机器学习: 回归
文章目录
- Github
- 前言
- 数学基础
- 概率和似然
- 最大似然估计 MLE
- 最小二乘法
- 高斯分布
- 中心极限定理与大数定理
- 浅谈回归
- 基本概念
- 线性回归
- 最小二乘法意义下的解析解
- LASSO 回归,岭回归
- 梯度下降算法
- Logistic 回归
- 参数估计
- 与线性回归的关系
Github
系列文章 pdf 版本已经上传至: https://github.com/anlongstory/awsome-ML-DL-leaning/tree/master/xiaoxiang-notes
欢迎 Star 和下载
前言
之前也有写过李航博士的《统计学习方法》的博客内容,即将书写的机器学习系列博客内容不可避免的要与之有所重叠,但是之前完成的 《统计学习方法》 系列的博客主要是对书中的一些概念的摘录(公式和图片大部分都是截取内容直接粘贴),旨在快速了解机器学习的相关概念,并没有一些拓展,本系列的文章更多的是想深入理解机器学习相关概念及背后的数学基础(为了更好的学习和阅读体验,数学公式推导都是一个个手打上去的,图片能自己代码生成也都是自己代码生成),主要脉络是跟着小象学院的机器学习视频走的,然后自己对整体的内容进行了取舍和整理,尽可能地有逻辑地呈现出来,帮助理解,因为水平有限,如果有错误还请留言指正。后面还会对本系列文章不定期代码部分内容,加深理解。
数学基础
在聊回归之前先了解一下基础的数学概念。
概率和似然
这两个概念都是指可能性
- 概率:给定某一参数值,求某一结果的可能性的函数
- 似然:给定某一结果,求某一参数值的可能性的函数
查阅资料的过程,最经典的就是抛硬币的例子,概率问题里,就是已知硬币正反面出现的概率各为 0.5,抛 10 次,6次正面向上的可能性是多少?而似然问题则是,抛 10 次硬币,有 6 次正面向上,求硬币正反面出现概率各为多少?
最大似然估计 MLE
继续上面抛硬币的问题,设正面向上的概率 θ \theta θ , 所以反面出现的概率就是 1 − θ 1- \theta 1−θ,因为本身情况已经是给定的,且每次抛硬币的实验是独立的,所以可以直接写出似然函数:
f ( θ ) = θ 6 ( 1 − θ ) 4 f\left ( \theta \right )=\theta ^{6}\left ( 1-\theta \right )^{4} f(θ)=θ6(1−θ)4
我们画出这个函数的曲线可以看到:
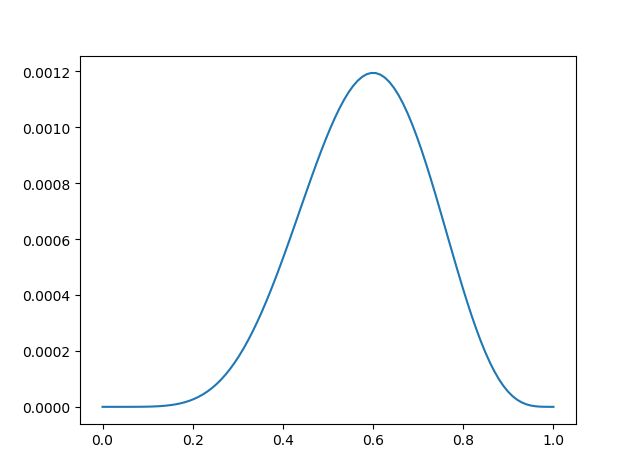
当 θ \theta θ 值为 0.6 时,函数 f ( θ ) f\left ( \theta \right ) f(θ) 可以取得最大值。在求解 f ( θ ) f\left ( \theta \right ) f(θ) 在 θ \theta θ 为何值时最大的过程就是最大似然估计。
(在 ML 中,似然函数都是指数形式的,所以更多的做法是先取 log 简化表达式,然后再求最大似然估计 )
最小二乘法
百度百科给出的定义是: 最小二乘法是通过最小化误差的平方和寻找数据的最佳函数匹配。
首先这里的关键词就是“误差的平方和”,我们可以用公式:
E r r o r = ∑ ( y ^ − y i ) 2 Error=\sum \left ( \widehat{y}-y_{i} \right )^2 Error=∑(y −yi)2
来表示相关上述概念,其中 y ^ \widehat{y} y 表示的预测值, y i y_{i} yi 表示的是已知的真实值, y i y_{i} yi 是固定的,我们可以通过调整 y ^ \widehat{y} y 的值来达到最后 E r r o r Error Error 最小,这样一个寻找预测值 y ^ \widehat{y} y 的过程就是最小二乘法的思想。
