Prometheus-operator 介绍和配置解析
随着云原生概念盛行,对于容器、服务、节点以及集群的监控变得越来越重要。Prometheus 作为 Kubernetes 监控的事实标准,有着强大的功能和良好的生态。但是它不支持分布式,不支持数据导入、导出,不支持通过 API 修改监控目标和报警规则,所以在使用它时,通常需要写脚本和代码来简化操作。Prometheus Operator 为监控 Kubernetes service、deployment 和 Prometheus 实例的管理提供了简单的定义,简化在 Kubernetes 上部署、管理和运行 Prometheus 和 Alertmanager 集群。
功能
Prometheus Operator (后面都简称 Operater) 提供如下功能:
-
创建/销毁:在 Kubernetes namespace 中更加容易地启动一个 Prometheues 实例,一个特定应用程序或者团队可以更容易使用 Operator。
-
便捷配置:通过 Kubernetes 资源配置 Prometheus 的基本信息,比如版本、存储、副本集等。
-
通过标签标记目标服务: 基于常见的 Kubernetes label 查询自动生成监控目标配置;不需要学习 Prometheus 特定的配置语言。
先决条件
对于版本高于 0.18.0 的 Prometheus Operator 要求 Kubernetes 集群版本高于 1.8.0。如果你才开始使用 Prometheus Operator,推荐你使用最新版。
如果你使用的旧版本的 Kubernetes 和 Prometheus Operator 还在运行,推荐先升级 Kubernetes,再升级 Prometheus Operator。
安装与卸载
快速安装
使用 helm 安装 Prometheus Operator。使用 helm 安装后,会在 Kubernetes 集群中创建、配置和管理 Prometheus 集群,chart 中包含多种组件:
- prometheus-operator
- prometheus
- alertmanager
- node-exporter
- kube-state-metrics
- grafana
- 收集 Kubernetes 内部组件指标的监控服务
- kube-apiserver
- kube-scheduler
- kube-controller-manager
- etcd
- kube-dns/coredns
- kube-proxy
安装一个版本名为 my-release 的 chart:
helm install --name my-release stable/prometheus-operator
这会在集群中安装一个默认配置的 prometheus-operator。这份配置文件列出了安装过程中可以配置的选项。
默认会安装 Prometheus Operator, Alertmanager, Grafana。并且会抓取集群的基本信息。
卸载
卸载 my-release 部署:
helm delete my-release
这个命令会删除与这个 chart 相关的所有 Kubernetes 组件。
这个 chart 创建的 CRDs 不会被默认删除,需要手动删除:
kubectl delete crd prometheuses.monitoring.coreos.com
kubectl delete crd prometheusrules.monitoring.coreos.com
kubectl delete crd servicemonitors.monitoring.coreos.com
kubectl delete crd podmonitors.monitoring.coreos.com
kubectl delete crd alertmanagers.monitoring.coreos.com
架构
Prometheus Operator 架构图如下:
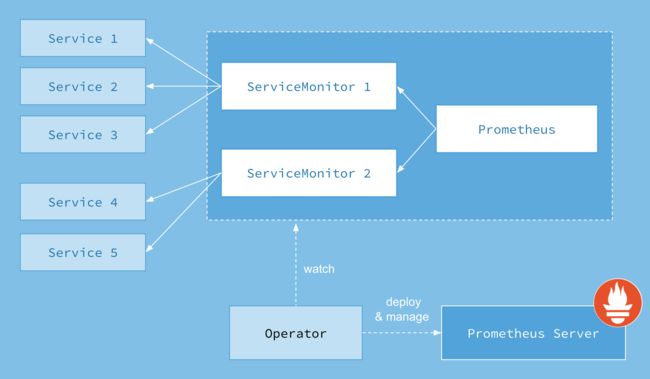
上面架构图中,各组件以不同的方式运行在 Kubernetes 集群中:
- Operator: 根据自定义资源(Custom Resource Definition / CRDs)来部署和管理 Prometheus Server,同时监控这些自定义资源事件的变化来做相应的处理,是整个系统的控制中心。
- Prometheus:声明 Prometheus deployment 期望的状态,Operator 确保这个 deployment 运行时一直与定义保持一致。
- Prometheus Server: Operator 根据自定义资源 Prometheus 类型中定义的内容而部署的 Prometheus Server 集群,这些自定义资源可以看作是用来管理 Prometheus Server 集群的 StatefulSets 资源。
- ServiceMonitor:声明指定监控的服务,描述了一组被 Prometheus 监控的目标列表。该资源通过 Labels 来选取对应的 Service Endpoint,让 Prometheus Server 通过选取的 Service 来获取 Metrics 信息。
- Service:简单的说就是 Prometheus 监控的对象。
