Tensorflow深度学习之二十一:LeNet的实现(CIFAR-10数据集)
一、LeNet的简介
LeNet是一个用来识别手写数字的最经典的卷积神经网络,是Yann LeCun在1998年设计并提出的。Lenet的网络结构规模较小,但包含了卷积层、池化层、全连接层,他们都构成了现代CNN的基本组件。
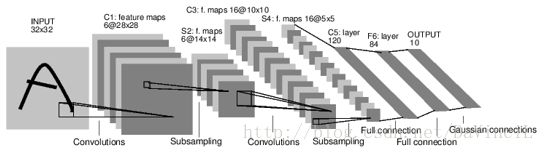
LeNet包含输入层在内共有八层,每一层都包含多个权重。C层代表卷积层,通过卷积操作,可以使原信号特征增强,并降低噪音。S层是一个池化层,利用图像局部相关性的原理,对图像进行子抽样,可以减少数据处理量,同时也保留了一定的有用信息。
- 第一层:输入层是32 * 32大小的图像。
- C1层是一个卷积层,6个特征图谱(feature map),5*5大小的卷积核,每个feature map有(32-5+1) * (32-5+1),即28 * 28个神经元,每个神经元都与输入层的5 * 5大小的区域相连。故C1层共有(5 * 5 + 1) * 6 = 156个训练参数。5 * 5个连接参数+1个偏置参数,两层之间的连接数为156 * (28 * 28) = 122304个。通过卷积运算,使原信号特征增强,并且降低噪音,而且不同的卷积核能够提取到图像的不同特征。
- S2层是一个下采样层,有6个14 * 14的特征图,每个feature map中的每个神经元都与C1层对应的feature map中的2 * 2的区域相连。S2层中的每个神经元是由这4个输入相加,乘以一个训练参数,再加上这个feature map的偏置参数,结果通过sigmoid函数计算而得。S2的每一个feature map有14 * 14个神经元,参数个数为2 * 6 = 12个,连接数为(4+1) * (14 * 14) * 6 = 5880个连接。池化层的目的是为了降低网络训练参数及模型的过拟合程度。池化方式有最大池化和平均池化两种。
- C3层也是一个卷积层,运用5 * 5的卷积层,处理S2层。计算C3的feature map的神经元个数为(14-5+1) * (14-5+1),即10 * 10。C3有16个feature map,每个feature map由上一层的各feature map之间的不同组合。
- S4层是一个下采样层,由16个5 * 5大小的feature map构成,每个神经元与C3中对应的feature map的2 * 2大小的区域相连。同理,计算出2 * 16 = 32 个参数和2000个连接。
- C5层又是一个卷积层,同样使用5 * 5的卷积核,每个feature map有(5-5+1) * (5-5+1),即1 * 1的神经元,每个单元都与S4层的全部16个feature map的5 * 5区域相连。C5层共有120个feature map,其参数与连接数都为48120个。
- F6层全连接层共有84个feature map,每个feature map只有一个神经元与C5层全连接,故有(1 * 1 * 120 + 1) * 84 = 10164个参数和连接。F6层计算输入向量和权重向量之间的点积和偏置,之后将其传递给sigmoid函数来计算神经元。
- 输出层也是全连接层,共有10个节点,分别代表数字0到9。
(以上资料参考《深度学习—Caffe之经典模型详解与实战》)
二、利用Tensorflow(Keras)实现LeNet
这里使用LeNet实现CIFAR-10数据集的分类。
训练完成后的文件目录如下:
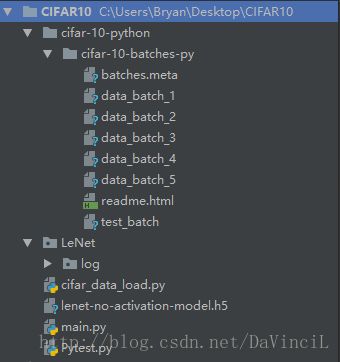
| 名称 | 作用 |
|---|---|
| cifar-10-python | 文件夹,CIFAR-10数据集 |
| LeNet\log | 文件夹,用于存放程序运行时的日志信息,可使用TensorBoard查看 |
| cifar_data_load.py | 加载CIFAR-10数据集 |
| lenet-no-activation-model.h5 | 保存的模型文件 |
| main.py | 训练模型 |
| Pytest.py | 利用模型进行预测 |
CIFAR-10数据集加载 cifar_data_load.py:(详情见Tensorflow深度学习之二十:CIFAR-10数据集介绍)
import numpy as np
import pickle
def unpickle(file):
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
def GetPhoto(pixel):
assert len(pixel) == 3072
r = pixel[0:1024]; r = np.reshape(r, [32, 32, 1])
g = pixel[1024:2048]; g = np.reshape(g, [32, 32, 1])
b = pixel[2048:3072]; b = np.reshape(b, [32, 32, 1])
photo = np.concatenate([r, g, b], -1)
return photo
def GetTrainDataByLabel(label):
batch_label = []
labels = []
data = []
filenames = []
for i in range(1, 1+5):
batch_label.append(unpickle("cifar-10-python/cifar-10-batches-py/data_batch_%d"%i)[b'batch_label'])
labels += unpickle("cifar-10-python/cifar-10-batches-py/data_batch_%d"%i)[b'labels']
data.append(unpickle("cifar-10-python/cifar-10-batches-py/data_batch_%d"%i)[b'data'])
filenames += unpickle("cifar-10-python/cifar-10-batches-py/data_batch_%d"%i)[b'filenames']
data = np.concatenate(data, 0)
label = str.encode(label)
if label == b'data':
array = np.ndarray([len(data), 32, 32, 3], dtype=np.int32)
for i in range(len(data)):
array[i] = GetPhoto(data[i])
return array
pass
elif label == b'labels':
return labels
pass
elif label == b'batch_label':
return batch_label
pass
elif label == b'filenames':
return filenames
pass
else:
raise NameError
def GetTestDataByLabel(label):
batch_label = []
filenames = []
batch_label.append(unpickle("cifar-10-python/cifar-10-batches-py/test_batch")[b'batch_label'])