假设现在我们有 4 个样本点 y 1 , y 2 , y 3 , y 4 y_{1},y_{2},y_{3},y_{4} y1,y2,y3,y4, 预测值为 y y y, 根据最小二乘法的定义,想要最后的 E r r o r Error Error 最小,我们需要对函数二次求导以后,求使导数为 0 的点,即:
d ∑ ( y − y i ) 2 d y = 2 ∑ ( y − y i ) = 2 ( ( y − y 1 ) + ( y − y 2 ) + ( y − y 3 ) + ( y − y 4 ) ) = 0 \frac{\mathrm{d} \sum \left ( y-y_{i} \right )^2}{\mathrm{d} y}= 2\sum \left ( y-y_{i} \right )=2\left ( \left ( y-y_{1} \right )+\left ( y-y_{2} \right )+\left ( y-y_{3} \right )+\left ( y-y_{4} \right ) \right )=0 dyd∑(y−yi)2=2∑(y−yi)=2((y−y1)+(y−y2)+(y−y3)+(y−y4))=0
化简上面的式子可以得到:
4 y = y 1 + y 2 + y 3 + y 4 ⇒ y = y 1 + y 2 + y 3 + y 4 4 4y=y_{1}+y_{2}+y_{3}+y_{4}\Rightarrow y=\frac{y_{1}+y_{2}+y_{3}+y_{4}} {4} 4y=y1+y2+y3+y4⇒y=4y1+y2+y3+y4
这里的结果不就是算术平均值 y ˉ \bar{y} yˉ 么。
高斯分布
前面最小二乘法提到,对每一个预测值和真实值之间都会有一个误差 ϵ i \epsilon _{i} ϵi:
ϵ i = y ^ − y i \epsilon _{i} = \widehat{y} -y_{i} ϵi=y −yi
这些误差最终会形成一个概率分布,假设这个未知的分布的概率密度函数为:
f ( ϵ ) f\left ( \epsilon \right ) f(ϵ)
因为每步实验都是假设独立的,所以最终的联合概率分布可以表示为:
L ( θ ) = f ( ϵ 1 ) f ( ϵ 2 ) ⋅ ⋅ ⋅ f ( ϵ n ) = f ( y ^ − y 1 ) f ( y ^ − y 2 ) ⋅ ⋅ ⋅ f ( y ^ − y n ) L\left ( \theta \right ) = f\left ( \epsilon _{1} \right )f\left ( \epsilon _{2} \right )\cdot \cdot \cdot f\left ( \epsilon _{n} \right ) \\ = f\left ( \widehat{y} -y_{1} \right )f\left ( \widehat{y} -y_{2} \right )\cdot \cdot \cdot f\left (\widehat{y} -y_{n}\right ) L(θ)=f(ϵ1)f(ϵ2)⋅⋅⋅f(ϵn)=f(y −y1)f(y −y2)⋅⋅⋅f(y −yn)
这里数学王子高斯没有采用贝叶斯的推理方式,而是直接采用了最大似然估计的方法求解上面的 L ( θ ) L\left ( \theta \right ) L(θ), 而为了配合最小二乘法的结果,去寻找一个最大似然估计值刚好是算术平均的似然函数 f f f,最终高斯证明,所有的概率密度函数中,唯一满足条件的是:
f ( x ) = 1 2 π σ e − x 2 2 σ 2 f(x)=\frac{1}{\sqrt{2\pi \sigma }}e^{-\frac{x^{2}}{2\sigma ^{2}}} f(x)=2πσ1e−2σ2x2
上面的概率分布正是服从 N ( 0 , σ 2 ) \mathcal N(0,\sigma^2) N(0,σ2) 正态分布的概率密度函数了!
