Kaggle搭积木式刷分大法:特征工程部分
專 欄

这两天在忙着刷Kaggle梅塞德斯奔驰生产线测试案例,刚刚有了些思路,还是用管道方法达了个积木。这才有空开始写第二篇文章。(吐个槽,Kaggle上面的很多比赛,比的是财力。服务器内存不行,或者计算速度不够就是浪费时间。)
上回说道,用搭乐高积木的方式就可以多快好省的刷Kaggle分。整个过程可以分成两个部分,一是特征工程,二是管道调参。
今天这篇文章,主要分享和讨论的是特征工程这部分。 主要使用的是Pandas 的表级别函数Pipe 。
这个Pipe就像是乐高小火车。有火车头,火车身,火车厢。根据需要连接起来就是一辆漂亮的小火车。有什么功能,有多少功能,全看各种组合的方式。

首先,火车头:
在Kaggle 比赛中,有原始数据,train, 和test 部分。 把这两部分合并在一起。作为火车头的输入。以House Price 为例:

火车头有了,要搞清楚火车往哪里开?
在House Price 比赛中,对应为目标是什么?方向盘是什么? 终点到了后送什么货?
目标是 预测Test 数据集中的SalePrice (房屋销售价)
方向盘(或者说衡量标准)是 Root-Mean-Squared-Error (RMSE) 均方根误差
到站后,要将货物送出。一个文件,两列,一列是ID, 另一列是机器学习后预测出来的房屋销售价。 RMSE值越小,则越好。
这个比赛要在Kaggle拿到好名次,需要方向盘对准,要把RMSE值将下来,降低预测的均方根误差。
注:比赛方也特别注明了会用log转换消除太贵或太便宜导致的误差)
下面来看看目标的分布情况(预测房屋售价的变量分布图)

如果是老司机的话,基本上可以看出来如下几个特点:
1、基本上是正态分布(如果不是,就可以洗洗睡了,或者要重新让数据变成正态分布)
2、长尾, 尤其是右边(不是完美的正态, 看起来有清洗工作要做)
3、可能存在Outliers(异常点),特别是60万以上的房价(能处理就处理,不能就粗暴的说,我没看见。 哈哈)
4、用KDEPlot其时间能看见多个核。(在梅塞德斯奔驰比赛中,有人用聚类方法提炼出特征,也可以提高比分0.0X。由于提前引入了预测功能, 不太符合我简约的观点。 所以我的这个分享中没有专门涉及。)
接下来,火车身:
如果说combined Dataframe是火车头的输出,那么Pandas Pipe就是火车身的输入。 火车身好长,可以放很多车厢。 一节连着一节。每一节的输出是上一节的输入,直到最后。
Pandas Pipe可以作为火车身,每一个函数可以向乐高积木一样,插在一个pipe 里面。
Pipe是Pandas 里面一个Tablewise的函数(v16.2的新功能原厂说明链接)。
比较一下,下面两种方法,哪种更加简洁和易于理解?
函数方法

