搭建大数据集群架构Hadoop+Hive+Hbase+Spark+Zookeeper+Phoenix+Sqoop+Flume+Kafka+Azkaban
大数据集群搭建
目录
-
概叙 4
1.1 引言 4
1.2 集群拓扑图 5
1.3 整体架构图 5
1.4 设备选型 6
1.5 版本选择 6
1.6 功能分布 7 -
集群基础配置 7
2.1修改主机名 7
2.2 hosts主机名IP映射文件修改 7
2.3关闭防火墙 8
2.4 配置免秘钥SSH 8
2.5 Jdk安装 8
2.6 Mysql安装 8 -
集群组件配置 9
3.1 Hadoop配置 9
3.1.1 core-site.xml 9
3.1.2 hdfs-site.xml 9
3.1.3 mapred-site.xml 10
3.1.4 yarn-site.xml 10
3.1.5 hadoop-env.sh 11
3.1.6 Slaves 11
3.1.7 启动hadoop 11
3.2 Hive配置 12
3.2.1 hive-site.xml 12
3.2.2 mysql驱动包 12
3.3 Zookeeper配置 12
3.3.1 zoo.cfg 13
3.3.2 启动zookeeper 13
3.4 Hbase配置 13
3.4.1 hbase-env.sh 13
3.4.2 hbase-site.xml 13
3.4.3 regionservers 14
3.5 Phoenix配置 14
3.5.1 jar包替换 14
3.5.2 配置文件替换 15
3.5.3 启动 15
3.6 Sqoop配置 15
3.6.1 sqoop-env.sh 15
3.6.2 mysql驱动包 15
3.7 Flume配置 16
3.7.1 flume-env.sh 16
3.8 Kafka配置 16
3.8.1 server.properties 16
3.9 Spark配置 16
3.9.1 spark-env.sh 16
3.9.2 slaves 16
3.10 Azkaban配置 17
3.10.1 azkaban-sql-script-2.5.0.tar.gz 17
3.10.2 配置时区以及SSL 17
3.10.3 azkaban-web-server-2.5.0.tar.gz 18
3.10.4 azkaban-executor-server-2.5.0.tar.gz 19
4.调优和测试 20
4.1 集群调优 20
4.1.1 yarn-site.xml 20
4.1.2 mapred-site.xml 21
4.2 集群测试 21
4.2.1 MapReduce测试 21
4.2.2 Hive创建测试 21
4.2.3 Sqoop操作测试 22
4.2.4 Kafka操作测试 22
4.2.5 Phoenix操作测试 23
4.2.6 Spark操作测试 24 -
概叙
1.1 引言
出于平台业务需要,现需搭建一套大数据开发集群,以下是大数据环境选型以及组建分配。
1.2 集群拓扑图
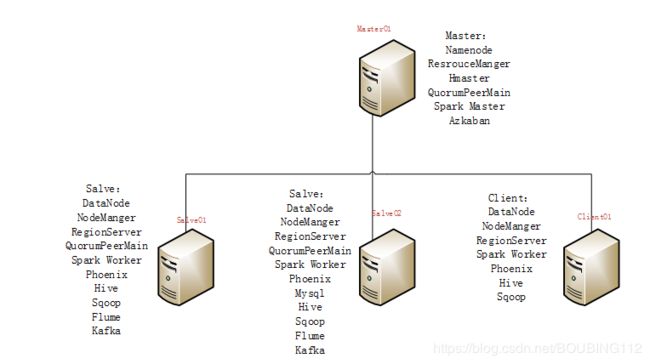
1.3 整体架构图
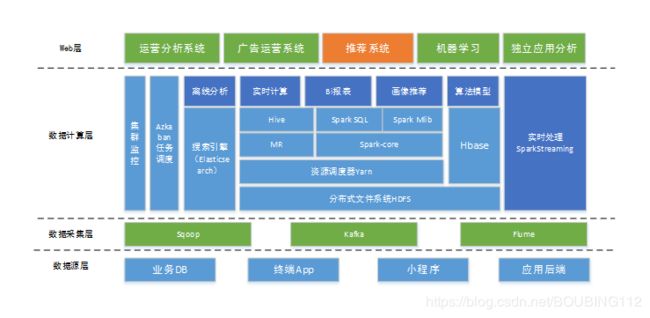
1.4 设备选型
内网IP 主机名 内存 CPU 磁盘
192.168.2.137 hadoop01 32G 16核 2T
192.168.2.140 hadoop02 32G 16核 2T
192.168.2.113 hadoop03 32G 16核 2T
192.168.2.124 client01 32G 16核 2T
1.5 版本选择
组件 版本 备注
hadoop 2.6.5
hive 1.2.2
sqoop 1.4.7
zookeeper 3.4.6
