大数据初学习之MapReduce理论概述
Hadoop-MapReduce分布式计算整理
文章目录
- 分布式开发思维与并行计算思维
- 引例1
- 如何用两次磁盘IO搞定这件事情?分久必合
- 引例2
- 如果改成给十台服务器
- MapReduce思想
- MapReduce
- MapReduce主要思想:分久必合
- MapReduce核心思想
- MapReduce由两阶段组成
- MapReduce计算原理
- Map端
- Reduce端
- MapReduce流程
- Hadoop1.x版本MapReduce自带资源调度器
- ReduceTask在第三个DataNode节点上运行合适吗?
- Hadoop1.x版本总结
- JobTracker作用有哪些
- TaskTracker作用
- Hadoop2.x版本
- yarn架构
- 单点故障问题
- ResourceManager单点故障
- ApplicationMaster单点故障
分布式开发思维与并行计算思维
引例1
假设有一个1T的大文件,这个文件的每一行是一个数字
环境:一台服务器,核数:48core 64G内存
需求:将大文件排序,不管是正序还是倒序
思路:
- 将大文件切成一个个的小文件[一次磁盘IO],(按照行数来切,每个小文件有十万行数据)
- 把每个小文件加载到服务器中排序[一次磁盘IO](小文件之间无序,内部有序)。
- 将小文件归并排序[一次磁盘IO],每个小文件都读到一个Buffer中,然后这些Buffer进行比较进行归并,当Buffer里面没数据了,再继续读磁盘小文件。
磁盘IO:把所有文件读一遍当作一次磁盘IO
如何用两次磁盘IO搞定这件事情?分久必合
思路:
- 1T的文件,根据数值范围来切割大文件。
比如,0-100的放在file1里面,100-200的放在file2里面。如果0-100的数据大于64G怎么办?那就再切一下,切成file1_0和file1_1。小文件之间是有序的,小文件内部无序。 - List item把每个小文件加载到服务器中排序[一次磁盘IO](小文件之间有序,内部也有序)。假设需要的是升序,那么file1,file2,file3合并成大文件,如果需要的是倒序,那么就倒着读一下,直接输出就可以了。如果file1_0和file1_1小文件之间是无序的:进行一次归并。如果这种现象普遍存在,那么就把范围再缩小一点。
引例2
有两个文件,fileA和fileB,分别有十亿条url,每个url是64k
环境:一台服务器,核数:48core 64G内存
需求:找出同时出现在两个文件的url
思路:
- 要把这两个大文件拆成小文件(假设是一千个)。怎么拆?
拆分策略:计算每一个url的hashcode然后与1000取模,决定这一条url进入到哪一个小文件中。保证:相同的url进入同一个小文件中。(一次磁盘IO) - 只需要比对两个file拆出来的对应相同模的小文件。因为hashcode是唯一的。(第二次磁盘IO)
如果改成给十台服务器
多节点的并行计算(多进程多线程计算)
切割fileA可以node1来做,切割fileB可以node2来做。也就是说,切割这一步可以两台服务器并行计算。切出来以后,fileA的0-100号文件对应fileB的0-100号文件给node1,fileA的101-200号文件对应fileB的101-200号文件给node2以此类推。这样每台服务器只用比对100对文件。
MapReduce思想
有三个山头,都种有橡木,红木和樟木。有三个工人,让这三个工人去每个山头上工作(计算找数据)。[为什么不把山头搬到他家(数据找计算)?数据量过于庞大,数据找计算将出现频繁的数据运输,造成较低的计算效率]。有个加工厂,分别加工橡木,樟木和红木的桌子。如何提高效率?采用分久必合思想。
-
删减无用的运输
在各个山头上争取把每一棵树都制作成有用的木材。eg:加工成桌面,桌腿。把废料下脚料扔在山上。 -
减少搬运次数(Combiner)