将正态分布的概率密度函数代入 L ( θ ) L\left ( \theta \right ) L(θ)表达式可得:
L ( θ ) = 1 ( 2 π σ ) n e x p { − 1 2 σ 2 ∑ i = 1 n ϵ i 2 } L\left ( \theta \right )=\frac{1}{(\sqrt{2\pi \sigma })^n}exp\left \{ -\frac{1}{2\sigma ^{2}}\sum_{i=1}^{n}\epsilon _{i}^2\right \} L(θ)=(2πσ)n1exp{−2σ21i=1∑nϵi2}
这里想要 L ( θ ) L\left ( \theta \right ) L(θ) 取最大值,就需要 ∑ i = 1 n ϵ i 2 \sum_{i=1}^{n}\epsilon _{i}^2 ∑i=1nϵi2 取最小值, 刚好就是最小二乘法的要求。
中心极限定理与大数定理
这里再多说几句,既然涉及到数学知识,就一并多查了一些资料,因为在整理上面内容的时候不可避免的会遇到中心极限定理和大数定理,这里简单说一下这两个定理的思想。
- 大数定理:随着样本容量 n 的增加,样本平均数将接近于总体平均数。
- 中心极限定理:随着样本容量 n 的增加,这 n 个数的均值将趋近于正态分布。
从大数定律可以知道,随着发生次数的增加,偶然最终会服从于必然(如一个猜大小的赌博游戏如果只有大,小两个选项,且发生概率各为 0.5,则长期来看这个赌博游戏会维持在输赢金额平衡,不会给赌场带来盈利也不会让赌场输钱),而中心极限定理则是可以通过部分样本来推测整体样本的分布情况(通过调查美国某地2000个人的投票意向,来预测本地对美国大选的得票数的影响)。
浅谈回归
基本概念
回归是指研究因变量与自变量之间确定的因果关系,建立回归模型,并根据实测数据来求解模型的各个参数,如果可以很好的拟合,则根据自变量进一步预测。
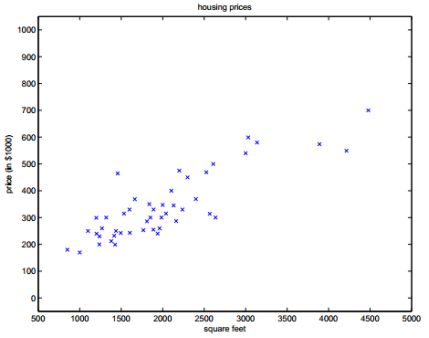
y = a x + b y=ax+b y=ax+b
来进行拟合。 当最终确定 a a a 和 b b b 的值以后对于一个新的 x x x,代入方程就可以直接得到一个 y y y 值。
线性回归
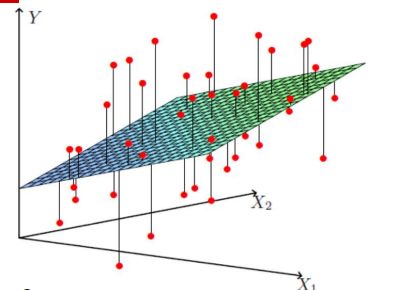
顾名思义,对于线性回归,其回归模型是一个线性表达式,直接根据下面的两张图来表示分别表示当考虑一维因素和考虑二维因素时对应的线性回归结果:
 …
…
以两个自变量 x 1 x_1 x1, x 2 x_2 x2 为例,我们可以直接将线性回归模型的表达式表示为:
h θ ( x ) = θ 2 x 2 + θ 1 x 1 + θ 0 = ∑ i = 0 2 θ i x i = θ T x h_\theta(x) = \theta_2x_2+ \theta_1x_1+ \theta_0=\sum_{i=0}^{2}\theta_ix_i=\bf{\theta}^T\bf{x} hθ(x)=θ2x2+θ1x1+θ0=i=0∑2θixi=θTx
以加粗以后的字符表示 向量/矩阵。对于这个模型对于每一对 x 1 x_1 x1, x 2 x_2 x2 ,本身就有一个真实值 y y y,此外我们还可以得有一个预测值 y ^ = θ T x \widehat{y}=\bf{\theta}^T\bf{x} y =θTx,
这里的误差:
ϵ = ∣ y − y ^ ∣ = ∣ y − θ T x ∣ \epsilon= |y-\widehat{y}|=|y-\bf{\theta}^T\bf{x}| ϵ=∣y−y ∣=∣y−θTx∣
根据中心极限定理可得 ϵ \epsilon ϵ 的分布是服从高斯分布的,将(6) 式代入高斯分布的概率函数中((3) 式)最终可以得到形如(4)式的似然函数:
L ( θ ) = ∏ i = 1 n 1 2 π σ e x p { − ( y i − θ T x i ) 2 2 σ 2 } L\left ( \theta \right )=\prod_{i=1}^{n}\frac{1}{\sqrt{2\pi \sigma }}exp\left \{ - \frac{\left ( y^i-{\bf{\theta}}^T{\bf{x}}^i \right )^2}{2\sigma ^2} \right \} L(θ)=i=1∏n2πσ1exp{−2σ2(yi−θTxi)2}
对上面的形式取 l o g log log:
l ( θ ) = l o g L ( θ ) = l o g ∏ i = 1 n 1 2 π σ e x p { − ( y i − θ T x i ) 2 2 σ 2 } = ∑ i = 1 n l o g 1 2 π σ e x p { − ( y i − θ T x i ) 2 2 σ 2 } = m l o g 1 2 π σ − 1 σ 2 ⋅ 1 2 ∑ i = 1 n ( y i − θ T x i ) 2 l\left ( \theta \right )=logL\left ( \theta \right )\\ = log\prod_{i=1}^{n}\frac{1}{\sqrt{2\pi \sigma }}exp\left \{ - \frac{\left ( y^i-{\bf{\theta}}^T{\bf{x}}^i \right )^2}{2\sigma ^2} \right \} \\ =\sum_{i=1}^{n}log\frac{1}{\sqrt{2\pi \sigma }}exp\left \{ - \frac{\left ( y^i-{\bf{\theta}}^T{\bf{x}}^i \right )^2}{2\sigma ^2} \right \} \\ = mlog\frac{1}{\sqrt{2\pi \sigma }}-\frac{1}{\sigma ^2}\cdot \frac{1}{2}\sum_{i=1}^{n}\left ( y^i-{\bf{\theta}}^T{\bf{x}}^i \right )^2 l(θ)=logL(θ)=logi=1∏n2πσ1exp{−2σ2(yi−θTxi)2}=i=1∑nlog2πσ1exp{−2σ2(yi−θTxi)2}=mlog2πσ1−σ21⋅21i=1∑n(yi−θTxi)2
求(8)式最大就被转化为了求(9)式最小,最终由 (8) 式可以得到我们的目标函数可以简化为:
J ( θ ) = 1 2 ∑ i = 1 n ( θ T x i − y i ) 2 J\left ( \theta \right )= \frac{1}{2}\sum_{i=1}^{n}\left ( {\bf{\theta}}^T{\bf{x}}^i -y^i\right )^2 J(θ)=21i=1∑n(θTxi−yi)2
将 (9) 式都转化成矩阵表示形式:
J ( θ ) = 1 2 ( X θ − y ) T ( X θ − y ) J\left ( \theta \right )=\frac{1}{2}\left ( X{\bf{\theta}}-{\bf{y}} \right )^T\left ( X\theta-{\bf{y}}\right ) J(θ)=21(Xθ−y)T(Xθ−y)
最小二乘法意义下的解析解
这里首先得知道线性代数中关于矩阵求导的几个公式:
∂ θ T A ∂ θ = A ∂ A θ ∂ θ = A T ∂ θ T A θ ∂ θ = 2 A θ \\ \frac{\partial \theta^TA}{\partial \theta}=A \\ \\ \frac{\partial A\theta}{\partial \theta}=A^T \\ \\ \frac{\partial \theta^TA\theta}{\partial \theta}=2A\theta ∂θ∂θTA=A∂θ∂Aθ=AT∂θ∂θTAθ=2Aθ
由公式(11)可以推导出 J ( θ ) J(\theta) J(θ) 对于 θ \theta θ 的偏导为:
J ( θ ) = 1 2 ( θ T X T X θ − θ T X T y − y T X θ + y T y ) ∂ J ( θ ) ∂ θ = 1 2 ( 2 X T X θ − X T y − ( y T X ) T ) , 又 因 为 ( y T X ) T = X T y \\ J(\theta)=\frac{1}{2}\left ( \theta^TX^TX\theta-\theta^TX^T{\bf{y}}-{\bf{y}}^TX\theta+{\bf{y}}^T{\bf{y}} \right ) \\ \frac{\partial J(\theta)}{\partial \theta}=\frac{1}{2}\left ( 2X^TX\theta-X^T{\bf{y}}-\left ( {\bf{y}}^TX \right )^T \right ), 又因为\left ({\bf{y}}^TX \right )^T =X^T{\bf{y}} J(θ)=21(θTXTXθ−θTXTy−yTXθ+yTy)∂θ∂J(θ)=21(2XTXθ−XTy−(yTX)T),又因为(yTX)T=XTy