kafka 2.11-2.0.0
flume 1.8.0
jdk 1.8
hbase 0.98
phoenix 4.1.4
spark 2.1.3
1.6 功能分布
hadoop01 hadoop02 hadoop03 client01
Hadoop Y Y Y Y
Spark Y Y Y Y
Zookeeper Y Y Y N
Hive N Y Y Y
Hbase Y Y Y Y
Flume N Y Y Y
Kafka Y Y Y N
Sqoop N Y Y Y
Mysql N N Y N
Azkaban N N N Y
Phoenix N Y Y Y
- 集群基础配置
在搭建集群之前,首先要对这个集群的每一台机器做一些基础配置
2.1修改主机名
我们将每一台机器主机名修改成对应的hadoo01-hadoop03,client01
修改命令:vi /etc/sysconfig/network 进入文件修改hostname=主机名,比如hadoop01上,就hostname=hadoo01, 其他机器也是如此,然后reboot重启即可永久生效
2.2 hosts主机名IP映射文件修改
执行vi /etc/hosts 进入编辑状态 将这个机器主机名和ip对应起来即可
192.168.2.137 hadoop01
192.168.2.140 hadoop02
192.168.2.113 hadoop03
192.168.2.124 client01
2.3关闭防火墙
执行以下命令关闭防火墙
service iptables off
chkconfig iptables off
2.4 配置免秘钥SSH
在每个主机上执行ssh-keygen -t rsa 生成密钥
每台主机通过以下命令配置免登陆:
ssh-copy-id hadoop01
ssh-copy-id hadoop02
ssh-copy-id hadoop03
ssh-copy-id client01
2.5 Jdk安装
解压缩上传jdk至/home/jdk ,在/etc/profile配置环境变量,通过java -version验证
export JAVA_HOME=/home/jdk
export PATH= P A T H : PATH: PATH:JAVA_HOME/bin
2.6 Mysql安装
1.查看知否已有MySQL
输入:yum list installed | grep mysql
2.卸载自带的MySQL 输入:yum -y remove mysql-libs.x86_64,若有多个依赖文件则依次卸载。 当结果显示为Complete!即卸载完毕。
3.查看yum库上的mysql版本信息。
输入:yum list | grep mysql 或 yum -y list mysql*
4.使用yum安装mysql数据库。
输入:yum -y install mysql-server mysql mysql-devel ,命令将:mysql-server、mysql、mysql-devel都安装好,当结果显示为“Complete!”即安装完毕
- 集群组件配置
3.1 Hadoop配置
解压缩Hadoop至 $HADOOP_HOME,Hadoop配置主要配置有6个文件,首先进入hadoop的配置文件目录
cd $HADOOP_HOME
3.1.1 core-site.xml
vi $HADOOP_HOME/etc/hadoop/core-site.xml 编辑文件,将下面的配置粘贴进去保存。
fs.defaultFS
hdfs://hadoop01:9000
io.file.buffer.size
131072
hadoop.tmp.dir
/home/bigconf/hadoopconf/tmp
Abasefor other temporary directories.