Pipe大法

尽管看起来很简洁,不过非常不起眼,貌似也没apply, map, group等明星函数受到重视。其实原厂还有一个例子,pipe就是用来做statsmodel回归特征工程的前期清洗。不过当时,我没有特别留意。 直到,Kaggle 比赛的House Price,出现瓶颈。
-
local CV及pulic board成绩不稳定上升。 我刷Kaggle 出现了成绩上上下下,结果非常不稳定时。我想Pipe 把各种功能放在一起,会不会好一些?
-
调参太费时间(每次以小时计算,并且特征工程结果稍微有些改变,优化好的参数又要重新再调一遍),貌似特征工程差之毫厘,调参的参数和性能,预测的结果也会谬之千里。
-繁杂的程序,导致内存经常用光。基本上用上一会儿,就要重新启动Jupyter 的 Kernel来回收内存。 (尤其是我租的阿里云服务器只有1核1G内存+2G虚拟内存。用硬盘虚拟内存。物理内存用完后, 一个简单的回归算法也能算上几分钟时间)
这是,Pandas pipe(原厂说明链接) 重新回到了我的视野。
pipe、pipe、pipe,重要的事情说三遍。
比较早的时候,我学会了用Sklearn的pipeline和Gridsearch 一起调参,调函数,那个功能之强大是谁用谁知道。
只要备选参数设好,备选算法设好,就交给计算就可以。所以特别喜欢pipe这类自动化的东西。 可以把苦脏累的活一下子变成高大上的,可以偷懒的活。训练虽然花时间,还是有pipeline的套路可以使用。
不过在发现和利用Pandas 的pipe之前,特征工程简直就是苦脏累的活。例如:
-
大量的特征需要琢磨,
尤其是House Price 这个案例,一共有80个特征,1个目标(售价)。 为了搞明白美国的房价到底和那些有关,我还特别读了好几篇美国的房价深度分析报告。然并卵,这些特征还会互相影响。
-
绝大多数的特征都不知道琢磨后是否有价值,(单变量回归)
例如,房子外立面材料,房间的电器开关用的什么标准,多少安培等等等,Frontage大小,宗土图形状等等, 贷款是否还清了,
-
更不知道和其他特征配合后结果会如何。(多元变量回归)
街区,成交的月份,年份(中间还有07,08年经济危机),房屋大小,宗土面积互相关关联。
-
是不是有聚类的情况(非监管内机器学习方法)
前两天刚学了一个知识,用Kmeans方法可以挖掘出来新的特征。这种特征方法不是基于经验和知识,而仅仅是依赖于机器学习。
插句话,特征工程,尤其本文后面附录的的特征工程函数,大量依赖于个人的经验和知识水平,老司机和新司机的特征工程结果会差别很大。 基于机器学习的特征工程,应该是未来的一个趋势。前两个月在网上看到以为百度前搜索广告推广工程师发的文章。讲的就是百度在2010年前后的变化,之前还是比较依赖于人工的特征工程。后来特征工程太多,人工完全无法适应,他用类似的Kmeans方法作了聚类方法的特征工程(希望我没记错)。
上面说了4中特征工程的苦脏累。 我在House Price 比赛中全都碰到了。 前期还有点兴趣,后期简直是乏味。 在加上我的机器学习环境只有 1核1G内存的Centos阿里云主机。经常调试就内存用光来,或者变成用硬盘虚拟内存,慢的无法忍受。
Pandas pipe来了, 简单,有效。 可以有效地隔离,有效地连接,并且可以批量产生大量特征工程结果组合。
上面唠叨了许多Pipe的文字观点,也许读者已经有点烦了,下面再上两张积木的照片,来图示比较积木和pipe的关系。

Pipe 就像乐高小火车积木中的车身,本身没有任何功能,但是有很好的输入、输出机制

车身搭上一个积木,小火车好玩。Pipe也要装入特征工程函数,才有用

两个或者更多车身积木连在一起,就变成长长的火车身。两个或者多个pipe(装入特征函数)就变成了特征工程管道
接下来,我们来看看,这个积木方法是否能够解决特征工程中4个问题?
-
大量的特征需要琢磨,
一个特征就来一个pipe。pipe里面放对应的特征函数。多个特征就用多个pipe.
虽然大量的特征依然需要逐一琢磨。但是pipe可能带入项目管理中WBS工作分解的思路。把多个特征分解给不同的人(不同领域有不同的专家)来做,最后用pipe链接起来。
-
绝大多数的特征都不知道琢磨后是否有价值,(单变量分析)
pipe分解了特征工作后,每一个具体的特征函数,可以深入的使用本领域的方法来设kpi和指标,在函数级别确定是否有价值,或者设定处理的量纲,过滤级别等等。
-
更不知道和其他特征配合后结果会如何。(多元变量回归)
pipe的强处就在这里。搭积木呀,简单的各种pipe连在一起就好。甚至还可以专门做一个测试成绩的pipe.在pipes的结尾放一个快速测试函数(例如:测试R2)就可以方便快速的得到这次特征工程大致效果。
注:
回归类比赛,成绩通常是两种:R2 或者是 MSE以及其变种(RMSE,AMSE等)
分类内比赛,成绩类型比较多:ACCURACY,PRECISE,F1,MUTUAL等等。
SKLEARN的成绩评估函数介绍 -比较详细
-
是不是有聚类的情况(非监管内机器学习方法)
简单,做一个聚类的特征函数,然后用一个pipe装起来就好。
下面,开始无聊的代码时间吧!
机器环境:
硬件- 阿里云最便宜一款 -1核 1GB(共享基本型 xn4,ecs.xn4.small)(
系统 , Centos 7(虚拟内存2G)
Python: 3.6, Jupyter notebook 4.3, 用Anaconda装好了常见的科学计算库。
手工装了:XGBoost(kaggle刷分利器之一) , lightbm 库(微软开源,速度比XGBoost快)。有两上面这两个库,sklearn 里面的gradientboost就没有必要用了,太慢了,score也不如这两个库好。
1、导入函数和Pandas库