labels = unpickle("cifar-10-python/cifar-10-batches-py/test_batch")[b'labels']
data = unpickle("cifar-10-python/cifar-10-batches-py/test_batch")[b'data']
filenames += unpickle("cifar-10-python/cifar-10-batches-py/test_batch")[b'filenames']
label = str.encode(label)
if label == b'data':
array = np.ndarray([len(data), 32, 32, 3], dtype=np.int32)
for i in range(len(data)):
array[i] = GetPhoto(data[i])
return array
pass
elif label == b'labels':
return labels
pass
elif label == b'batch_label':
return batch_label
pass
elif label == b'filenames':
return filenames
pass
else:
raise NameError
模型的建立以及训练 main.py:
from tensorflow.contrib.keras.api.keras.layers import Input, Conv2D, MaxPool2D, Dense, Flatten
from tensorflow.contrib.keras.api.keras.models import Model
from tensorflow.contrib.keras.api.keras.optimizers import Adam
from tensorflow.contrib.keras.api.keras.callbacks import TensorBoard
from tensorflow.contrib.keras.api.keras.utils import to_categorical
from cifar_data_load import GetTrainDataByLabel, GetTestDataByLabel
# 构建LeNet模型
# 这里使用的LeNet模型与原始的LeNet模型有些不同,除了最后一个连接层dense3使用了softmax激活外,在其他的层均未使用任何激活函数
def lenet(input):
# 卷积层conv1
conv1 = Conv2D(6, 5, (1, 1), 'valid', use_bias=True)(input)
# 最大池化层maxpool1
maxpool1 = MaxPool2D((2, 2), (2, 2), 'valid')(conv1)
# 卷积层conv2
conv2 = Conv2D(6, 5, (1, 1), 'valid', use_bias=True)(maxpool1)
# 最大池化层maxpool2
maxpool2 = MaxPool2D((2, 2), (2, 2), 'valid')(conv2)
# 卷积层conv3
conv3 = Conv2D(16, 5, (1, 1), 'valid', use_bias=True)(maxpool2)
# 展开
flatten = Flatten()(conv3)
# 全连接层dense1
dense1 = Dense(120, )(flatten)
# 全连接层dense2
dense2 = Dense(84, )(dense1)
# 全连接层dense3
dense3 = Dense(10, activation='softmax')(dense2)
return dense3
if __name__ == '__main__':
# 输入
myinput = Input([32, 32, 3])
# 构建网络
output = lenet(myinput)
# 建立模型
model = Model(myinput, output)
# 定义优化器,这里选用Adam优化器,学习率设置为0.0003
adam = Adam(lr=0.0003)
# 编译模型
model.compile(optimizer=adam, loss="categorical_crossentropy", metrics=['accuracy'])
# 准备数据
# 获取输入的图像
X = GetTrainDataByLabel('data')
# 获取图像的label,这里使用to_categorical函数返回one-hot之后的label
Y = to_categorical(GetTrainDataByLabel('labels'))
# 开始训练模型,batch设置为200,一共50个epoch
model.fit(X, Y, 200, 50, 1, callbacks=[TensorBoard('./LeNet/log', write_images=1, histogram_freq=1)],
validation_split=0.2, shuffle=True)
# 保存模型
model.save("lenet-no-activation-model.h5")三、程序运行
程序运行结果如下:
Train on 40000 samples, validate on 10000 samples
Epoch 1/50
40000/40000 [==============================] - 50s - loss: 5.0698 - acc: 0.2403 - val_loss: 1.9617 - val_acc: 0.2933
Epoch 2/50
40000/40000 [==============================] - 52s - loss: 1.9121 - acc: 0.3128 - val_loss: 1.8893 - val_acc: 0.3303
Epoch 3/50
40000/40000 [==============================] - 50s - loss: 1.8527 - acc: 0.3337 - val_loss: 1.8352 - val_acc: 0.3427
Epoch 4/50
40000/40000 [==============================] - 53s - loss: 1.7988 - acc: 0.3555 - val_loss: 1.8037 - val_acc: 0.3538
Epoch 5/50
40000/40000 [==============================] - 57s - loss: 1.7536 - acc: 0.3703 - val_loss: 1.7576 - val_acc: 0.3786
Epoch 6/50
40000/40000 [==============================] - 58s - loss: 1.7092 - acc: 0.3869 - val_loss: 1.7064 - val_acc: 0.3938