∂ J ( θ ) ∂ θ = 1 2 ( 2 X T X θ − 2 X T y ) = X T X θ − X T y \frac{\partial J(\theta)}{\partial \theta}=\frac{1}{2}\left ( 2X^TX\theta-2X^T{\bf{y}}\right )=X^TX\theta-X^T{\bf{y}} ∂θ∂J(θ)=21(2XTXθ−2XTy)=XTXθ−XTy
另式(12) 为 0,最终求得 θ \theta θ 的解析解为:
θ = ( X T X ) − 1 X T y \theta=(X^TX)^{-1}X^T{\bf{y}} θ=(XTX)−1XTy
为了保证 ( X T X ) − 1 (X^TX)^{-1} (XTX)−1 正定成立或者防止过拟合,增加了一个 λ \lambda λ 扰动:
θ = ( X T X + λ I ) − 1 X T y \theta=(X^TX+\lambda I)^{-1}X^T{\bf{y}} θ=(XTX+λI)−1XTy
其实这里的 λ \lambda λ 扰动对应的就是 L-norm 正则化项,这里顺便引出下面的不同回归形式。
LASSO 回归,岭回归
它们的区别只是最后加入的正则项不一样。
- LASSO 回归(L1-norm):
J ( θ ) = 1 2 ∑ i = 1 n ( θ T x i − y i ) 2 + λ ∑ j = 1 n ∣ θ j ∣ J\left ( \theta \right )= \frac{1}{2}\sum_{i=1}^{n}\left ( {\bf{\theta}}^T{\bf{x}}^i -y^i\right )^2+\lambda \sum_{j=1}^{n}|\theta_{j}| J(θ)=21i=1∑n(θTxi−yi)2+λj=1∑n∣θj∣ - 岭回归 (L2-norm):
J ( θ ) = 1 2 ∑ i = 1 n ( θ T x i − y i ) 2 + λ ∑ j = 1 n θ j 2 J\left ( \theta \right )= \frac{1}{2}\sum_{i=1}^{n}\left ( {\bf{\theta}}^T{\bf{x}}^i -y^i\right )^2+\lambda \sum_{j=1}^{n}\theta_{j}^2 J(θ)=21i=1∑n(θTxi−yi)2+λj=1∑nθj2
当我们知道了 X矩阵,知道了y矩阵,可以通过解析解直接求出 θ \theta θ 值,但是在实际算法实现过程中,我们很少直接那么做,因为遇到的机器学习问题中可能会遇到特征或者样本数量维度很大的情况(百万级别),这个时候直接求解析解就显得不那么现实了。
梯度下降算法
对于梯度下降算法的原理不再赘述了,相信大家都有所了解,我们需要沿着 J ( θ ) J(\theta) J(θ)的负梯度的方向,更新 θ \theta θ使之最小。
θ = θ − α ∂ J ( θ ) ∂ θ \theta=\theta-\alpha \frac{\partial J(\theta)}{\partial \theta} θ=θ−α∂θ∂J(θ)
α \alpha α 为学习率,其中:
∂ J ( θ ) ∂ θ i = ∂ ∂ θ 1 2 ( h θ ( x ) − y ) 2 = ( h θ ( x ) − y ) ∂ ∂ θ i ( ∑ i = 1 n θ i x i − y ) = ( h θ ( x ) − y ) x i \\ \frac{\partial J(\theta)}{\partial \theta_{i}}=\frac{\partial }{\partial \theta}\frac{1}{2}(h_{\theta}(x)-y)^2 \\ =(h_{\theta}(x)-y)\frac{\partial }{\partial \theta_{i}}\left ( \sum_{i=1}^{n} \theta_{i}x_{i}-y\right ) =(h_{\theta}(x)-y)x_{i} ∂θi∂J(θ)=∂θ∂21(hθ(x)−y)2=(hθ(x)−y)∂θi∂(i=1∑nθixi−y)=(hθ(x)−y)xi
所以最后的表现形式为:
θ j : = θ j − α ∑ i = 1 m ( h θ ( x i ) − y i ) x j i \theta_{j}:=\theta_{j}-\alpha \sum_{i=1}^{m}\left ( h_\theta\left ( x^{i} \right )-y^{i} \right )x_{j}^{i} θj:=θj−αi=1∑m(hθ(xi)−yi)xji
