利用Python对瓦尔登湖进行词频统计
一、目的
深入理解列表的使用,利用python对瓦尔登湖文本(英文)进行词频统计。
二、必要知识
1.python数据结构

2.数据结构的推导式(List Comprehension)
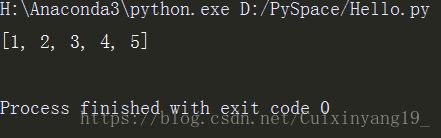
如我们需要将5个元素装进列表中,写法:
b = [i for i in range(1,6)]
#显示列表
print(b)运行结果:
3.split分词
实例:
sentence = "Something that stays in your mind will someday spring up in your life"
words = sentence.split()
print(words)运行结果:

三、实例代码
import string
#文章路径
path = 'C://Users/Yang/Desktop/Walden.txt'
with open(path,'r') as text:
#去掉文字首位的标点符号,并把首字母大写转换成小写
words = [raw_word.strip(string.punctuation).lower() for raw_word in text.read().split()]
#将列表用set函数转换成集合
words_index = set(words)
#创建一单词为key,频率为值的字典
counts_dict = {index:words.count(index) for index in words_index}
#打印整理后的参数,其中利用lambda表达式,以字典中的值为排序的参数
for word in sorted(counts_dict,key=lambda x: counts_dict[x],reverse=True):
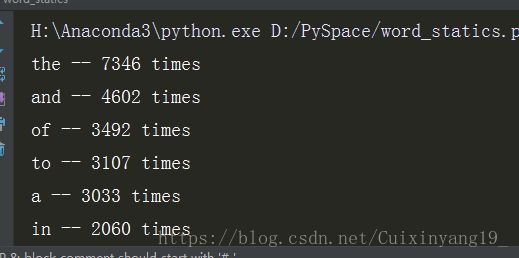
print('{} -- {} times'.format(word,counts_dict[word]))四、运行结果