Spark 完全分布式集群搭建过程
Spark2.1 +Hadoop2.6 搭建分布式集群
本篇博客由博主Ashely个人原创,如有转载,请注明出处:
目录
- Spark21 Hadoop26 搭建分布式集群
- 目录
- 实验环境
-
- 1 服务器上启动三台虚拟机
- 2 软件版本
-
- 总体流程
-
- 1 修改主机名hosts
- 2 安装基础环境jdk和scala
- 3 配置ssh无密码访问
- 4 搭建hadoop分布式集群
- 5 搭建spark分布式集群
-
- 一 修改主机名和hosts
- 1 更改主机名
- 2 修改hosts
- 二 安装基础环境Java和scala
- 1 Java环境搭建
- 2 scala环境搭建
- 三 ssh无密码验证配置
- 1 配置master无密码登录所有slave
- 2 配置slave无密码登录master
- 四 Hadoop 265 完全分布式搭建
- 五 Spark 210完全分布式环境搭建
实验环境
1.1 服务器上启动三台虚拟机
ubuntu@vm06 192.168.110.106 master
ubuntu@vm05 192.168.110.105 slave1
ubuntu@vm04 192.168.110.104 slave2
1.2 软件版本:
Hadoop2.6.5 + Spark2.1.0 + Scala2.1.6
总体流程
1. 1 修改主机名(hosts)
--> 所有节点都执行
2. 2 安装基础环境(jdk和scala)
--> 所有节点都执行
3. 3 配置ssh无密码访问
--> master -> slave1、slave2 ; slave1、slave2 -> master
4. 4 搭建hadoop分布式集群
--> master先执行,再scp到slave1、slave2; 还要改些配置
5. 5 搭建spark分布式集群
--> master先执行,再scp到slave1、slave2; 还要改些配置
一. 修改主机名和hosts
1.1 更改主机名
ubuntu@vm06:~$ sudo vim /etc/hostname改成master //其他两个分别改为slave1 和slave2
注意:本文的主机名全部以小写字母开头,后文在配置环境时注意不要误用大写!
1.2 修改hosts
ubuntu@vm06:~# sudo vim /etc/hosts//将原文件(127.0.0.0 localhost)下面添加以下信息:
192.168.110.106 master
192.168.110.105 slave1
192.168.110.104 slave2ubuntu@vm06:~# sudo source /etc/hosts//退出后重启虚拟机
ubuntu@vm06:~# sudo reboot//分别对集群中的所有节点进行以上相似的设置
![]()
二. 安装基础环境(Java和scala)
-对所有节点安装java和scala
2.1 Java环境搭建
1)下载jdk-1.8并解压到 /usr/local
ubuntu@master:~$ sudo wget .............
ubuntu@master:~$ sudo tar -zxvf jdk-8u152-linux-x64.tar.gz -C /usr/local/2)添加java环境变量,在/etc/profile中添加:
ubuntu@master:~$ sudo vim /etc/profileexport JAVA_HOME=/usr/local/jdk1.8.0_152
PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=.:$JAVA_HOME/lib/rt.jar
export JAVA_HOME PATH CLASSPATH3)保存后刷新配置
ubuntu@master:~$ source /etc/profile
2.2 scala环境搭建
1)下载scala安装包scala-2.10.6.tgz安装到 /usr/lib
ubuntu@master:~$ sudo tar -zxvf scala-2.10.6.tgz -C /usr/lib/2)添加Scala环境变量,在/etc/profile中添加:
ubuntu@master:~# sudo vim /etc/profileexport SCALA_HOME=/usr/lib/scala-2.10.6
export PATH=$SCALA_HOME/bin:$PATH3)保存后刷新
ubuntu@master:~# source /etc/profile![]()
三. ssh无密码验证配置
-对所有节点安装ssh
ubuntu@master:~$ sudo apt-get install ssh3.1 配置master无密码登录所有slave
以下是在master节点上执行以下命令:
// 1)在master节点上生成密码对
ubuntu@master:~$ ssh-keygen -t rsa -P ''// Enter 继续
//生成的密钥对:id_rsa和id_rsa.pub存储在”/home /ubuntu/.ssh”目录下(注意可能会不同)


// 2)把id_rsa.pub追加到授权的key里面去
ubuntu@master:~$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys// 3)修改ssh配置文件”/etc/ssh/sshd_config”的下列内容
ubuntu@master:~$ sudo vim /etc/ssh/sshd_config//将以下内容的注释去掉:

// 4) 重启ssh服务,才能使刚才设置有效
ubuntu@master:~$ service sshd restart// 5) 验证无密码登录本机是否成功。
ubuntu@master:~$ ssh localhost//注意:无密码登录成功后,使用Ctrl+D退出当前登录,防止嵌套登录
// 6)把公钥复制到所有的Slave机器上
ubuntu@master:~$ scp ~/.ssh/id_rsa.pub ubuntu@slave1:~/ #注意不能有空格
ubuntu@master:~$ scp ~/.ssh/id_rsa.pub ubuntu@slave2:~/ #注意直接放在主目录下 //可以到slave节点的机器中看一下 ~/.ssh/ 是否多处了一个内容id_rsa.pub
-以下是在slave1 (192.168.110.105)节点的配置操作
// 1)将Master的公钥追加到Slave1的授权文件”authorized_keys”中去。
