaming应用程序需要使用的组件,比如DStreamGraph、JobScheduler等。
- DStreamGraph:用于保存DStream和DStream之间依赖关系等信息。
- JobScheduler: 主要用于调度job。JobScheduler主要通过JobGenerator产生job,并且通过ReceiverTracker管理流数据接收器Receiver。
- JobGenerator: 主要是从DStream产生job, 且根据指定时间执行checkpoint. 他维护了一个定时器,该定时器在批处理时间到来的时候会进行生成作业的操作。
- ReceiverTracker: 管理各个Executor上的Receiver的元数据。它在启动的时候,需要根据流数据接收器Receiver分发策略通知对应的Executor中的ReceiverSupervisor(接收器管理着)启动,然后再由ReceiverSupervisor来启动对应节点的Receiver
- ReceiverTrackerEndpoint: ReceiverTracker用于通信的RPC终端。
- Receiver:数据接收器,用于接收数据,通过ReceiverSupervisor将数据交给ReceiveBlockHandler来处理。
- ReceiverSupervisor:主要用于管理各个worker节点上的Receivor,比如启动worker上的Receiver,或者是转存数据,交给ReceiveBlockHandler来处理;数据转存完毕,将数据存储的元信息汇报给ReceiverTracker,由它来负责管理收到的数据块元信息。
- BlockGenerator: 这个类的主要作用是创建Receiver接收的数据的batches,然后根据时间间隔命名为合适的block. 并且把准备就绪的batches作为block 推送到BlockManager。
- ReceiveBlockHandler:主要根据是否启用WAL预写日志的机制,区分为预写日志和非预写日志存储。非预写日志则是直接将数据通过BlockManager写入Worker的内存或者磁盘;而预写日志则是在预写日志的同时把数据写入Worker的内存或者磁盘。
- ReceiverSchedulingPolicy: Receiver调度策略。
三 运行原理剖析
1、初始化StreamingContext对象,在该对象启动过程中实例化DStreamGraph 和 JobScheduler,其中DStreamGraph用于存放DStream以及DStram之间的依赖关系等信息;而JobScheduler中包括ReceiverTracker和JobSGenerator,其中ReceiverTracker为Driver端流数据接收器(Receiver)的管理者,JobGenerator为批处理作业生成器。在ReceiverTracker启动过程中,根据流数据接收器分发策略通知对应的Executor中的流数据接收管理器(ReceiverSupervisor)启动,再由ReceiverSupervisor启动流数据接收器。
2、当流数据接收器Receiver启动后,持续不断地接收实时流数据,根据传过来数据的大小进行判断,如果数据量很小,则攒多条数据成一块,然后再进行块存储;如果数据量大,则直接进行块存储。对于这些数据Receiver直接交给ReceiverSupervisor,由其进行数据转储操作。块存储根据设置是否预写日志分为两种,一种是使用非预写日志BlockManagerBasedBlockHandler方法直接写到Worker的内存或磁盘中;另一种是进行预写日志WriteAheadLogBasedBlockHandler方法,即在预写日志同时把数据写入到Worker的内存或磁盘中。数据存储完毕后,ReceiverSupervisor会把数据存储的元信息上报给ReceiverTracker,ReceiverTracker再把这些信息转发给ReceiverBlockTracker,由它负责管理收到数据块的元信息。
3、在StreamingContext的JobGenerator中维护一个定时器,该定时器在批处理时间到来会进行生成作业的操作,具体如下:
- 通知ReceiverTracker将接收到的数据进行提交,在提交时采用synchronized关键字进行处理,保证每条数据被划入一个且只被划入一个批中。
- 要求DStreamGraph根据DStream依赖关系生成作业序列Seq[Job]。
- 从第一步中ReceiverTracker获取本批次数据的元数据。
- 把批处理时间time、作业序列Seq[Job]和本批次数据的元数据包装为JobSet,调用JobScheduler.submitJobSet(JobSet)提交给JobScheduler,JobScheduler将把这些作业发送给Spark Core进行处理,由于该操作是异步的,因为本操作执行速度非常快。
- 只要提交结束(不管作业是否被执行),Spark Streaming对整个系统做一个检查点(Checkpoint)。
4、在Spark Core的作业数据进行处理,处理完毕后输出到外部系统,如数据库或文件系统,输出的数据可以被外部系统所使用。由于实时流数据的数据源源不断地柳树,Spark会周而复始地进行数据处理,相应的会持续不断地输出结果。
四 运行原理源码分析
4.1. 启动流处理引擎
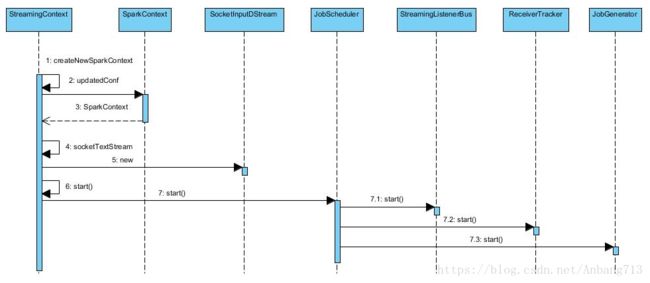
4.1.1. 初始化StreamingContext
首先需要初始化StreamingContext,在初始化的过程中会对DStreamGraph、JobScheduler等进行初始化,DStreamGraph类似于RDD的有向无环图,包含DStream之间相互依赖的有向无环图;JobScheduler的作用是定时查看DStreamGraph,然后根据流入的数据生成运行作业。
4.1.2. 创建InputDStream
根据你采用不同的数据源,可能生成的输入数据流不一样。
4.1.3. 启动JobScheduler
创建完成InputDStream之后,调用StreamingContext的start方法启动应用程序,其最重要的就是启动JobScheduler。在启动JobScheduler的时候会实例化ReceiverTracker和JobGenerator。
def start(): Unit = synchronized {
// JobShceduler已经启动则退出
if (eventLoop != null) return
logDebug("Starting JobScheduler")