3.1.2 hdfs-site.xml
vi $HADOOP_HOME/etc/hadoop/hdfs-site.xml 编辑文件,将下面的配置粘贴进去保存。
dfs.namenode.secondary.http-address
hadoop01:9001
dfs.namenode.name.dir
/home/bigconf/hadoopconf/dfs/name
dfs.datanode.data.dir
/home/bigconf/hadoopconf/dfs/data
dfs.replication
3
dfs.webhdfs.enabled
true
3.1.3 mapred-site.xml
vi $HADOOP_HOME/etc/hadoop/mapred-site.xml编辑文件,将下面的配置粘贴进去保存
mapreduce.framework.name
yarn
3.1.4 yarn-site.xml
vi $HADOOP_HOME/etc/hadoop/yarn-site.xml编辑文件,将下面的配置粘贴进去保存
3.1.5 hadoop-env.sh
vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh文件,导入JAVA_HOME环境变量路径
export JAVA_HOME=/home/jdk
3.1.6 Slaves
vi $HADOOP_HOME/etc/hadoop/ slaves 文件,将集群的计算节点主机名写入其中。
hadoop02
hadoop03
3.1.7 启动hadoop
拷贝至其他节点
scp -r /home/hadoop hadoop02:/home/hadoop
scp -r /home/hadoop hadoop03:/home/hadoop/
scp -r /home/hadoop hadoop04:/home/hadoop
在hadoop01上执行,第一次安装的首先格式化namenode,命令:hadoop namenode -format
start-all.sh命令即可启动全部进程
3.2 Hive配置
3.2.1 hive-site.xml
vi $HIVE_HOME/hive-site.xml编辑文件,将下面的配置粘贴进去。
javax.jdo.option.ConnectionURL
jdbc:mysql://192.168.2.113:3306/hive?createDatabaseIfNotExist=true
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName
root
username to use against metastore database
javax.jdo.option.ConnectionPassword
123456
password to use against metastore database
3.2.2 mysql驱动包
将mysql的驱动包mysql-connector-java-5.1.7-bin.jar拷贝到hive的lib下
3.3 Zookeeper配置
Zookeeper安装在hadoop01,hadoop02,hadoop03上面,将起解压缩上传至
/home/zookeeper
3.3.1 zoo.cfg
首先,进入hadoop01的zookeeper的配置文件目录。
cd $ZOOKEEPER_HOME/conf
然后,编辑zoo.cfg文件
dataDir=/home/hadoop/zookeeper-3.4.9/data
server.1=hadoop01:2888:3888
server.2=hadoop02:2888:3888
server.3=hadoop03:2888:3888
修改dataDir目录即可,在dataDir目录下面创建myid文件,myid文件中的数值与下面server后面的数值对应,将配置好的zookeeper复制到hadoop02,hadoop03上面,命令如下
scp -r /home/zookeeper hadoop02:/home
scp -r /home/zookeeper hadoop03:/home
修改hadoop02,和hadoop03的myid文件数值,hadoop02myid文件值为2,hadoop03 myid
文件值为3
3.3.2 启动zookeeper
在hadoop01,hadoop02,hadoop03上分别执行zkServer.sh start 命令,用jps命令查看,有QuorumPeerMain进程即可。
3.4 Hbase配置
hbase安装在hadoop01,hadoop02,hadoop03上面,将起解压缩上传至
/home/hbase
3.4.1 hbase-env.sh
export JAVA_HOME=/root/jdk
export HBASE_MANAGES_ZK=false
3.4.2 hbase-site.xml
vi $HBASE_HOME/hbase-site.xml编辑文件,将下面的配置粘贴进去。
hbase.rootdir
hdfs://hadoop01:9000/hbase
The directory shared byRegionServers.
hbase.tmp.dir
/home/bigconf/hbaseconf/tmp
hbase.cluster.distributed
true
hbase.zookeeper.property.clientPort
2181
hbase.zookeeper.quorum
hadoop01,hadoop02,hadoop03
hbase.zookeeper.property.dataDir
/home/bigconf/zookeeper/
3.4.3 regionservers
hadoop02
hadoop03
3.5 Phoenix配置
3.5.1 jar包替换
- 将Phoenix 目录下的 phoenix-core-4.10.0-HBase-0.98.jar、phoenix-4.10.0-HBase-0.98-client.jar 拷贝到 hbase 集群各个节点 hbase 安装目录 lib 中。
3.5.2 配置文件替换
- 将 hbase 集群中的配置文件 hbase-site.xml 拷贝到 Phoenix 的 bin 目录下,覆盖原有的配置文件。
- 将 hdfs 集群中的配置文件 core-site.xml、 hdfs-site.xml 拷贝到 Phoenix 的 bin 目录下。
3.5.3 启动
sqlline.py hadoop01:2181
3.6 Sqoop配置
3.6.1 sqoop-env.sh
#Set path to where bin/hadoop is available
export HADOOP_COMMON_HOME=/home/hadoop/