- Alertmanager:定义 AlertManager deployment 期望的状态,Operator 确保这个 deployment 运行时一直与定义保持一致。
自定义资源
Prometheus Operater 定义了如下的四类自定义资源:
- Prometheus
- ServiceMonitor
- Alertmanager
- PrometheusRule
Prometheus
Prometheus 自定义资源(CRD)声明了在 Kubernetes 集群中运行的 Prometheus 的期望设置。包含了副本数量,持久化存储,以及 Prometheus 实例发送警告到的 Alertmanagers等配置选项。
每一个 Prometheus 资源,Operator 都会在相同 namespace 下部署成一个正确配置的 StatefulSet,Prometheus 的 Pod 都会挂载一个名为
一个样例配置如下:
kind: Prometheus
metadata: # 略
spec:
alerting:
alertmanagers:
- name: prometheus-prometheus-oper-alertmanager # 定义该 Prometheus 对接的 Alertmanager 集群的名字, 在 default 这个 namespace 中
namespace: default
pathPrefix: /
port: web
baseImage: quay.io/prometheus/prometheus
replicas: 2 # 定义该 Proemtheus “集群”有两个副本,说是集群,其实 Prometheus 自身不带集群功能,这里只是起两个完全一样的 Prometheus 来避免单点故障
ruleSelector: # 定义这个 Prometheus 需要使用带有 prometheus=k8s 且 role=alert-rules 标签的 PrometheusRule
matchLabels:
prometheus: k8s
role: alert-rules
serviceMonitorNamespaceSelector: {} # 定义这些 Prometheus 在哪些 namespace 里寻找 ServiceMonitor
serviceMonitorSelector: # 定义这个 Prometheus 需要使用带有 k8s-app=node-exporter 标签的 ServiceMonitor,不声明则会全部选中
matchLabels:
k8s-app: node-exporter
version: v2.10.0
Prometheus 配置
ServiceMonitor
ServiceMonitor 自定义资源(CRD)能够声明如何监控一组动态服务的定义。它使用标签选择定义一组需要被监控的服务。这样就允许组织引入如何暴露 metrics 的规定,只要符合这些规定新服务就会被发现列入监控,而不需要重新配置系统。
要想使用 Prometheus Operator 监控 Kubernetes 集群中的应用,Endpoints 对象必须存在。Endpoints 对象本质是一个 IP 地址列表。通常,Endpoints 对象由 Service 构建。Service 对象通过对象选择器发现 Pod 并将它们添加到 Endpoints 对象中。
一个 Service 可以公开一个或多个服务端口,通常情况下,这些端口由指向一个 Pod 的多个 Endpoints 支持。这也反映在各自的 Endpoints 对象中。
Prometheus Operator 引入 ServiceMonitor 对象,它发现 Endpoints 对象并配置 Prometheus 去监控这些 Pods。
ServiceMonitorSpec 的 endpoints 部分用于配置需要收集 metrics 的 Endpoints 的端口和其他参数。在一些用例中会直接监控不在服务 endpoints 中的 pods 的端口。因此,在 endpoints 部分指定 endpoint 时,请严格使用,不要混淆。
注意:endpoints(小写)是 ServiceMonitor CRD 中的一个字段,而 Endpoints(大写)是 Kubernetes 资源类型。
ServiceMonitor 和发现的目标可能来自任何 namespace。这对于跨 namespace 的监控十分重要,比如 meta-monitoring。使用 PrometheusSpec 下 ServiceMonitorNamespaceSelector, 通过各自 Prometheus server 限制 ServiceMonitors 作用 namespece。使用 ServiceMonitorSpec 下的 namespaceSelector 可以现在允许发现 Endpoints 对象的命名空间。要发现所有命名空间下的目标,namespaceSelector 必须为空。
spec:
namespaceSelector:
any: true
一个样例配置如下:
kind: ServiceMonitor
metadata:
labels:
k8s-app: node-exporter # 这个 ServiceMonitor 对象带有 k8s-app=node-exporter 标签,因此会被 Prometheus 选中
name: node-exporter
namespace: default