eventLoop = new EventLoop[JobSchedulerEvent]("JobScheduler") {
override protected def onReceive(event: JobSchedulerEvent): Unit = processEvent(event)
override protected def onError(e: Throwable): Unit = reportError("Error in job scheduler", e)
}
eventLoop.start()
for {
// 获取InputDStream
inputDStream<- ssc.graph.getInputStreams
rateController<- inputDStream.rateController
} ssc.addStreamingListener(rateController)
listenerBus.start()
// 构建ReceiverTracker和InputInfoTracker
receiverTracker= new ReceiverTracker(ssc)
inputInfoTracker= new InputInfoTracker(ssc)
val executorAllocClient: ExecutorAllocationClient= ssc.sparkContext.schedulerBackend match {
case b: ExecutorAllocationClient => b.asInstanceOf[ExecutorAllocationClient]
case _ => null
}
executorAllocationManager= ExecutorAllocationManager.createIfEnabled(
executorAllocClient,
receiverTracker,
ssc.conf,
ssc.graph.batchDuration.milliseconds,
clock)
executorAllocationManager.foreach(ssc.addStreamingListener)
// 启动ReceiverTracker
receiverTracker.start()
// 启动JobGenerator
jobGenerator.start()
executorAllocationManager.foreach(_.start())
logInfo("Started JobScheduler")
}
4.1.4. 启动JobGenerator
启动JobGenerator需要判断是否第一次运行,如果不是第一次运行需要进行上次检查点的恢复,如果是第一次运行则调用startFirstTime方法,在该方法中初始化了定时器的开启时间,并启动了DStreamGraph和定时器timer。
private def startFirstTime() {
val startTime = new Time(timer.getStartTime())
graph.start(startTime - graph.batchDuration)
timer.start(startTime.milliseconds)
logInfo("Started JobGenerator at " + startTime)
}
timer的getStartTime方法会计算出来下一个周期到期时间,计算公式: 当前时间 / 间隔时间。
4.2. 接收及存储流数据
4.2.1. 启动ReceiverTracker
启动ReceiverTracker的时候,如果输入数据流不为空,则调用launchReceivers方法,然后他就会向ReceiverTrackerEndpoint发送StartAllReceivers方法,启动所有Receivers。
private def launchReceivers(): Unit = {
val receivers = receiverInputStreams.map { nis =>
val rcvr = nis.getReceiver()
rcvr.setReceiverId(nis.id)
rcvr
}
runDummySparkJob()
// 发送启动所有receiver的消息
endpoint.send(StartAllReceivers(receivers))
}
case StartAllReceivers(receivers) =>
// 根据receiver分发策略,获取与之对应的receiver和executor调度信息
val scheduledLocations = schedulingPolicy.scheduleReceivers(receivers, getExecutors)
// 遍历receivers,为根据receiver获取候选的executor,更新被调度receiver的位置信息,即executor信息
// 开启receiver
for (receiver <- receivers) {
val executors = scheduledLocations(receiver.streamId)
updateReceiverScheduledExecutors(receiver.streamId, executors)
// 保存流数据接收器Receiver首选位置
receiverPreferredLocations(receiver.streamId) = receiver.preferredLocation
// 启动每一个Receiver
startReceiver(receiver, executors)
}
最后创建ReceiverSupervisor,并启动,在启动的时候,由它启动Receiver。
4.2.2. Receiver启动并接收数据
Receiver启动会调用各个具体子类的onstart方法,这里面就会接收数据,以kafka为例,则会根据提供配置创建连接,获取消息流,构造一个线程池,为每一个topic分区分配一个线程处理数据。
def onStart() {
// 获取kafka连接参数
val props = new Properties()
kafkaParams.foreach(param => props.put(param._1, param._2))
val zkConnect = kafkaParams("zookeeper.connect")
// Create the connection to the cluster