2、导入数据,准备combined数据集。做好火车头

train data shape: (1460, 81)
test data shape: (1459, 80)
combined data shape: (2919, 81)
数据集:train 1460个,test,1459个,特征为80个,另外一个是需要预测的目标(SalePrice)
3、Exploring Data analysis 数据探索分析
3.1 要事第一,先看看目标数据情况(Y -SalePrice)

文章开头已经介绍过了,销售价格是正态分布,但是长尾(high skews)且有离散点(outliers)
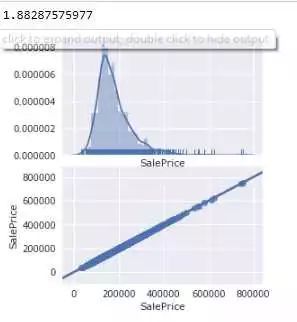
3.2 特征分析 (X), 80个,每列代表了一个特征
3.2.1 偏度分析 - 销售价格由偏度角度,那么就先对特征检查一下偏度。


看起来蛮厉害,前面20个特征偏度都超过了1.36。后期需要处理

3.2.2 缺失值分析



有35个数据都有缺失值情况。 大多数机器学习算法要求不可以有缺失值。 因此,处理缺失值是 必要工作之一。

总结:初步EDA了解到:
1.有偏度 - 需要处理。通常是用log1p (提分关键)
2.有缺失 - 需要填充或者删除,通常用均值或者中指,或者用人工分析(人工分析是提分关键)
3.有类别变量 - 需要转换成数值 (个人感觉刷近前20%关键)
(此处没有做EDA, 直接看data_description.txt文件)
4、准备pipe,装载特征函数,小火车出发啦!!!

为了演示,我定义三个pipes, 每个pipes里面都有若干个特征处理函数和一个快速测试R2(越高越好,最大值是1)的函数。实际刷分时更多,加上不同的特征函数参数,做的pipes组合大概至少几十种。
为了对齐美观,用bypass函数来填充空白的地方。用一个列表,将这三个pipe放入。
现在三辆火车准备出发,都在车站等候待命。 他们分别是简单型,自定义型(部分特征转换成有序的category类型),和概念型(提炼并新增加房屋每平米单价系数)。

好了,小火车启动了,发车。

精简的结果如下:

三个pipes的r2(默认参数,无优化调参)结果分别是
0.729, (填充均值)
0.7390,(自定义填充,和类型转换)
0.7910(增加单价的特征工程)
那么在这一步,我们可以初步看到三个特征工程的性能。并且文件已经输出到hd5格式文件。后期在训练和预测时,直接取出预处理的文件就可以。
好了,特征工程到这里就完成了。这三个小火车PIPES的R2结果不是最好,只能说尚可。都保留下来。可以进入训练,优化,调参,集成的阶段了。本文也就写完了。

长按扫描关注Python中文社区,
获取更多技术干货!
Python 中 文 社 区
Python中文开发者的精神家园
合作、投稿请联系微信:
pythonpost
1MEwnaxmMz7BPTYzBdj751DPyHWikNoeFS
