residual attention network 论文解读
论文下载链接:https://arxiv.org/abs/1704.06904
github代码下载链接caffe:https://github.com/fwang91/residual-attention-network
摘要简介
在本篇论文中,提出了Residual attention network,该网络利用attention机制(可以将该结构使用到现有的端到端的卷积网络中),Residual attention network网络采样将attention结构堆叠的方法来改变特征的attention。并且随着网络的加深,attention module会做适应性的改变,在每一个attention modual中,采用上采样和下采样结构,另外作者提出了attention residual learning去训练更深的网络。
【文章的主要创新点】
- stacked network structure:通过堆叠多个attention modules来构建residual attention network,这点跟其他的深度网络很像的。
- attention residual learning:如果仅仅是堆叠attention modules,很明显会使得模型的精度降低,所以作者提出了learning的思想,来优化residual attention network
- bottom-up top-down feedforward attention: bottom-up top-down就是FCN中的特征图先变小,然后通过上采样将图像变大的方法,作者利用这种方法将特征权重添加到特征图上
下面简要介绍一下这篇文章
先抛一张attention结构图
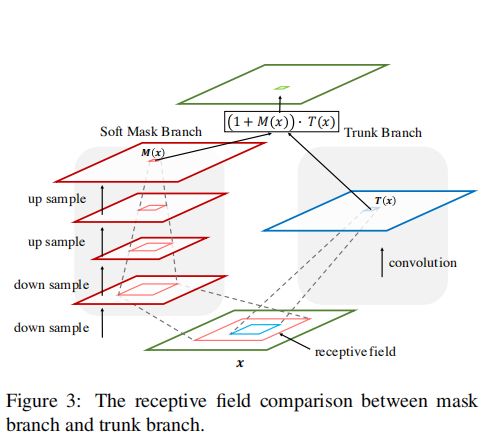
根据上图结构可知,作者将每个Attention Module分成2个分支,分别为mask branch(attention部分)以及trunk banch(原始部分),attention的输出利用公式代表如下,其中T代表trunk banch,M代表mask branch,公式很清晰。
H i , c ( x ) = M i , c ( x ) ∗ T i , c ( x ) H_{i,c}(x)=M_{i,c}(x)*T_{i,c}(x) Hi,c(x)=Mi,c(x)∗Ti,c(x)
并且作者在论文中提到: 在attention modules中attention mask不仅仅在前向传播中进行特征的选择,并且在反向传播中也是对梯度的过滤,mask的导数如下: θ \theta θ代表mask的参数, ψ \psi ψ代表trunk的参数,这里先留一个疑问,反向传播的时候mask如何处理??
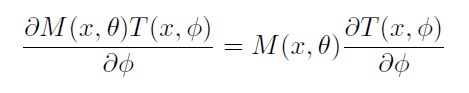
如果仅仅使用一个简单网络的分支去产生mask会怎么样呢?
- 图像背景复杂,需要不同的attentions, 这样使用简单的分支网络就需要channel的指数倍去对应不同的参数组合,这里怎么理解呢?比如这张图有天空、草地很多的attention,那就需要多种组合了,一个肯定是不够了,这样就需要很多的attention网络了。
- 简单的attention只是修改了一次的features,如果修改错了,或者没修改就会出现问题了。
attention的好处在哪里呢?