logInfo("Connecting to Zookeeper: " + zkConnect)
// 构造消费者配置文件
val consumerConfig = new ConsumerConfig(props)
// 根据消费者配置文件创建消费者连接
consumerConnector = Consumer.create(consumerConfig)
logInfo("Connected to " + zkConnect)
// 构造keyDecoder和valueDecoder
val keyDecoder = classTag[U].runtimeClass.getConstructor(classOf[VerifiableProperties])
.newInstance(consumerConfig.props)
.asInstanceOf[Decoder[K]]
val valueDecoder = classTag[T].runtimeClass.getConstructor(classOf[VerifiableProperties])
.newInstance(consumerConfig.props)
.asInstanceOf[Decoder[V]]
// Create threads for each topic/message Stream we are listening
// 创建消息流
val topicMessageStreams = consumerConnector.createMessageStreams(
topics, keyDecoder, valueDecoder)
// 构造线程池
val executorPool =
ThreadUtils.newDaemonFixedThreadPool(topics.values.sum, "KafkaMessageHandler")
try {
// 开始处理每一个分区的数据
topicMessageStreams.values.foreach { streams =>
streams.foreach { stream => executorPool.submit(new MessageHandler(stream)) }
}
} finally {
executorPool.shutdown() // Just causes threads to terminate after work is done
}
}
4.2.3. 启动BlockGenerator生成block
在ReceiverSupervisorImpl的onstart方法中调用BlockGenerator的start启动BlockGenerator。
override protected def onStart() {
registeredBlockGenerators.asScala.foreach { _.start() }
}
启动时候会先更新自身状态为Active,然后启动2个线程:
blockIntervalTimer:定义开始一个新batch,然后准备把之前的batch作为一个block。
blockPushingThread:把数据块 push到block manager。
def start(): Unit = synchronized {
if (state == Initialized) {
// 更改状态
state = Active
// 开启一个定时器,定期的把缓存中的数据封装成数据块
blockIntervalTimer.start()
// 开始一个线程,不断将封装好的数据封装成数据块
blockPushingThread.start()
logInfo("Started BlockGenerator")
} else {
throw new SparkException(
s"Cannot start BlockGenerator as its not in the Initialized state [state = $state]")
}
}
private def updateCurrentBuffer(time: Long): Unit = {
try {
var newBlock: Block = null
synchronized {
// 判断当前放数据的buffer是否为空,如果不为空
if (currentBuffer.nonEmpty) {
// 则赋给一个新的block buffer,然后再把置为currentBuffer空
val newBlockBuffer = currentBuffer
currentBuffer = new ArrayBuffer[Any]
// 构建一个blockId
val blockId = StreamBlockId(receiverId, time - blockIntervalMs)
listener.onGenerateBlock(blockId)
// 构建block
newBlock = new Block(blockId, newBlockBuffer)
}
}
// 新的block不为空,则放入push队列,如果该队列满了则由其他线程push到block manager
if (newBlock != null) {
blocksForPushing.put(newBlock) // put is blocking when queue is full
}
} catch {
case ie: InterruptedException =>
logInfo("Block updating timer thread was interrupted")
case e: Exception =>
reportError("Error in block updating thread", e)
}
}
4.2.4. 数据存储
Receiver会进行数据的存储,如果数据量很少,则攒多条数据成数据块在进行块存储;如果数据量很大,则直接进行存储,对于需要攒多条数据成数据块的操作在Receiver.store方法里面调用ReceiverSupervisor的pushSingle方法处理。在pushSingle中把数据先保存在内存中,这些内存数据被BlockGenerator的定时器线程blockIntervalTimer加入队列并调用ReceiverSupervisor的pushArrayBuffer方法进行处理。
他们其实都是调用的是pushAndReportBlock,该方法会调用ReceiveBlockHandler的storeBlock方法保存数据并根据配置进行预写日志;另外存储数据块并向driver报告:
def pushAndReportBlock(
receivedBlock: ReceivedBlock,
metadataOption: Option[Any],
blockIdOption: Option[StreamBlockId]
) {
// 获取一个blockId
val blockId = blockIdOption.getOrElse(nextBlockId)
val time = System.currentTimeMillis
// 存储block
val blockStoreResult = receivedBlockHandler.storeBlock(blockId, receivedBlock)
logDebug(s"Pushed block $blockId in ${(System.currentTimeMillis - time)} ms")
// 结果数量
val numRecords = blockStoreResult.numRecords
// 构建ReceivedBlockInfo
val blockInfo = ReceivedBlockInfo(streamId, numRecords, metadataOption, blockStoreResult)
// 向ReceiverTrackerEndpoint发送AddBlock消息
trackerEndpoint.askWithRetry[Boolean](AddBlock(blockInfo))
logDebug(s"Reported block $blockId")
}
4.3. 数据处理
我们知道DStream在进行action操作时,会触发job。我们以saveAsTextFiles方法为例:
def saveAsTextFiles(prefix: String, suffix: String = ""): Unit = ssc.withScope {
// 封装了一个保存函数,内部其实调用的RDD的saveAsTextFile
val saveFunc = (rdd: RDD[T], time: Time) => {
val file = rddToFileName(prefix, suffix, time)
rdd.saveAsTextFile(file)
}
// 调用foreachRDD方法遍历RDD
this.foreachRDD(saveFunc, displayInnerRDDOps = false)
}
foreachRDD:它会向DStreamGraph注册,根据返回的当前的DStream然后创建ForEachDStream
private def foreachRDD(
foreachFunc: (RDD[T], Time) => Unit,
displayInnerRDDOps: Boolean): Unit = {
// 它会向DStreamGraph注册,根据返回的当前的DStream然后创建ForEachDStream
new ForEachDStream(this,
context.sparkContext.clean(foreachFunc, false), displayInnerRDDOps).register()
}
register: 向DStreamGraph注册,即向DStreamGraph添加输出流
private[streaming] def register(): DStream[T] = {
// 向DStreamGraph添加输出流
ssc.graph.addOutputStream(this)
this
}
JobGenerator初始化的时候会构造一个timer定时器:
private val timer = new RecurringTimer(clock, ssc.graph.batchDuration.milliseconds,
longTime => eventLoop.post(GenerateJobs(new Time(longTime))), "JobGenerator")
它会启动一个后台线程,不断去调用triggerActionForNextInterval方法,该方法就会不断调用processsEvent方法,并且传递GenerateJobs事件
private def processEvent(event: JobGeneratorEvent) {
logDebug("Got event " + event)
event match {
case GenerateJobs(time) => generateJobs(time)
case ClearMetadata(time) => clearMetadata(time)
case DoCheckpoint(time, clearCheckpointDataLater) =>
doCheckpoint(time, clearCheckpointDataLater)
case ClearCheckpointData(time) => clearCheckpointData(time)
}
}
JobGenerator# generateJobs
调用DStreamGraph的generateJobs方法产生job,然后利用JobScheduler开始提交job集合
private def generateJobs(time: Time) {
// checkpoint所有那些标记为checkpointing状态的RDDs以确保他们的血缘
// 关系会定期删除,否则血缘关系太长会造成栈溢出
ssc.sparkContext.setLocalProperty(RDD.CHECKPOINT_ALL_MARKED_ANCESTORS, "true")
Try {
// 根据时间分配block到batch,一个batch可能你有多个block
jobScheduler.receiverTracker.allocateBlocksToBatch(time) // allocate received blocks to batch
// DStreamDgraph根据时间产生job集合,使用分配的数据块
graph.generateJobs(time) // generate jobs using allocated block
} match {
case Success(jobs) =>
// 如果成功,则提交jobset
val streamIdToInputInfos = jobScheduler.inputInfoTracker.getInfo(time)