#Set path to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/home/hadoop/
#set the path to where bin/hbase is available
export HBASE_HOME=/home/hbase
#Set the path to where bin/hive is available
export HIVE_HOME=/home/hive
3.6.2 mysql驱动包
将mysql的驱动包mysql-connector-java-5.1.7-bin.jar拷贝到sqoop的lib下
3.7 Flume配置
3.7.1 flume-env.sh
Flume只需要配置下环境变量,就可以用,基于业务再去配source,changle,sink
3.8 Kafka配置
3.8.1 server.properties
broker.id=1
log.dirs=/home/bigconf/kafka/kafka-logs
zookeeper.connect=hadoop01:2181,hadoop02:2181,hadoop03:2181
备注:broker.id 不同的机器不同的id
bin/kafka-server-start.sh config/server.properties
3.9 Spark配置
3.9.1 spark-env.sh
export JAVA_HOME=/home/jdk
export HADOOP_HOME=/home/hadoop
export HADOOP_CONF_DIR= H A D O O P H O M E / e t c / h a d o o p e x p o r t S P A R K M A S T E R I P = h a d o o p 01 e x p o r t S P A R K E X E C U T O R C O R E S = 8 e x p o r t S P A R K E X E C U T O R M E M O R Y = 16 g e x p o r t S P A R K D R I V E R M E M O R Y = 2 g e x p o r t S P A R K C L A S S P A T H = / h o m e / s p a r k / j a r s / m y s q l − c o n n e c t o r − j a v a − 5.1.45. j a r : HADOOP_HOME/etc/hadoop export SPARK_MASTER_IP=hadoop01 export SPARK_EXECUTOR_CORES=8 export SPARK_EXECUTOR_MEMORY=16g export SPARK_DRIVER_MEMORY=2g export SPARK_CLASSPATH=/home/spark/jars/mysql-connector-java-5.1.45.jar: HADOOPHOME/etc/hadoopexportSPARKMASTERIP=hadoop01exportSPARKEXECUTORCORES=8exportSPARKEXECUTORMEMORY=16gexportSPARKDRIVERMEMORY=2gexportSPARKCLASSPATH=/home/spark/jars/mysql−connector−java−5.1.45.jar:SPARK_CLASSPATH
3.9.2 slaves
hadoop02
hadoop03
3.10 Azkaban配置
3.10.1 azkaban-sql-script-2.5.0.tar.gz
在mysql中创建数据库azkaban(数据库自定义),导入azkaban-sql-script-2.5.0.tar.gz
解压出来的create-all-sql-2.5.0.sql
3.10.2 配置时区以及SSL
1.通过tzselect一步一步选择自己所在时区,我们是东八区
2.cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
时区:
SSL:
命令: keytool -keystore keystore -alias jetty -genkey -keyalg RSA
运行此命令后,会提示输入当前生成 keystor的密码及相应信息,信息如下:
输入keystore密码:
再次输入新密码:
您的名字与姓氏是什么?
[Unknown]:
您的组织单位名称是什么?
[Unknown]:
您的组织名称是什么?
[Unknown]:
您所在的城市或区域名称是什么?
[Unknown]:
您所在的州或省份名称是什么?
[Unknown]:
该单位的两字母国家代码是什么
[Unknown]: CN
CN=Unknown, OU=Unknown, O=Unknown, L=Unknown, ST=Unknown, C=CN 正确吗?
[否]: y
输入的主密码
(如果和 keystore 密码相同,按回车):
再次输入新密码:
完成上述工作后,将在当前目录生成 keystore 证书文件,将keystore 考贝到 azkaban web服务器根目录中
3.10.3 azkaban-web-server-2.5.0.tar.gz
配置Azkaban.properties
#Azkaban Personalization Settings
azkaban.name=Test
azkaban.label=My Local Azkaban
azkaban.color=#FF3601
azkaban.default.servlet.path=/index
web.resource.dir=web/
default.timezone.id=Asia/Shanghai
#Azkaban UserManager class
user.manager.class=azkaban.user.XmlUserManager
user.manager.xml.file=conf/azkaban-users.xml
#Loader for projects
executor.global.properties=conf/global.properties
azkaban.project.dir=projects
database.type=mysql
mysql.port=3306
mysql.host=192.168.1.31
mysql.database=azkaban
mysql.user=root
mysql.password=123456
mysql.numconnections=100
Velocity dev mode
velocity.dev.mode=false
Azkaban Jetty server properties.