ubuntu@slave1:~ $ cat ~/id_rsa.pub >> ~/.ssh/authorized_keys// 2) 修改”/etc/ssh/sshd_config”,具体步骤参考前面Master设置的第3步和第4步。
ubuntu@slave1:~/.ssh$ sudo vim /etc/ssh/sshd_config//注释掉一些内容,重启服务
// 3)用master使用ssh无密码登录slave1
ubuntu@master:~$ ssh 192.168.110.105 或者是 ssh ubuntu@slave1// 4)把slave节点中的”/home/ubuntu/”目录下的”id_rsa.pub”文件删除掉。
ubuntu@slave1:~/.ssh$ rm -r ~/id_rsa.pub //重复上面的4个步骤把Slave2服务器进行相同的配置
3.2 配置slave无密码登录master
-以下是在slave1节点(192.168.110.105)的配置操作。
// 1)创建”Slave1”自己的公钥和私钥,并把自己的公钥追加到”authorized_keys”文件中,执行下面命令:
ubuntu@slave1:~/.ssh$ ssh-keygen -t rsa -P ''
ubuntu@slave1:~/.ssh$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys // 2)将slave1节点的公钥”id_rsa.pub”复制到Master节点的”/root/”目录下。
ubuntu@slave1:~/.ssh$ scp ~/.ssh/id_rsa.pub ubuntu@master:~/ 以下是在master节点的配置操作
// 1)将Slave1的公钥追加到Master的授权文件”authorized_keys”中去。
ubuntu@slave1:~ $ cat ~/id_rsa.pub >> ~/.ssh/authorized_keys // 2)删除Slave1复制过来的”id_rsa.pub”文件。
ubuntu@slave1:~ $ rm -r ~/id_rsa.pub // 配置完成后测试从Slave1到Master无密码登录。
ubuntu@slave1:~ $ ssh 192.168.110.106 按照上面的步骤把Slave2和Master之间建立起无密码登录。
- 这样,Master能无密码验证登录每个Slave,每个Slave也能无密码验证登录到Master。
四. Hadoop 2.6.5 完全分布式搭建
-以下是在master节点上的操作
1)下载hadoop 2.6 并解压到/opt/
ubuntu@master:~$ wget ………………..
ubuntu@master:~$ sudo tar -zxvf hadoop-2.6.5.tar.gz -C /opt/ 2)修改配置文件,添加以下内容
ubuntu@master:~$ sudo vim /etc/profile export HADOOP_HOME=/opt/hadoop-2.6.5/
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_ROOT_LOGGER=INFO,console
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"修改完成后执行:
ubuntu@master:~$ source /etc/profile3)修改hadoop的相关配置
修改JAVA_HOME 如下:
ubuntu@master:/opt/hadoop-2.6.5$ sudo vim ./etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_152修改$HADOOP_HOME/etc/hadoop/slaves,将原来的localhost删除,改成如下内容:
ubuntu@master:/opt/hadoop-2.6.5$ sudo vim ./etc/hadoop/slavesslave1
slave2修改$HADOOP_HOME/etc/hadoop/core-site.xml
ubuntu@master:/opt/hadoop-2.6.5$ sudo vim ./etc/hadoop/core-site.xml
fs.defaultFS
hdfs://master:9000
io.file.buffer.size
131072
hadoop.tmp.dir
/opt/hadoop-2.6.5/tmp
修改$HADOOP_HOME/etc/hadoop/hdfs-site.xml
ubuntu@master:/opt/hadoop-2.6.5$ sudo vim ./etc/hadoop/hdfs-site.xml
dfs.namenode.secondary.http-address
master:50090
dfs.replication
2
dfs.namenode.name.dir
file:/opt/hadoop-2.6.5/hdfs/name
dfs.datanode.data.dir
file:/opt/hadoop-2.6.5/hdfs/data
复制template,生成xml,命令如下:
ubuntu@master:/opt/hadoop-2.6.5/etc/hadoop$ cp mapred-site.xml.template mapred-site.xml修改$HADOOP_HOME/etc/hadoop/mapred-site.xml
ubuntu@master:/opt/hadoop-2.6.5/etc/hadoop$ sudo vim mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
master:10020
mapreduce.jobhistory.address
master:19888
修改$HADOOP_HOME/etc/hadoop/yarn-site.xml
ubuntu@master:/opt/hadoop-2.6.5/etc/hadoop$ sudo vim yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.address
master:8032
yarn.resourcemanager.scheduler.address
master:8030
yarn.resourcemanager.resource-tracker.address
master:8031