在山头上进行简单的组装,组装成半成品(假设每个山头的树木不够做一个桌子),减少搬运次数。
Combiner目的:减少每个山头的输出数据,减少网络IO。
[传输的过程最耗时]
- 每个工厂将各个工人的半成品进行组装,得到成品。
注:
在MapReduce中,大山就是一个大文件
每一个山头代表一个block
每一个工人类比成线程(计算)
【进程本身不能计算,进程中的线程提供计算。进程为线程提供了一个环境–CPU,内存,磁盘环境】
总结:MapReduce由Map和Reuce组成。
combiner:工人在每一个山头的组装(处理的是每一个组件进行小组装)
shuffle:将半成品运输到各个工厂(会有网络IO,最耗时间)
reduce:将运输过来的半成品进行大组装(大合并)
MapReduce
MapReduce是一个便于编写程序的可以通过大集群(上千台节点)并行处理TB级的海量数据的并通过可靠稳定的,容错的机制运行的软件框架。
MapReduce主要思想:分久必合
MapReduce核心思想
"相同"的key为一组,调用一次reduce方法,方法内迭代这一组数据进行计算
MapReduce由两阶段组成
MapReduce计算原理
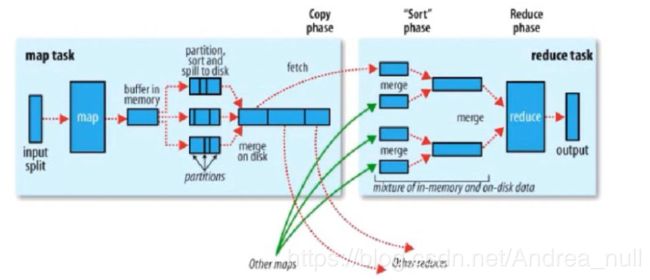
假设计算的数据在HDFS上以block块形式存储。
在上图中,有四个工人(MapTask),三个加工厂(ReduceTask)。
在HDFS里每一个block对应每一个MapTask
Map端
- MapReduce在计算HDFS数据之前会先对文件进行切片(split),默认大小与block一致(128M)。
如果设置切片大小为256M,那么一个切片对应2个block,此时一个MapTask处理2个block。
默认block<–>spilt<–>map task
想要map端的并行度越高:就要让切片越小。
eg:如果把切片设置成64M,那么1/2个block对应一个split。
那么两个MapTask处理一个block数据。
- MapTask处理数据的时候,一条一条的读,读完一条一条计算,计算完把数据写出去。
1)分区: 每一个MapTask把计算结果写到缓冲区之前需要将数据打标签(所谓的分区号:标记是红木橡木还是樟木)。
打标签的目的:为了标记让这条记录将来运送到哪一个ReduceTask中。
默认的分区器叫:HashPartitioner
它是如何进行分区的?根据Map输出的K的HashCode与ReduceTask的个数取余决定。
同一个分区的数据都运送给某一个ReduceTask来处理。
所以相同的K一定会运到某一个ReduceTask来处理。
注:Map的输出结果是
2)每一个MapTask把数据写到内存缓冲区中去。这个内存缓冲区默认100M。
实际上Buffer内部会把这100M切成两份:80M和20M
为什么切成两份?在溢写之前要排序在之前还会做combiner(半成品的封装)
80%叫做溢写比例
往Buffer中写入数据超过80M就会溢写到磁盘上。如果Buffer满了,进行combiner,sort。
顺序:
一)combiner,先组装成大文件
二)根据分区号(partitionId)排序,如果分区号相同,根据K排序。
如果K是自定义的对象,那么这个自定义的对象必须实现compareable接口,实现里面的compare方法。
三)把数据溢写到磁盘上,形成磁盘小文件。
在这个过程,会把80M内存封锁住,谁也操作不了写不进来数据。
这个时候,就MapTask往剩下20M里面写数据。(防止计算阻塞执行,让计算并行起来)
MapTask在计算过程中有n多次溢写。
溢写产生的小文件都是有分区的而且根据分区号(PartitionId)排序的。
每个分区内部的数据都是通过K排序的。 - 基于磁盘将磁盘小文件合并成大文件(merge on disk)[在图片上,每一个大文件有三个分区]当磁盘小文件数大于3个的时候进行combiner。