jetty.maxThreads=25
jetty.ssl.port=8443
jetty.port=8081
jetty.keystore=keystore
jetty.password=123456
jetty.keypassword=123456
jetty.truststore=keystore
jetty.trustpassword=123456
Azkaban Executor settings
executor.port=12321
mail settings
mail.sender=
mail.host=
job.failure.email=
job.success.email=
lockdown.create.projects=false
cache.directory=cache
配置azkaban-users.xml
3.10.4 azkaban-executor-server-2.5.0.tar.gz
配置azkaban.properties
#Azkaban
default.timezone.id=Asia/Shanghai
Azkaban JobTypes Plugins
azkaban.jobtype.plugin.dir=plugins/jobtypes
#Loader for projects
executor.global.properties=conf/global.properties
azkaban.project.dir=projects
database.type=mysql
mysql.port=3306
mysql.host=192.168.1.31
mysql.database=azkaban
mysql.user=root
mysql.password=123456
mysql.numconnections=100
Azkaban Executor settings
executor.maxThreads=50
executor.port=12321
executor.flow.threads=30
4.调优和测试
4.1 集群调优
目前也只是搭建集群时候一个初步的调优,后续hive,hbase等组件调优会慢慢加进来
4.1.1 yarn-site.xml
添加以下配置
yarn.nodemanager.resource.memory-mb
20480
yarn.nodemanager.resource.cpu-vcores
16
4.1.2 mapred-site.xml
添加以下配置
mapreduce.framework.name
yarn
mapreduce.map.java.opts
-Xmx1024m
mapreduce.reduce.java.opts
-Xmx2048m
4.2 集群测试
4.2.1 MapReduce测试
hadoop jar /home/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar pi 5 5
4.2.2 Hive创建测试
create database if not exists test;
create external table if not exists test.test
(id int,name string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘\001’
location ‘/user/hive/external/fz_external_table’;
4.2.3 Sqoop操作测试
sqoop list-databases --connect jdbc:mysql://hadoop03:3306/ --username root --password 123456
4.2.4 Kafka操作测试
生产者:
public class KafkaProductTest {
public static void main(String[] args) {
Properties props = new Properties();
props.put(“bootstrap.servers”, “hadoop01:9092”);
props.put(“acks”, “all”);
props.put(“retries”, 0);
props.put(“batch.size”, 16384);
props.put(“linger.ms”, 1);
props.put(“buffer.memory”, 33554432);
props.put(“key.serializer”, “org.apache.kafka.common.serialization.StringSerializer”);
props.put(“value.serializer”, “org.apache.kafka.common.serialization.StringSerializer”);
Producer
for (int i = 0; i < 100; i++)
producer.send(new ProducerRecord
producer.close();
}
}
消费者:
public class KafkaConsumerTest {
public static void main(String[] args) {
Properties props = new Properties();
props.put(“bootstrap.servers”, “hadoop01:9092”);
props.put(“group.id”, “test”);
props.put(“enable.auto.commit”, “true”);
props.put(“auto.commit.interval.ms”, “1000”);
props.put(“key.deserializer”, “org.apache.kafka.common.serialization.StringDeserializer”);
props.put(“value.deserializer”, “org.apache.kafka.common.serialization.StringDeserializer”);
KafkaConsumer
consumer.subscribe(Arrays.asList(“test1”));
while (true) {
ConsumerRecords
for (ConsumerRecord
System.out.printf(“offset = %d, key = %s, value = %s%n”, record.offset(), record.key(), record.value());
}
}
}
4.2.5 Phoenix操作测试
创建测试表test.test
CREATE TABLE if not exists test.test ( id INTEGER not null primary key , t.name char(20) ,t.age integer) t.DATA_BLOCK_ENCODING=‘DIFF’
UPSERT INTO test.test(id,name,age) VALUES(1,‘jack’,23);
测试连接代码
public class PhoenixTest {
private static String phoenixDriver = “org.apache.phoenix.jdbc.PhoenixDriver”;
public static void main(String[] args) throws SQLException {
try {
Class.forName(phoenixDriver);
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
Statement stmt = null;
ResultSet rs = null;
Connection con = DriverManager.getConnection(“jdbc:phoenix:hadoop01,hadoop02,hadoop03:2181”);
stmt = con.createStatement();
String sql = “select * from test.test”;
rs = stmt.executeQuery(sql);
while (rs.next()) {
System.out.println(“id:”+rs.getInt(“id”));
System.out.println(“name:”+rs.getString(“name”));
System.out.println(“age:”+rs.getInt(“age”));
}
stmt.close();
con.close();
}
}
结果:
id:1
name:jack
age:23
4.2.6 Spark操作测试
spark yarn模式测试
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster examples/jars/spark-examples_2.11-2.1.3.jar 10