Epoch 7/50
40000/40000 [==============================] - 58s - loss: 1.6704 - acc: 0.4009 - val_loss: 1.6921 - val_acc: 0.4041
Epoch 8/50
40000/40000 [==============================] - 58s - loss: 1.6430 - acc: 0.4096 - val_loss: 1.6492 - val_acc: 0.4084
Epoch 9/50
40000/40000 [==============================] - 59s - loss: 1.6110 - acc: 0.4200 - val_loss: 1.6368 - val_acc: 0.4123
Epoch 10/50
40000/40000 [==============================] - 59s - loss: 1.5819 - acc: 0.4347 - val_loss: 1.6017 - val_acc: 0.4279
Epoch 11/50
40000/40000 [==============================] - 58s - loss: 1.5544 - acc: 0.4460 - val_loss: 1.5763 - val_acc: 0.4399
Epoch 12/50
40000/40000 [==============================] - 59s - loss: 1.5336 - acc: 0.4516 - val_loss: 1.5574 - val_acc: 0.4531
Epoch 13/50
40000/40000 [==============================] - 58s - loss: 1.5191 - acc: 0.4582 - val_loss: 1.5664 - val_acc: 0.4397
Epoch 14/50
40000/40000 [==============================] - 58s - loss: 1.5061 - acc: 0.4629 - val_loss: 1.5430 - val_acc: 0.4527
Epoch 15/50
40000/40000 [==============================] - 58s - loss: 1.4881 - acc: 0.4736 - val_loss: 1.5108 - val_acc: 0.4761
Epoch 16/50
40000/40000 [==============================] - 58s - loss: 1.4710 - acc: 0.4826 - val_loss: 1.5264 - val_acc: 0.4654
Epoch 17/50
40000/40000 [==============================] - 58s - loss: 1.4623 - acc: 0.4808 - val_loss: 1.4949 - val_acc: 0.4735
Epoch 18/50
40000/40000 [==============================] - 58s - loss: 1.4508 - acc: 0.4870 - val_loss: 1.4993 - val_acc: 0.4742
Epoch 19/50
40000/40000 [==============================] - 58s - loss: 1.4353 - acc: 0.4939 - val_loss: 1.4758 - val_acc: 0.4857
Epoch 20/50
40000/40000 [==============================] - 58s - loss: 1.4252 - acc: 0.4981 - val_loss: 1.4725 - val_acc: 0.4853
Epoch 21/50
40000/40000 [==============================] - 58s - loss: 1.4169 - acc: 0.4993 - val_loss: 1.4519 - val_acc: 0.4919
Epoch 22/50
40000/40000 [==============================] - 58s - loss: 1.4182 - acc: 0.4997 - val_loss: 1.4362 - val_acc: 0.4996
Epoch 23/50
40000/40000 [==============================] - 59s - loss: 1.4033 - acc: 0.5061 - val_loss: 1.4364 - val_acc: 0.4987
Epoch 24/50
40000/40000 [==============================] - 61s - loss: 1.4015 - acc: 0.5076 - val_loss: 1.4303 - val_acc: 0.5013
Epoch 25/50
40000/40000 [==============================] - 61s - loss: 1.3950 - acc: 0.5079 - val_loss: 1.4382 - val_acc: 0.4997
Epoch 26/50
40000/40000 [==============================] - 58s - loss: 1.3874 - acc: 0.5096 - val_loss: 1.4255 - val_acc: 0.5002
Epoch 27/50
40000/40000 [==============================] - 59s - loss: 1.3830 - acc: 0.5139 - val_loss: 1.4426 - val_acc: 0.4969
Epoch 28/50
40000/40000 [==============================] - 59s - loss: 1.3807 - acc: 0.5147 - val_loss: 1.4312 - val_acc: 0.4994
Epoch 29/50
40000/40000 [==============================] - 62s - loss: 1.3766 - acc: 0.5155 - val_loss: 1.4146 - val_acc: 0.5094
Epoch 30/50
40000/40000 [==============================] - 60s - loss: 1.3649 - acc: 0.5209 - val_loss: 1.4093 - val_acc: 0.5063
Epoch 31/50
40000/40000 [==============================] - 63s - loss: 1.3646 - acc: 0.5207 - val_loss: 1.4117 - val_acc: 0.5067
