自然语言处理-文本分析学习记录
一、TF_IDF
1.1 TF(term frequency) : 即词频统计
去掉停用词 : 的、是、在
《中国蜜蜂养殖》这篇文章中,出现最多的是中国,蜜蜂养殖,但中国不是关键词,我们怎么让蜜蜂养殖成为主体的,此时就需要IDF
1.2 IDF(Inverse Document Frequency)
如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反应了这篇文章的特性正是我们所需要的关键词.
1.3 TF_IDF 计算公式
词频(TF) = 某个词在文章中出现次数 / 文章总的词数
逆文档频率(IDF) = log(语料库的文档总数 / 包含该词的文档数 + 1) 以10为底,+1是因为分母不能为0.
关键词是由 TF * IDF决定
举例
(1)假设《中国蜜蜂养殖》这个文章总共1000个词,“中国”“蜜蜂” "养殖"各出现20词,则这三个词的词频(TF)都为0.02
(2)搜索谷歌发现,包含"的"的网页共250亿张,假定这就是中文网页总数,包含"中国"的网页共有63.3亿张,包含"蜜蜂"的网页为0.484亿张,包含"养殖"的网页为0.973亿张
| 包含该词的文档数(亿) | IDF | TF-IDF | |
|---|---|---|---|
| 中国 | 62.3 | 0.597 | 0.0119 |
| 蜜蜂 | 0.484 | 2.227 | 0.0445 |
| 养殖 | 0.973 | 2.103 | 0.0421 |
二、one-hot,N-gram,word2vec概念区分
https://blog.csdn.net/jiede1/article/details/80803171
什么是词向量?(NPL入门)
https://blog.csdn.net/mawenqi0729/article/details/80698350
分布表示(distributional representation)与分布式表示(distributed representation)
https://blog.csdn.net/david0611/article/details/80691043
word2Vec理解
https://blog.csdn.net/Torero_lch/article/details/82350713
三、 jieba使用记录
python join方法
str.join(sequence)
str – 分隔符
sequence – 要连接的元素序列
>>> seq = ['r','u','n']
>>> print("-".join(seq))
输出 r-u-n
3.1 分词功能
jieba.cut 方法接受三个输入参数: 需要分词的字符串;cut_all 参数用来控制是否采用全模式;HMM 参数用来控制是否使用 HMM 模型
>>> seg_list = jieba.cut('我来到北京大学',cut_all = False,HMM = True)
>>> print("/".join(seg_list))
我/来到/北京大学
jieba.lcut 直接返回 list
一个简单示例模板(读取txt内容并分词)
import jieba
with open("filename",'r') as words_after_jieba:
seq = jieba.cut(words_after_jieba.read(),cut_all=False)
print("/".join(seq))
文件读写参考廖雪峰Python教程
https://www.liaoxuefeng.com/wiki/1016959663602400/1017607179232640
分词理论(机器学习/统计方法) : HMM、CRF条件随机场.

[使用gensim和sklearn搭建一个文本分类器(一):流程概述]
https://blog.csdn.net/u014595019/article/details/52433754/
3.2 jieba 基于TF-IDF、TextRank 算法的关键词抽取
import sys
sys.path.append('../')
import jieba
import jieba.analyse
from optparse import OptionParser
file_name = "filename"
content = open(file_name, 'rb').read()
tags_TF_IDF = jieba.analyse.extract_tags(content, topK=5)
tags_TextRank = jieba.analyse.textrank(content, topK=5)
print(",".join(tags_TF_IDF))
print(",".join(tags_TextRank))
四、文本分析的流程


上图单词解释:
Tokenize即分词的意思,POS是指词性.
处理完成后得到如下 : [‘今天’,‘天气’,‘不错’]
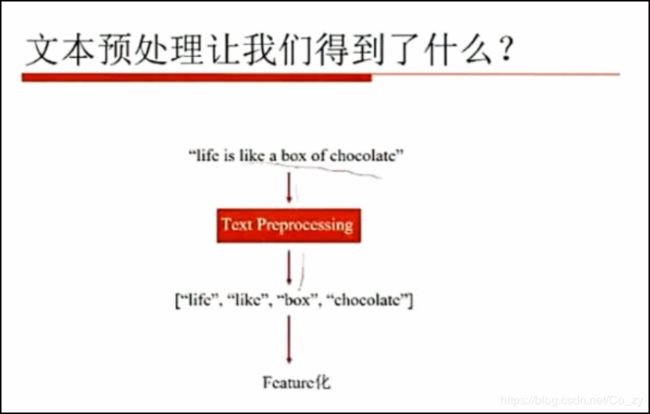
之后再进行处理,根据具体情况而定
- 情感分析
- 文本相似度
- 文本分类
情感分析
情感词典
like 1
good 2
bad -2
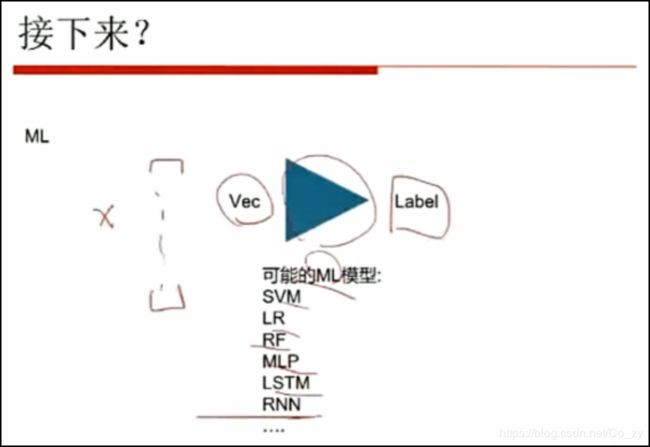
最简单的方式就是遍历一遍然后打分,但是如果遇到生词,这种方法就无效了,此时需要机器学习
待填充