如下图所示,下图中既有气球,又有背景(蓝天),所以采用本文的堆叠attention modules的方法,前面层可以提取背景的attention,后面层可以提取气球的attention,前后结合就很好的目标提取出来了。

attention residual learning
但是,很显然如果只是简单的堆叠,效果肯定不会好,不然早就有人发明出来attention network了,但是这里作者也解释了一下为什么这样简单的做法效果不好:
- mask的范围是0-1,重复的相乘会使得特征值逐渐变小
- mask可能会破坏trunk branch的好的特性,比如resnet中的恒等。
基于这,作者提出了attention residual learning,咋搞的?如下:M代表mask,F代表feature map,这就有点类似于resnet,即使M的大小为0,我们还保留着F(x)的大小,这就是作者所谓的attention residual learning
H i , c ( x ) = ( 1 + M i , c ( x ) ) ∗ F i , c ( x ) H_{i,c}(x) = (1+M_{i,c}(x))*F_{i,c}(x) Hi,c(x)=(1+Mi,c(x))∗Fi,c(x)
soft mask branch
mask branch作者主要采用简单的类似于FCN的网络实现,首先,针对输入,采用几次max pooling去增加感受野,达到最小分辨率之后,利用一个对称的网络结构将特征放大回去。这里作者表述,使用线性插值进行放大:
原文表述如下:
Linear interpolation up sample the output after some Residual Units. The number of bilinear interpolation is the same as max pooling to keep the output size the same as the input feature map.
然后,接2个1*1的卷积层,最后在output后面接一个sigmoid layer,将输出归一化到[0,1]区间。另外,在mask branch中,作者增加了skip connection 在bottom-up , top-down 之间。
另外,作者在这里解释到,虽然我们这同样采用了FCN网络,但是与之不同的是,FCN直接应用于复杂问题,而我们这里是应用到提高trunk branch的feature的质量,两者的目的不同。
网络结构如下图所示:图例给的很好,很清晰
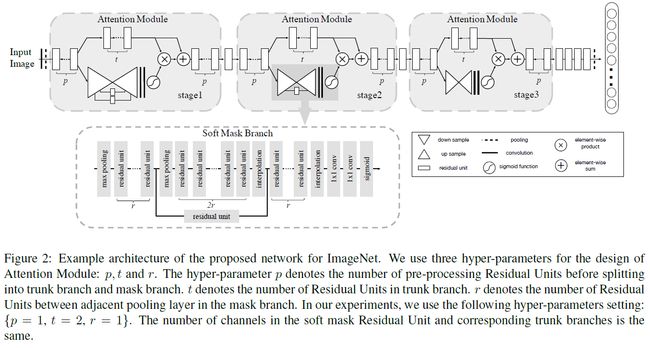
这里需要注意一下,stage1的mask中间有两个连接,stage2的mask中有一个连接,stage3中mask没有连接
spatial attention and channel attention
这里作者想,针对mask branch,同样可以采用一些方法进行约束,使之达到最好的效果,这里作者尝试了3种方法:mixed attention, channel attention, spatial attention,其公式分别为f1,f2,f3 表示如下:
其中,f1就是对每个channel的每个位置进行sigmoid操作,f2,对每个位置,求所有channel的L2范数,f3,对每个channel先进行标准化,然后对每个位置进行sigmoid操作。
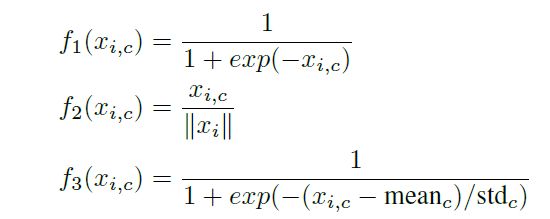
实验结果如图所示,采用的是Attention-56网络:

Experiments
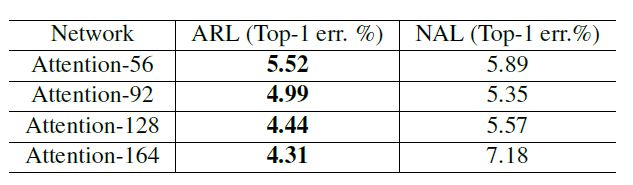
作者首先对比了attention residual learning的作用,作者采用含有learning的模块(ARL)以及不含learning的模块(NAL)分别进行实验,实验结果如下,可以看出带学习的完胜。
为了一探究竟,作者计算了每个stage的output的mean absolute response,网络采用attention-164,实验结果如下图所示:

可以发现,不带学习的话,在第二个stage的时候,response已经降为0了,这样哪会有效果尼。。。。为什么会这样呢?作者解释到:
attention module 通过重复的mask以及feature进行点积来抑制噪声,增强有效信息,但是重复的点积不仅会抑制噪声的梯度同时会抑制有用信息的梯度,所以,通过learning的方法,增加了identical mapping单元可以增强信号的传播。
原文是这么解释的:The Attention Module is designed to suppress noise while keeping useful information by applying dot product between feature and soft mask. However, repeated dot product will lead to severe degradation of both useful and useless information in this process. The attention residual learning can relieve signal attenuation using identical mapping, which enhances the feature contrast.