jobScheduler.submitJobSet(JobSet(time, jobs, streamIdToInputInfos))
case Failure(e) =>
jobScheduler.reportError("Error generating jobs fortime " + time, e)
PythonDStream.stopStreamingContextIfPythonProcessIsDead(e)
}
// 进行checkpoint
eventLoop.post(DoCheckpoint(time, clearCheckpointDataLater = false))
}
- DStreamGraph的generateJobs根据时间产生job集
def generateJobs(time: Time): Seq[Job] = {
logDebug("Generating jobs for time " + time)
// 根据DStreamGraph的输出流创建job集合
val jobs = this.synchronized {
outputStreams.flatMap { outputStream =>
// 调用DStream的generateJob方法产生job
val jobOption = outputStream.generateJob(time)
jobOption.foreach(_.setCallSite(outputStream.creationSite))
jobOption
}
}
logDebug("Generated " + jobs.length + " jobs for time " + time)
jobs
}
- 然后调用DStream的generateJobs产生job
private[streaming] def generateJob(time: Time): Option[Job] = {
getOrCompute(time) match {
case Some(rdd) =>
val jobFunc = () => {
val emptyFunc = { (iterator: Iterator[T]) => {} }
context.sparkContext.runJob(rdd, emptyFunc)
}
Some(new Job(time, jobFunc))
case None => None
}
}
- 最后提交job集合
提交job集合,遍历每一个job,创建JobHandler,然后JobHandler是一个线程类,在其run方法中会向JobScheduler发送JobStarted事件,从而开始处理job。
private class JobHandler(job: Job) extends Runnable with Logging {
import JobScheduler._
def run() {
val oldProps = ssc.sparkContext.getLocalProperties
try {
ssc.sparkContext.setLocalProperties(SerializationUtils.clone(ssc.savedProperties.get()))
val formattedTime = UIUtils.formatBatchTime(
job.time.milliseconds, ssc.graph.batchDuration.milliseconds, showYYYYMMSS = false)
val batchUrl = s"/streaming/batch/?id=${job.time.milliseconds}"
val batchLinkText = s"[output operation ${job.outputOpId}, batch time ${formattedTime}]"
ssc.sc.setJobDescription(
s"""Streaming job from $batchLinkText""")
ssc.sc.setLocalProperty(BATCH_TIME_PROPERTY_KEY, job.time.milliseconds.toString)
ssc.sc.setLocalProperty(OUTPUT_OP_ID_PROPERTY_KEY, job.outputOpId.toString)
ssc.sparkContext.setLocalProperty(RDD.CHECKPOINT_ALL_MARKED_ANCESTORS, "true")
var _eventLoop = eventLoop
if (_eventLoop != null) {
_eventLoop.post(JobStarted(job, clock.getTimeMillis()))
PairRDDFunctions.disableOutputSpecValidation.withValue(true) {
job.run() //真正开始处理job
}
_eventLoop = eventLoop
if (_eventLoop != null) {
_eventLoop.post(JobCompleted(job, clock.getTimeMillis()))
}
} else {
}
} finally {
ssc.sparkContext.setLocalProperties(oldProps)
}
}
}
private def handleJobStart(job: Job, startTime: Long) {
// 根据时间获取jobSet
val jobSet = jobSets.get(job.time)
// 判断是否已经开始运行
val isFirstJobOfJobSet = !jobSet.hasStarted
// 更新jobset开始时间
jobSet.handleJobStart(job)
if (isFirstJobOfJobSet) {
listenerBus.post(StreamingListenerBatchStarted(jobSet.toBatchInfo))
}
job.setStartTime(startTime)
listenerBus.post(StreamingListenerOutputOperationStarted(job.toOutputOperationInfo))
logInfo("Starting job " + job.id + " from job set of time " + jobSet.time)
}