python_网络爬虫篇1
入门知识·文件的读取
在学习Python的过程中,顺便看了看Python网络爬虫的些许知识,记录的笔记:
先来看一看怎么从本地获取数据,常见的也就是读取文件,这里也就是关于python读取文件的语法:
file_obj = open(filename,mode='r',buffering=-1,....)
mode为可选参数,r 读 w写 a追加 [注意:w模式会清空原来的内容,所以要小心!]
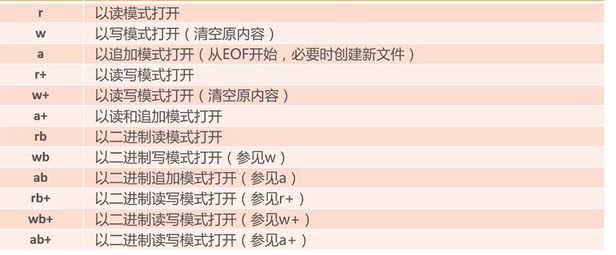
在python中文件是一个对象,包含了很多方法,读read(),写write(),读一行readline(),关闭文件close(),seek()等方法,例如我们新建一个文件txt,往里写入数据:
不需要手动关闭文件即不需要写close();
file = open('echo_hello.txt','w') 同理: with open('echo_hello.txt') as f
file.write('echo:hello world!') p=f.read()
file.close()
//从刚才建立的文件读取数据
更好的做法是用with语句:
with open('echo_hello.txt') as f
f.write('echo:hello world!')
好了,其实发现读取本地文件并没有很有趣,只是要了解并掌握一下下,下面才开始做点有趣的事情

网络数据爬取
首先用Python获取数据制作crawler的时候需要安装相应的文件包(pip install...啦)
·抓取
·urllib内建模块
-urllib.request
·Requests第三方库(官网) http://www/python-requests.org/
常用的函数 get()函数
·Scrapy框架
·解析
·BeautifulSoup库(官网) https://www.crummy.com/software/BeautifulSoup/
·re模块(正则表达式模块) https://doc.python.org/3.5/library/re.html
·第三方API解析
requests库
进入到requests官网我们看到这个介绍啊(全英文),当然也有中文版的文档(http://cn.python-requests.org/zh_CN/latest/):
文档是这样介绍的:“Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用。
警告:非专业使用其他 HTTP 库会导致危险的副作用,包括:安全缺陷症、冗余代码症、重新发明轮子症、啃文档症、抑郁、头疼、甚至死亡。看吧,这就是 Requests 的威力”

这段介绍代码还是比较小清新,利用requests中的get()方法,参数为url地址,如果输出的状态码是200的话那就说明爬取成功!
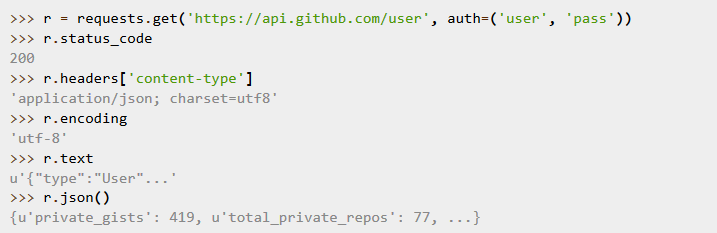

在进行爬虫的时候,有时候我们也需要看一下有没有爬虫协议,有的网站会提供robots文件,比如看看百度有没有(百度能没有嘛,目前China的搜索老大)可以看到:


法不禁止即允许,在这里可以看到百度对哪些目录设置了disallow,那么在没有设置disallow的目录下,我们就可以通过写爬虫代码进行爬取。
比如我们试着爬一爬这个页面

在这里我用的是pycharm软件,当然不是说集成了很多文件库,只是用着简单一点(可能我比较愚钝吧),该安装的库文件还是pip install来一步步安装
r = requests.get('http://news.baidu.com/')
print(r.status_code)
with open(r'D:/news.txt','w') as f:
f.write(r.text)
print("successful action")
把爬取到的内容放在一个文件里面,也就是with语句,之前输出个状态码检测一下下。

可以看到是爬取到了,然后再来看看D盘下的news.txt文件
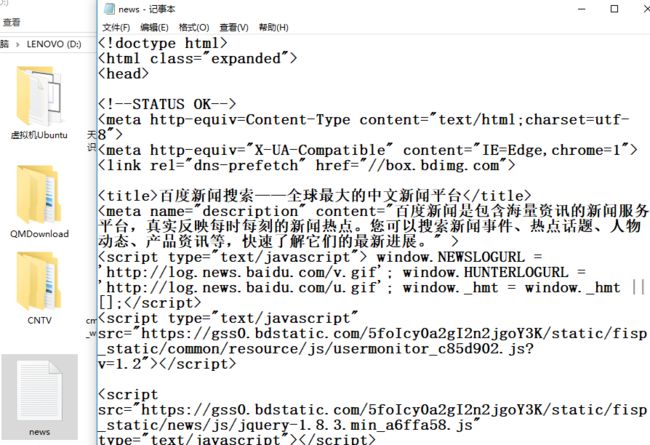
结果如我们所料

之前看网上写爬虫的很长一串串代码,真的看不下去,后来发现这样不是也很简洁么~
再比如如我们来爬取一下豆瓣的书评:
import requests
r = requests.get('https://book.douban.com/subject/27031869/?icn=index-editionrecommend/')
print(r.status_code)
print(r.text)
通过requests的get()函数的方法,参数为抓取页面的网页地址。运行程序,在窗口可以看到:
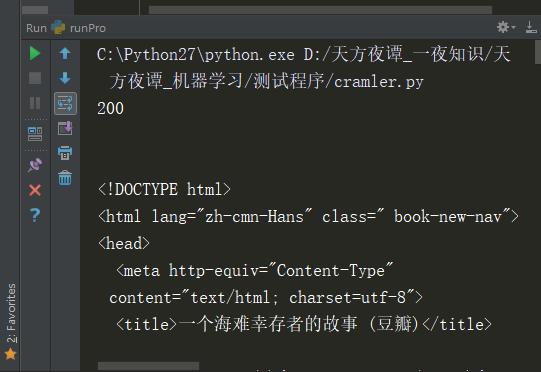

其中输出的状态吗 200.说明运行成功
爬取网页信息代码通用框架:
理解requests异常


网络数据爬取便准模块
import requests
def getHtml(url):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "返回异常"
if __name__ == '__main__':
url = "http://网页页面地址"
print(getHtml(url))
More Understanding: 理解HTTP协议:http://kb.cnblogs.com/page/130970/
希望收到您的评论,让我进步!