Comparison of different mask structures
另外作者进行了mask的对比,对比结果发现采用encoder and decoder的mixed attention效果会好一些,如下图:

前面的实验都是在cifar数据集上测试的,那么在imagenet上的结果如何呢?
结果如下图
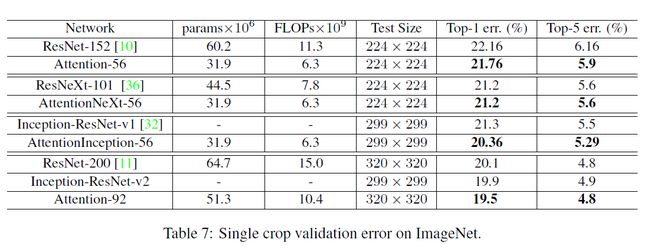
不难发现,attention的方法提升效果还是很显著的。
下面展示一下作者提供的caffe.prototxt中的代码,有利于实现:
attention-56代码链接:https://github.com/fwang91/residual-attention-network/blob/master/imagenet_model/Attention-56-deploy.prototxt
将上面的网络prototxt复制到下面的链接,按shift+enter就可以看到网络的形状了
展示网络形状的网页链接
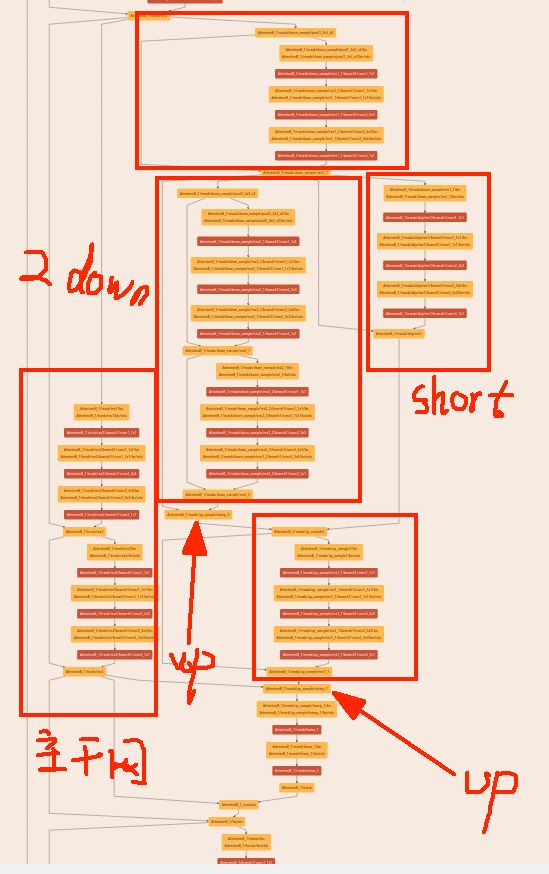
结合figure2提供的说明看这个网络更好理解,attention-56就是按照这个来的,r=1,下面对mask进行介绍:
这里需要突出的是,caffe中的interp层,attention-56采用interp进行上采样,有的博客说这里采用decon(反卷积)也可以,这里截取的是attention-56的第二个stage的attention部分,这里可能看不清,主要是让大家对整体的结构有个概念,这里具备了上面figure2中stage2的所有元素,这里我就不详细的展开了,感兴趣的可以参考作者github提供的代码进行查看,需要强调的是,这里的上采样就是采用interp实现的,知道这点,参考作者的fiture2就很好理解了。