Epoch 32/50
40000/40000 [==============================] - 63s - loss: 1.3644 - acc: 0.5182 - val_loss: 1.4104 - val_acc: 0.5048
Epoch 33/50
40000/40000 [==============================] - 62s - loss: 1.3544 - acc: 0.5250 - val_loss: 1.3976 - val_acc: 0.5073
Epoch 34/50
40000/40000 [==============================] - 64s - loss: 1.3509 - acc: 0.5276 - val_loss: 1.3896 - val_acc: 0.5173
Epoch 35/50
40000/40000 [==============================] - 60s - loss: 1.3533 - acc: 0.5231 - val_loss: 1.4325 - val_acc: 0.4945
Epoch 36/50
40000/40000 [==============================] - 63s - loss: 1.3461 - acc: 0.5269 - val_loss: 1.3903 - val_acc: 0.5200
Epoch 37/50
40000/40000 [==============================] - 60s - loss: 1.3377 - acc: 0.5300 - val_loss: 1.3968 - val_acc: 0.5131
Epoch 38/50
40000/40000 [==============================] - 59s - loss: 1.3381 - acc: 0.5302 - val_loss: 1.3849 - val_acc: 0.5160
Epoch 39/50
40000/40000 [==============================] - 59s - loss: 1.3356 - acc: 0.5302 - val_loss: 1.3857 - val_acc: 0.5087
Epoch 40/50
40000/40000 [==============================] - 60s - loss: 1.3366 - acc: 0.5303 - val_loss: 1.3922 - val_acc: 0.5116
Epoch 41/50
40000/40000 [==============================] - 59s - loss: 1.3314 - acc: 0.5315 - val_loss: 1.3912 - val_acc: 0.5116
Epoch 42/50
40000/40000 [==============================] - 59s - loss: 1.3278 - acc: 0.5339 - val_loss: 1.4101 - val_acc: 0.5100
Epoch 43/50
40000/40000 [==============================] - 59s - loss: 1.3251 - acc: 0.5359 - val_loss: 1.3829 - val_acc: 0.5162
Epoch 44/50
40000/40000 [==============================] - 60s - loss: 1.3159 - acc: 0.5391 - val_loss: 1.3689 - val_acc: 0.5189
Epoch 45/50
40000/40000 [==============================] - 60s - loss: 1.3235 - acc: 0.5372 - val_loss: 1.4281 - val_acc: 0.5072
Epoch 46/50
40000/40000 [==============================] - 60s - loss: 1.3163 - acc: 0.5367 - val_loss: 1.3705 - val_acc: 0.5195
Epoch 47/50
40000/40000 [==============================] - 60s - loss: 1.3175 - acc: 0.5363 - val_loss: 1.3690 - val_acc: 0.5140
Epoch 48/50
40000/40000 [==============================] - 60s - loss: 1.3076 - acc: 0.5428 - val_loss: 1.3679 - val_acc: 0.5229
Epoch 49/50
40000/40000 [==============================] - 60s - loss: 1.3141 - acc: 0.5420 - val_loss: 1.3507 - val_acc: 0.5284
Epoch 50/50
40000/40000 [==============================] - 62s - loss: 1.3068 - acc: 0.5423 - val_loss: 1.3581 - val_acc: 0.5271四、预测结果
预测函数的代码如下Pytest.py:
from tensorflow.contrib.keras.api.keras.models import load_model
from cifar_data_load import GetTestDataByLabel
import numpy as np
if __name__ == '__main__':
# 载入训练好的模型
model = load_model("lenet-no-activation-model.h5")
# 获取测试集的数据
X = GetTestDataByLabel('data')
Y = GetTestDataByLabel('labels')
# 统计预测正确的图片的数目
print(np.sum(np.equal(Y, np.argmax(model.predict(X), 1))))预测的结果如下:
5264在测试集的10000张图片中,预测正确的图片数目有5264张,正确率为52.64%。
五、总结
52.64%的正确率并不高,因为在网络结构中,未采用任何的优化措施。同时,由于LeNet原本是用于mnist手写数据集的分类问题,CIFAR-10较mnist数据集更为复杂,因此预测的正确率并不高。接下来的工作可以改进网络的能力,包括测试集的扩增,对网络结构进行优化,学习率的调整。可以发现,继续增加训练的epoch并无实际的意义。下一步计划采用更加优秀的AlexNet对CIFAR-10问题进行求解。
在统计上,也只是简单统计了预测正确的图片的数目,其他方面的参数在这里就未作统计。