spec:
selector:
matchLabels: # 定义需要监控的 Endpoints,带有 app=node-exporter 且 k8s-app=node-exporter标签的 Endpoints 会被选中
app: node-exporter
k8s-app: node-exporter
endpoints:
- bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
interval: 30s # 定义这些 Endpoints 需要每 30 秒抓取一次
targetPort: 9100 # 定义这些 Endpoints 的指标端口为 9100
scheme: https
jobLabel: k8s-app
ServiceMonitor 配置
Alertmanager
Alertmanager 自定义资源(CRD)声明在 Kubernetes 集群中运行的 Alertmanager 的期望设置。它也提供了配置副本集和持久化存储的选项。
每一个 Alertmanager 资源,Operator 都会在相同 namespace 下部署成一个正确配置的 StatefulSet。Alertmanager pods 配置挂载一个名为 Secret, 使用 alertmanager.yaml key 对作为配置文件。
当有两个或更多配置的副本时,Operator 可以高可用性模式运行Alertmanager实例。
一个样例配置如下:
kind: Alertmanager # 一个 Alertmanager 对象
metadata:
name: prometheus-prometheus-oper-alertmanager
spec:
baseImage: quay.io/prometheus/alertmanager
replicas: 3 # 定义该 Alertmanager 集群的节点数为 3
version: v0.17.0
Alertmanager 配置
PrometheusRule
PrometheusRule CRD 声明一个或多个 Prometheus 实例需要的 Prometheus rule。
Alerts 和 recording rules 可以保存并应用为 yaml 文件,可以被动态加载而不需要重启。
一个样例配置如下:
kind: PrometheusRule
metadata:
labels: # 定义该 PrometheusRule 的 label, 显然它会被 Prometheus 选中
prometheus: k8s
role: alert-rules
name: prometheus-k8s-rules
spec:
groups:
- name: k8s.rules
rules: # 定义了一组规则,其中只有一条报警规则,用来报警 kubelet 是不是挂了
- alert: KubeletDown
annotations:
message: Kubelet has disappeared from Prometheus target discovery.
expr: |
absent(up{job="kubelet"} == 1)
for: 15m
labels:
severity: critical
PrometheusRule 配置
它们之间的关系如下图:
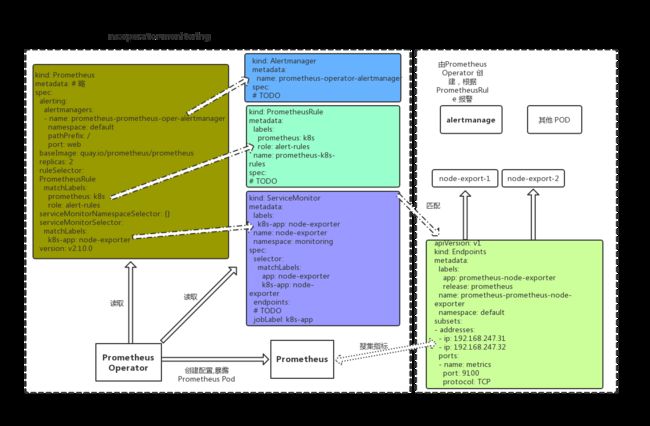
Prometheus Operator 的优点
Prometheus Operator 中所有的 API 对象都是 CRD 中定义好的 Schema,API Server会校验。当开发者使用 ConfigMap 保存配置没有任何校验,配置文件写错时,自表现为功能不可用,问题排查复杂。在 Prometheus Operator 中,所有在 Prometheus 对象、ServiceMonitor 对象、PrometheusRule 对象中的配置都是有 Schema 校验的,校验失败 apply 直接出错,这就大大降低了配置异常的风险。
Prometheus Operator 借助 K8S 将 Prometheus 服务平台化。有了 Prometheus 和 AlertManager 这样的 API 对象,非常简单、快速的可以在 K8S 集群中创建和管理 Prometheus 服务和 AlertManager 服务,以应对不同业务部门,不同领域的监控需求。
ServiceMonitor 和 PrometheusRule 解决了 Prometheus 配置难维护问题,开发者不再需要去专门学习 Prometheus 的配置文件,不再需要通过 CI 和 k8s ConfigMap 等手段把配置文件更新到 Pod 内再触发 webhook 热更新,只需要修改这两个对象资源就可以了。
关于Choerodon猪齿鱼
Choerodon猪齿鱼是一个开源多云技术平台,是基于开源技术Kubernetes,Istio,knative,Gitlab,Spring Cloud来实现本地和云端环境的集成,实现企业多云/混合云应用环境的一致性。平台通过提供精益敏捷、持续交付、容器环境、微服务、DevOps等能力来帮助组织团队来完成软件的生命周期管理,从而更快、更频繁地交付更稳定的软件。
Choerodon猪齿鱼已开通官方微信交流群,欢迎大家添加Choerodon猪齿鱼VX(ID:choerodon-c7n)入群