Tesseract-OCR 字符识别技术
1 概述
OCR(Optical CharacterRecognition):光学字符识别,是指对图片文件中的文字进行分析识别,获取的过程。
Tesseract:开源的OCR识别引擎,初期Tesseract引擎由HP实验室研发,后来贡献给了开源软件业,后经由Google进行改进,消除bug,优化,重新发布。支持多语言(包括英文,简体中文,繁体中文),支持多平台(包括Windows,Linux,Mac OSX)。使用中Tesseract 的识别率非常高。
项目网站下载地址:
https://github.com/tesseract-ocr?utf8=%E2%9C%93&q=&type=&language=
2 Tesseract安装与应用
2.1 Tesseract下载和安装
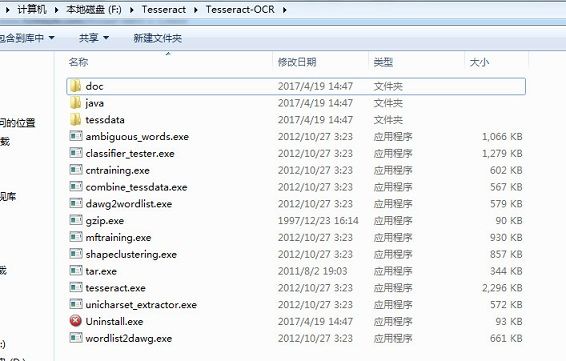
这里使用的版本为Tesseract3.02,下载windows下的安装文件tesseract-ocr-setup-3.02.02.exe。这里提供百度云链接:https://pan.baidu.com/s/1i53dR97,下载后安装tesseract-ocr-setup-3.02.02.exe。安装成功后会在相应磁盘上生成一个Tesseract-OCR目录。如图我是安装到了如下位置
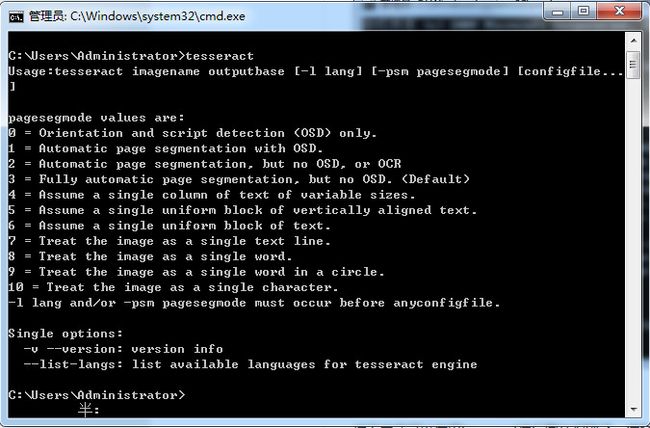
安装完成打开命令行,输入tesseract,展现如下图说明已经安装成功
2.2 命令行测试使用
接下来就可以使用tesseract进行图片识别了。准备一副待识别的图像,这里用画图工具随便写了一段字,然后定义成1.jpg

在命令行中定位到图片路径然后输入命令:
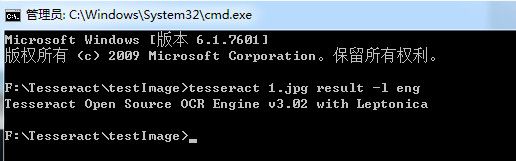
tesseract 1.jpg result -l eng
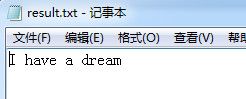
其中result表示输出结果文件txt名称,eng表示用以识别的语言文件为英文。会发现图片当前目录下生成了1个result.txt文件里面结果为
2.3 增加中文语言库
安装目录下的tessdata目录存放的是语言识别包,如果想增加中文识别功能,可以将中文的语言库放到此目录下,下载链接在下面地址:http://pan.baidu.com/s/1kVoMExx 下载后将解压出的chi_sim.traineddata放到此目录下。然后调用的时候指明语言库即可,例如:tesseract xxx.jpg result -l chi_sim照样,我们搞一个2.jpg图片,来测试下中文识别下的识别率怎么样。

执行后结果
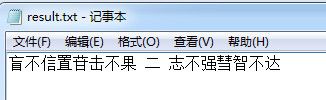
可以看到,识别率并不是十分令人满意。而且这边使用的例子都是十分正规的字体。如果遇到验证码那种不规则的字体,识别率也会大打折扣的。当然可以参考网上的相关资料进行对Tesseract字符识别进行样本训练,通过使用训练后的语言库会提高识别精度。这里就不做演示了。参考地址:http://blog.csdn.net/yasi_xi/article/details/8763385但是遗憾的是使用的工具jTessBoxEditor不支持中文训练。附带jTessBoxEditor1.0 下载地址:http://pan.baidu.com/s/1eSqYIo6
3 Tesseract在VS2013中的使用
上面是直接下载一个安装程序,会安装到电脑上,可以直接使用命令行来识别图片。但是你看不到源代码。另一个是下载源代码,自己进行编译,这样方便全面的去了解整个库的内容。Tesseract的编译过程比较复杂,有兴趣的可以自己编译,这里我分享一下编译好的库文件:
http://download.csdn.net/detail/davebobo/9820683
新建工程,添加包含目录、库目录、链接目录。
测试代码:
#include "stdafx.h"
#include
#include
int main()
{
char *outText;
tesseract::TessBaseAPI *api = new tesseract::TessBaseAPI();
// Initialize tesseract-ocr with English, without specifying tessdata path
if (api->Init(NULL, "eng")) {
fprintf(stderr, "Could not initialize tesseract.\n");
exit(1);
}
// Open input image with leptonica library
Pix *image = pixRead("image.jpg");
api->SetImage(image);
// Get OCR result
outText = api->GetUTF8Text();
printf("OCR output:\n%s", outText);
// Destroy used object and release memory
api->End();
delete[] outText;
pixDestroy(&image);
system("pause");
return 0;
} 测试图片:
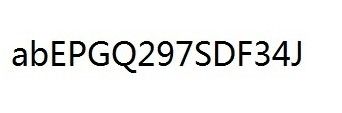
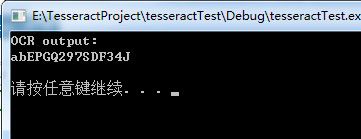
Reference:
http://www.52itstyle.com/thread-4803-1-1.html
http://blog.csdn.net/yongshi6/article/details/50616889
http://blog.csdn.net/fengbingchun/article/details/51628957
http://www.cnblogs.com/cnlian/p/5765871.html