【制表符\t】你不知道的制表符\t的那些事儿~
昨天测试一个程序的时候发现它的输出结果和书上的不一样,也和想象中的不太一样,不过代码和书上是一摸一样的。
代码附上:(C++)
#include
using namespace std;
class listclass
{
int *listptr;//指向线性表
int nlen;
int nelem;
public:
listclass(int n=10)
{
nelem=0;
nlen=n;
if(n)
listptr=new int[n];
else
listptr=0;
}
~listclass()
{
delete listptr;
}
int elem(int n);
int &elem(unsigned n)
{
return listptr[n];//返回线性表下标为n的元素的引用
}
int elem(void)
{
return nelem;
}
int len(void)
{
return nlen;
}
int getelem(int i)
{
if(i>=0 && i 输出结果:
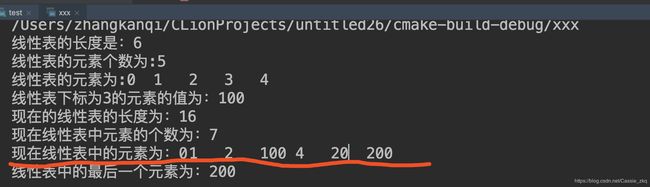
与这行输出有关的代码是:
void listclass::print(void)
{
for(int i=0;i咦?我用了制表符为什么最后输出的结果没有像表格一样中间的间隔是相同的呢?我查了一下平时不太注意的制表符\t,发现。。。有点东西。以例子来说明
-
要输出的数字自己在一行时

可以注意到:要输出的元素每4个长度一组,这就相当于所制表中每个格子的长度是4,不足的后面补空格。这里的长度可以理解成数字个数,就如上面的截图所示。
规律如下:
数据后面补充的空格长度numspace=4-n%4
这里的n之前是前面元素的长度(包括要输出的数据)
注意:制表符的宽度是个可配置属性,一旦配置好以后就固定了,除非再次配置。我这里的\t的宽度是4,有些设备和编译器上\t的宽度是8,那么上面规律对应的式子就要做一点改变。
-
汉字和要输出的数字在一行时
cout<<"12345678912345678912345678912345678123456789123456789\n";
cout<<"现在线性表中的元素为";
list.print();输出:
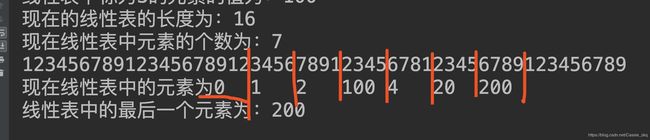
发现除了0之外,其他要输出的数字对应的制表符的宽度都能很直接的看出来是4,加入了汉字之后0之后的空格便不再是原来的3了,这是因为|n-4|%4中n的值变了。(我为什么要说这么智障的话,n肯定变了呀)
在UTF-8编码下(不同的编码对应的情况不同),一个汉字占3个字节,一个英文字母占1个字节。
所以对于此种情况,前面占:10(10个汉字)*3+1*4(int 型占4个字节)=34个字节;
如果按一个数字算一个长度计算的话,那么一个长度对应4个字节。
n=34/4=8.5个长度 ,numspace=4-8.5%4=3.5,即补充3.5个长度的空格。
且每个长度对应4个字节,4*3.5=14个字节,即在下一个数据输出之前有14个空内容的字节,虽然在这个例子中肉眼看到的只有2个多的长度,可能是受到前面汉字和数字宽度的影响,并不代表实际的长度。
(不知道上面那段话我这样理解对不对,接受反驳( ´▽`))
-
汉字、符号和要输出的数字在一行时
cout<<"12345678912345678912345678912345678123456789123456789\n";
cout<<"现在线性表中的元素为:";
list.print();中文冒号:
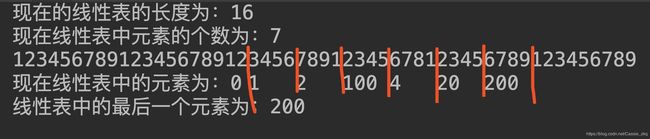
英文冒号:
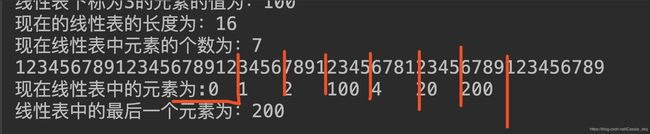
(可以看出来中文冒号比英文冒号所占字节多)
这种情况的计算过程和第二种情况相似,但要注意的是,英文标点占一个字节,中文标点占两个字节。
附:计算机中一个符号占多少字节的相关内容(来源自百度)
1、ASCII码:一个英文字母(不分大小写)占一个字节的空间,一个中文汉字占两个字节的空间。一个二进制数字序列,在计算机中作为一个数字单元,一般为8位二进制数,换算为十进制。最小值0,最大值255。如一个ASCII码就是一个字节。
2、UTF-8编码:一个英文字符等于一个字节,一个中文(含繁体)等于三个字节。
3、Unicode编码:一个英文等于两个字节,一个中文(含繁体)等于两个字节。
4、符号:英文标点占一个字节,中文标点占两个字节。举例:英文句号“.”占1个字节的大小,中文句号“。”占2个字节的大小。
!!另外,我发现了一个很诡异的事情(゚o゚;;当我把最初的输出结果(文章初始代码下面的那个输出结果)复制粘贴时,它出现了这种神奇的现象:
线性表的长度是:6
线性表的元素个数为:5
线性表的元素为:0 1 2 3 4
线性表下标为3的元素的值为:100
现在的线性表的长度为:16
现在线性表中元素的个数为:7
现在线性表中的元素为:0 1 2 100 4 20 200
线性表中的最后一个元素为:200
第七行的01竟然分的很开,正是使用制表符\t想要的结果
不过这个点还没有搞明白!(◎_◎;)请各路大神指点迷津,以上内容有错误要帮我指出来哦~
邮箱:[email protected] 非诚勿扰 ٩(˃̶͈̀௰˂̶͈́)و