最后根据公式(17)一步步收敛到全局最优,这里的 m m m 代表样本数,通常就是我们训练时设置的的 batch size。

Logistic 回归
用回归做分类问题就不能直接用线性回归了,这节要谈到的 Logistic回归才是回归做分类(二分类)的首选工具,多类别分类的 Logistic回归也称做 Softmax 回归。这里我们以经典的二分类为例进行说明。
线性回归的回归模型可以简单的表示为: h θ ( x ) = θ T x h_\theta(x) =\bf{\theta}^T\bf{x} hθ(x)=θTx
这里 Logistic 回归则是用到了 Logistic/ sigmoid 函数来表达回归模型:
h θ ( x ) = g ( θ T x ) = 1 1 + e x p { − θ T x } h_\theta(x)=g(\bf{\theta}^T\bf{x}) =\frac{1}{1+exp\left \{-{\bf{{\theta}^T\bf{x}}} \right \} } hθ(x)=g(θTx)=1+exp{−θTx}1
Logistic/ sigmoid 函数 g ( x ) g\left ( x \right ) g(x) 的函数曲线如下图所示,可以看到最后的数值的范围是[0,1]之间。
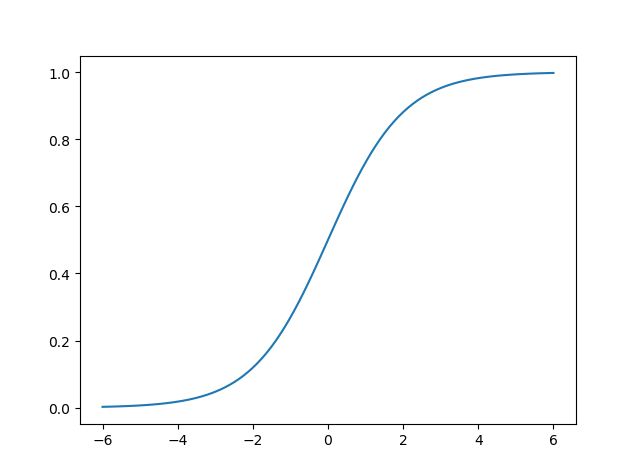
g ′ ( x ) = g ( x ) ( 1 − g ( x ) ) {g}'\left ( x \right )=g\left ( x \right )\left ( 1- g\left ( x \right ) \right ) g′(x)=g(x)(1−g(x))
参数估计
由上面的 logistic 最后取值范围是 [0,1] 之间的性质,我们可以直接将 h θ ( x ) h_\theta(x) hθ(x) 看作是一个类别的概率,二分类问题中,另一个问题的概率就是 1 − h θ ( x ) 1-h_\theta(x) 1−hθ(x),用数学语言表示即:
P ( y ∣ x ; θ ) = { h θ ( x ) , y = 1 1 − h θ ( x ) , y = 0 P(y|x;\theta)=\left\{\begin{matrix} h_\theta(x) , y=1 \\ 1-h_\theta(x), y=0 \end{matrix}\right. P(y∣x;θ)={hθ(x),y=11−hθ(x),y=0
将上式等效转化为:
P ( y ∣ x ; θ ) = ( h θ ( x ) ) y ( 1 − h θ ( x ) ) 1 − y P(y|x;\theta)= \left ( h_\theta(x) \right )^y \left ( 1-h_\theta(x) \right )^{1-y} P(y∣x;θ)=(hθ(x))y(1−hθ(x))1−y
由上面的概率公式可以得到 Logistic 回归的似然函数:
L ( θ ) = ∏ i = 1 m P ( y i ∣ x i ; θ ) L\left ( \theta \right ) =\prod_{i=1}^{m}P(y^i|x^i;\theta) L(θ)=i=1∏mP(yi∣xi;θ) = ∏ i = 1 m ( h θ ( x i ) ) y i ( 1 − h θ ( x i ) ) 1 − y i =\prod_{i=1}^{m}\left ( h_\theta(x^i) \right )^{y^i} \left ( 1-h_\theta(x^i) \right )^{1-{y^i}} =i=1∏m(hθ(xi))yi(1−hθ(xi))1−yi
对上面的式子取对数可以得到:
l ( θ ) = l o g L ( θ ) = ∑ i = 1 m y i l o g ( h θ ( x i ) ) + 1 − y i l o g ( 1 − h θ ( x i ) ) \\ l\left ( \theta \right )=log L\left ( \theta \right ) \\ =\sum_{i=1}^{m}{y^i} log\left ( h_\theta(x^i) \right )+ {1-{y^i}}log\left ( 1-h_\theta(x^i) \right ) l(θ)=logL(θ)=i=1∑myilog(hθ(xi))+1−yilog(1−hθ(xi))