yarn.resourcemanager.admin.address
master:8033
yarn.resourcemanager.webapp.address
master:8088
4)复制master节点的hadoop文件夹到slave1和slave2上
scp -r /opt/hadoop-2.6.5 ubuntu@slave1:/opt如果无法复制,提示permission deny之类的,就将hadoop-2.6.5先复制到slave节点的用户主目录下,slave节点再从主目录复制到自己的 /opt/
ubuntu@master:~$ sudo scp /opt/hadoop-2.6.5 ubuntu@slave1:~
ubuntu@slave1:~$ sudo mv hadoop-2.6.5 /opt5)在Slave1和Slave2上分别修改/etc/profile,(hadoop的配置信息) 过程同master一样
ubuntu@master:~$ hadoop namenode -format启动集群
ubuntu@master:~$ /opt/hadoop-2.6.5/sbin/start-all.sh6)查看集群是否启动成功: jps

SecondaryNameNode是NameNode的备份,本文将其都配置master节点上。(一般是配置在不同的节点上,以助于主节点挂掉的时候对它恢复)
slave1和slave2都仅作为计算节点(DataNode)
-至此hadoop的完全分布式环境搭建成功。
五. Spark 2.1.0完全分布式环境搭建
-以下操作都是在master节点进行
1)下载二进制包spark-2.1.0-bin-hadoop2.6.tgz
ubuntu@master:~$ wget …………2)解压到相应目录
ubuntu@master:~$ tar -zxvf spark-2.1.0-bin-hadoop2.6.tgz -C /opt
ubuntu@master:~$ mv /opt/spark-2.1.0-bin-hadoop2.6 /opt/spark-2.13)修改相应的配置文件
修改/etc/profie,增加如下内容:
ubuntu@master:/opt$ sudo vim /etc/profileexport SPARK_HOME=/opt/spark-2.1/
export PATH=$PATH:$SPARK_HOME/bin复制spark-env.sh.template成spark-env.sh
ubuntu@master:/opt/spark-2.1/conf$ sudo cp spark-env.sh.template spark-env.sh修改$SPARK_HOME/conf/spark-env.sh,添加如下内容.(标注需要改为自己的版本)
ubuntu@master:/opt/spark-2.1/conf$ sudo vim spark-env.shexport JAVA_HOME=/usr/local/jdk1.8.0_152
export SCALA_HOME=/usr/lib/scala
export HADOOP_HOME=/opt/hadoop-2.6.5
export HADOOP_CONF_DIR=/opt/hadoop-2.6.5/etc/hadoop
export SPARK_MASTER_IP=192.168.110.106
export SPARK_MASTER_HOST=192.168.110.106
export SPARK_LOCAL_IP=192.168.110.106
export SPARK_WORKER_MEMORY=1g
export SPARK_WORKER_CORES=2
export SPARK_HOME=/opt/spark-2.1
export SPARK_DIST_CLASSPATH=$(/opt/hadoop-2.6.5/bin/hadoop classpath)复制slaves.template成slaves
ubuntu@master:/opt/spark-2.1/conf$ sudo cp slaves.template slaves修改$SPARK_HOME/conf/slaves,在原来的localhost下面改为如下内容:
ubuntu@master:/opt/spark-2.1/conf$ sudo vim slavesmaster
slave1
slave2(注意,如果不删除之前的localhost,spark搭建完成之后,会出现多个worker,如下图)

4)将配置好的spark文件复制到slave1和slave2节点
ubuntu@master:/opt$ scp -r /opt/spark-2.1 ubuntu@slave1:~ //拷贝整个目录
ubuntu@master:/opt$ scp -r /opt/spark-2.1 ubuntu@slave2:~
ubuntu@slave1:~$ sudo mv spark-2.1/ /opt
ubuntu@slave2:~$ sudo mv spark-2.1/ /opt5)修改slave1和slave2配置。
ubuntu@slave1:~$ sudo vim /etc/profile在slave1和slave2上分别修改/etc/profile,增加Spark的配置,过程同master一样。
export SPARK_HOME=/opt/spark-2.1/
export PATH=$PATH:$SPARK_HOME/bin在save1和save2修改$SPARK_HOME/conf/spark-env.sh
ubuntu@master: $ sudo vim /opt/spark-2.1/conf/spark-env.sh将export SPARK_LOCAL_IP=192.168.110.XXX改成slave1和slave2对应节点的IP
6) 在Master节点启动集群
先启动hadoop,在启动spark
ubuntu@master:/opt$ /opt/hadoop-2.6.5/sbin/start-all.sh
ubuntu@master:/opt$ /opt/spark-2.1/sbin/start-all.sh7)查看集群是否启动成功:jps
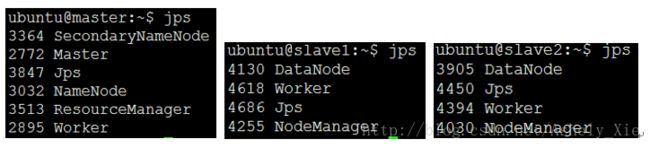
-master节点在hadoop的基础上新增了:Master
-slave在Hadoop的基础上新增了:Worker
ubuntu@master:/opt/spark-2.1$ ./bin/spark-shell
-至此Spark的完全分布式环境搭建成功