在这个过程中还可能进行小组装(形成其它半成品)
每一个磁盘小文件的第一个分区合并成大文件的第一个分区
在合并的过程,还要进行排序(每一个分区内部是有序的,只需要根据分区号进行归并排序)
combiner的目的:ReduceTask来拉数据的时候,减少数据量,提高效率
Reduce端
1.fetch 默认启动五个进程去拉,每个进程的失败间隔时间是300s
Reduce端工作需要去Map端拉取相应分区的数据放到Reduce端的内存(1G*0.7)中去。
拿来之后,进行写内存(放到内存中)[注:从Map端拉来的数据都是有序的]
默认大小是1G的70%也就是越700M。超过660M就会溢写。
溢写之前要进行简单的排序(溢写成磁盘小文件)
把一个个的小文件合并成大文件(merge合并的过程中也会进行排序–>为了方便分组,提高分组效率)
排完序以后要对大文件进行分组(相同的K为一组–因为是局部有序,所以一次磁盘IO就可以完成分组group)
每组数据调用一次大合并
这个过程一共有四次排序。
Map端:2次
Reduce端:2次
分组以后,每一组数据调用一次reduce函数,进行一次大组装
组装完之后进行输出,在磁盘上产生文件。
一个分区会分成n多组数据,每一组数据调用一次reduce函数
第二组数据调用reduce函数追加到第一组数据的结果中。
也就是说,每一个分区对应一个ReduceTask,每一个ReduceTask产生一个结果文件。
可以自定义的过程:
1.分区器
2.combiner(如果自定义一个key,实现WritableComparable接口)
3.sort
4.merge-sort
5.group
实现自定义排序器、分组器,需要继承同一个抽象类WritableComparater实现里面的compare方法。
如果要实现分区器,要实现Partitioner
MapReduce流程
MapReduce是一个计算框架
基于MapReduce计算框架按照它的标准规范就可以写出来一个Application应用程序
这个应用程序就存在一些分布式的并行的功能,可以在集群中并行,分布地式计算
要想在集群中并行,分布地式计算,需要向资源调度器申请资源。
资源调度器的管事的叫做主节点,
它分配完资源之后,需要任务调度器来调度任务到数据所在节点执行。
之后才可以分布式的,并行计算。
Hadoop1.x版本MapReduce自带资源调度器
资源调度器都是主从架构的
它自带的资源调度器,主叫JobTracker,有资源调度管理功能。
它的从节点叫做TaskTracker,具备资源调度的功能。
客户端可以基于MapReduce应用框架可以写出来一个Application应用程序。
- Application应用程序要在集群里面运行,需要找到JobTracker
在提交的时候要把应用程序打成jar包,把这个jar包给JobTracker
然后告诉JobTracker这个应用程序想在集群中运行 - 由于在计算中计算要向数据移动,所以JobTracker要找到NameNode,问一下这个程序计算所需要的数据都在哪个节点上。然后NameNode返回一批block的地址。[默认每一个block有三个地址,一份源数据,两个备份]
- JobTracker这时候会拿到一个列表,然后向有数据的TaskTracker(DataNode)发送一条消息,告诉它,给我分配一点资源,我要分发任务(线程)去运行。[注:进程就是提供的一个环境,真正执行任务的还是线程]。
- 这样有数据的TaskTracker就会启动一个DataNode进程,有了进程之后就相当于给分配了资源,这样就可以把任务(Task)分配到节点上运行了。
- 假设分发过来的任务叫做MapTask,MapTask计算完之后会产生一堆磁盘文件。[每一个MapTask会产生一个文件]
- 之后会令ReduceTask执行,ReduceTask在计算之前会去各个大文件中拿到相应分区的数据。
ReduceTask在第三个DataNode节点上运行合适吗?