对式(21)求导可以得到:
∂ ∂ θ j l ( θ ) = ( y 1 g ( θ T X ) − ( 1 − y ) 1 1 − g ( θ T X ) ) ∂ ∂ θ j g ( θ T X ) \frac{\partial }{\partial \theta_{j}}l\left ( \theta \right )=\left ( y\frac{1}{g\left ( \theta^T X \right )}-\left ( 1-y\right )\frac{1}{1-g\left ( \theta^T X \right )} \right )\frac{\partial }{\partial \theta_{j}}g\left ( \theta^T X \right ) ∂θj∂l(θ)=(yg(θTX)1−(1−y)1−g(θTX)1)∂θj∂g(θTX)
= ( y 1 g ( θ T X ) − ( 1 − y ) 1 1 − g ( θ T X ) ) g ( θ T X ) ( 1 − g ( θ T X ) ) ∂ ∂ θ j θ T X =\left (y\frac{1}{g\left ( \theta^T X \right )}-\left ( 1-y\right )\frac{1}{1-g\left ( \theta^T X \right )} \right )g\left ( \theta^T X \right )\left ( 1-g\left ( \theta^T X \right ) \right )\frac{\partial }{\partial \theta_{j}} \theta^T X =(yg(θTX)1−(1−y)1−g(θTX)1)g(θTX)(1−g(θTX))∂θj∂θTX
= ( y ( 1 − g ( θ T X ) ) − ( 1 − y ) g ( θ T X ) ) x j = ( y − h θ ( x ) ) x j =\left ( y\left ( 1-g\left ( \theta^T X \right ) \right ) -\left ( 1-y \right )g\left ( \theta^T X \right )\right )x_{j} =\left ( y-h_{\theta}\left ( x \right ) \right )x_{j} =(y(1−g(θTX))−(1−y)g(θTX))xj=(y−hθ(x))xj
最后同样使用梯度下降算法对 Logistic 模型进行迭代巡练:
θ j : = θ j − α ∑ i = 1 m ( h θ ( x i ) − y i ) x j i \theta_{j}:=\theta_{j}-\alpha \sum_{i=1}^{m}\left ( h_\theta\left ( x^{i} \right )-y^{i} \right )x_{j}^{i} θj:=θj−αi=1∑m(hθ(xi)−yi)xji
(注:这里 Logistic 回归没有解析解,所以只能用梯度算法求解)
与线性回归的关系
上面的分析可以看到线性回归与 Logistic 回归有相同的梯度更新形式。因为 Logistic 回归是对数线性模型。
一个事件的几率(odd)指该事件发生的概率与该事件不发生的概率的比值,对数几率就是对几率的表达式取对数,即:
l o g i t ( p ) = l o g p 1 − p = l o g h θ ( x ) 1 − h θ ( x ) = l o g ( 1 1 + e − θ T X e − θ T X 1 − e − θ T X ) = θ T X logit(p)=log\frac{p}{1-p}=log\frac{h_{\theta}\left ( x \right )}{1-h_{\theta}\left ( x \right )}=log\left ( \frac{\frac{1}{1+e^{- \theta^T X}}}{\frac{e^{- \theta^T X}}{1-e^{- \theta^T X}}} \right )= \theta^T X logit(p)=log1−pp=log1−hθ(x)hθ(x)=log⎝⎛1−e−θTXe−θTX1+e−θTX1⎠⎞=θTX
主要参考文献:
如何理解最小二乘法?
正态分布的前世今生 (上)
https://en.wikipedia.org/wiki/Matrix_calculus#Scalar-by-vector_identities