【机器学习】机器学习中的统计学知识
泛化能力、过拟合、经验风险(ERM)、结构风险(SRM)、
假设空间:模型在数学上的“适用场合”
使风险上界最小函数子集中挑选出使经验风险最小的函数,这个函数的子集就是假设空间
经验风险:训练集数据集是的风险
结构风险:只注重训练集的学习方法
经验风险在某种足够合理的数学意义上一致收敛于期望风险
奥卡姆剃刀原理:如无必要,勿增实体。切勿浪费较多的东西去做,用最少的东西,同样可以做好事情。
泛化能力:模型在未知数据上的表现,针对的是学习方法,用于衡量某种学习方法学习到的模型在整个样本空间上的表现。
数据集Data Set :数据的集合
样本Sample :数据集中每一条单独的数据
样本的 属性 Attribute/特征 Feature :每个样本具有的
特征值Feature Value :特征具有的值
特征空间Feature Space 和 样本空间 Sample Space:
特征和样本所张成的空间
特征和样本“可能存在的空间”
标签空间Label Space : 表述了模型的输出“可能存在的空间”
类别空间 : 分类器的标签空间
三类数据集:
1、训练集 Training Set :
总的数据集中用来训练模型的部分
为了提高及合理评估模型的泛化能力,一般只取数据集汇总的一部分样本充当训练集
2、测试集 Test Set :
测试和评估模型的泛化能力的部分
测试集通常不会用与充当训练集,测试集对于模型是未知的
3、交叉验证集 Cross-Validation Set(CV Set):
用来调整模型具体的参数
进行交叉验证可以知道过拟合程度
三种常见的交叉验证:
1、S-fold Cross Validation:S折交叉验证,应用最多
将数据分成S份,一共做S次试验
在第i次试验中,使用D-Di作为训练集,Dj作为测试集对模型进行训练和测试
最终选择平均测试误差最小的模型
2、留一交叉验证 Leave-one-out Cross Validation:S折交叉验证的特殊情况,S = N
3、简易交叉验证:较为简单
简单的将数据进行随机分组,最后达到训练集约占原数据70%程度
选择模型是使用测试误差作为标准
交叉验证流程图:

统计学的数学概念:
均值:
平均数是表示一组数据集中趋势的量数,在一组数据中所有数据之和再除以这组数据的个数。
反映数据集中趋势的一项指标,表明资料中各观测值相对集中较多的中心位置。
统计平均数是用于反映现象总体的一般水平,或分布的集中趋势。
算术平均数 arithmeticmean:
一组数据中所有数据之和再除以数据的个数。它是反映数据集中趋势的一项指标。
公式:![]()
几何平均数geometric mean:
n个观察值连乘积的n次方根就是几何平均数。
![]()
加权平均数weighted average:
不同比重数据的平均数,
![]()
f1、f2、…、fk叫做权(weight)。
标准差:
标准差是方差的算术平方根。
标准差能反映一个数据集的离散程度,反映组内个体间的离散程度。
标准计算公式:
假设有一组数值X₁,X₂,X₃,......Xn(皆为实数),其平均值(算术平均值)为μ,

方差:
概率论和统计方差衡量随机变量或一组数据时离散程度的度量。
用来度量随机变量和其数学期望(即均值)之间的偏离程度。
![]() 为总体方差,
为总体方差, ![]() 为变量,
为变量, ![]() 为总体均值,
为总体均值, ![]() 为总体例数。
为总体例数。
![]()
样本方差计算公式: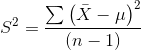
S^2为样本方差,X为变量, ![]() 为样本均值,n为样本例数。
为样本均值,n为样本例数。