不合适。因为如果这样计算,那么所有的数据都要走网络IO,最好把ReduceTask调度到第一个或者第二个节点上运行。
因为有一部分数据在本地,剩下一部分数据走网络IO。这样效率高。
Hadoop1.x版本总结
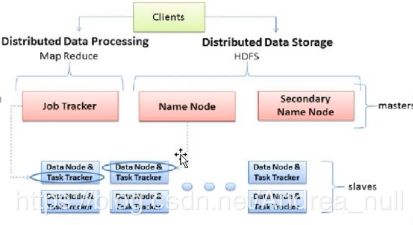
JobTracker作用有哪些
- 资源调度主节点
- 任务调度主节点
- 资源抢夺和资源隔离问题
1)JobTracker压力很大,容易单点故障。需要解决单点故障。
其它框架的应用程序在这个框架运行得单独实现一套TaskTracker和JobTracker,存在资源抢夺问题。
2)资源隔离问题:每一套JobTracker管理的资源都是集群的所有资源,现在提交了一个MapReduce应用程序它把所有的资源都给占了,但是Spark实现的那套JobTracker认为资源还是满的。所以运行不起来。
TaskTracker作用
1.作为从节点,自身资源调度节点
2.和JobTracker心跳,汇报资源,获取Task
Hadoop2.x版本
为解决Haoop1.x版本的各种问题,开发了一个单独的资源调度框架叫做yarn。yarn只负责资源调度。任务调度是由自己的计算框架来实现。实现可插拔。
整个集群只需要一套yarn就可以解决以上诸多问题。
yarn架构
Yarn也是一个主从架构
它的主叫做ResourceManager(资源管理的主节点),从叫做NodeManager(资源管理的从节点)。
主节点怎么管从节点?利用心跳来管。他们直接保持心跳(通信)。
在客户端节点上基于MapReduce计算框架写出来一套Application应用程序,之后要提交到集群中运行。
假设:处理的文件在HDFS上只有两个block
1.client找NameNode要计算所需要的数据的每一个block的位置,之后client会生成一个列表,假设列表如下:
![]()
我们希望第一个MapTask在node01,03或者04上运行,如果这三个节点都满了没有资源可用了,就找一台同机架的节点
如果同机架的也满了,就随机找一个。(数据本地化的降级)
下一个MapTask也一样。
2.client拿着列表,向ResourceManager发送请求[请求启动一个ApplicationMaster]
ApplicationMaster:用来做任务调度
3.ResourceManager掌握了整个集群的资源情况,那么它就知道哪一个节点可以启动一个ApplicationMaster进程。假设第一个NodeManager有充足的资源,此时ResourceManager会跟第一个NodeManager说在你的节点启动一个容器(Container)[这个容器隔离出来一块资源],然后在你的Container中启动一个ApplicationMaster进程。
4.client将生成的列表交给ApplicationMaster(任务调度器)
5.ApplicationMaster(任务调度器)拿着列表去向ResourceManager申请资源
6.假设计算block1的MapTask在node03上有资源,计算block2的MapTask在node02上有资源,则分别启动一个Container。
MapTask1会计算block1的数据,还会计算block2的一点数据。但启动位置不会把block2的位置考虑进来。因为有可能适得其反。
7.node01的ApplicationMaster往02和03的Container中分发任务。假设任务是map task,map task是线程,会运行在刚启动的进程yarn-child里。
8.ApplicationMaster会监控yarn-child运行的进程map task的运行进度。将监控的进度返回给客户端。
9.客户端在页面能看到每一个任务的运行进度。
单点故障问题
ResourceManager单点故障
ResourceManager:负责资源调度
所以搞一个备用的ResourceManager。
ResourceManager的高可用是借助zookeeper做的。
ApplicationMaster单点故障
ApplicationMaster:复责任务调度
ApplicationMaster一旦挂掉,整个任务就停止了。
此时,ResourceManager会重新启动一个ApplicationMaster。
如果Spark也想运行在yarn,必须实现yarn对外暴露的ApplicationMaster接口。